A Comparative Analysis of Large Language Models for Code Documentation Generation
2312.10349
0
0
Abstract
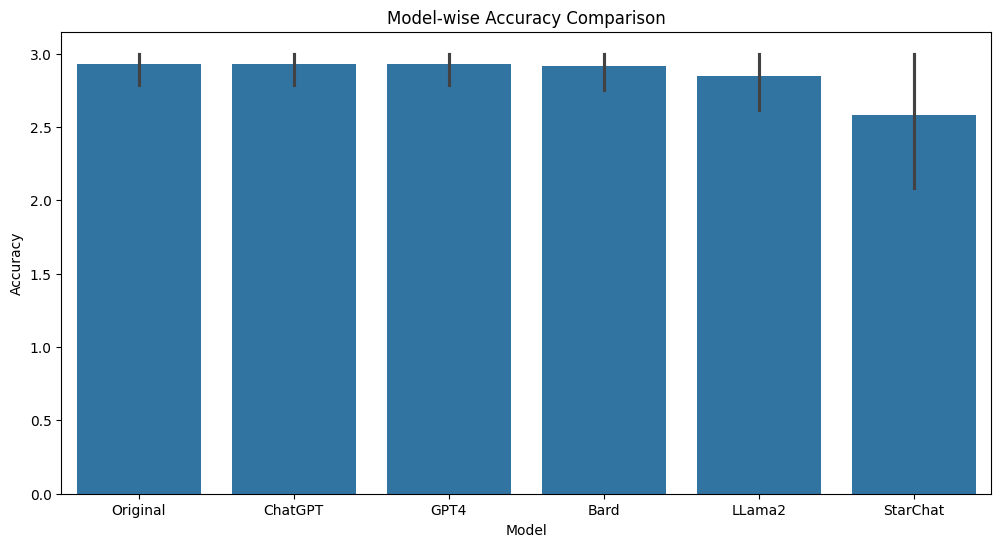
This paper presents a comprehensive comparative analysis of Large Language Models (LLMs) for generation of code documentation. Code documentation is an essential part of the software writing process. The paper evaluates models such as GPT-3.5, GPT-4, Bard, Llama2, and Starchat on various parameters like Accuracy, Completeness, Relevance, Understandability, Readability and Time Taken for different levels of code documentation. Our evaluation employs a checklist-based system to minimize subjectivity, providing a more objective assessment. We find that, barring Starchat, all LLMs consistently outperform the original documentation. Notably, closed-source models GPT-3.5, GPT-4, and Bard exhibit superior performance across various parameters compared to open-source/source-available LLMs, namely LLama 2 and StarChat. Considering the time taken for generation, GPT-4 demonstrated the longest duration, followed by Llama2, Bard, with ChatGPT and Starchat having comparable generation times. Additionally, file level documentation had a considerably worse performance across all parameters (except for time taken) as compared to inline and function level documentation.
Create account to get full access
Overview
- This paper presents a comparative analysis of large language models for generating code documentation.
- The researchers evaluated the performance of several state-of-the-art language models, including CodeBERT, GPT-3, and Codex, on code documentation generation tasks.
- The study aimed to provide insights into the strengths and limitations of these models for automating code documentation, a crucial task in software development.
Plain English Explanation
This research paper looks at how well different large language models can generate code documentation. Large language models are powerful AI systems that can understand and generate human-like text. The researchers tested several state-of-the-art models, including CodeBERT, GPT-3, and Codex, to see how well they can automatically write descriptions and explanations for computer code.
Generating good code documentation is an important part of software development, as it helps other developers understand and use the code. The researchers wanted to see if these advanced language models could take on this task, which is currently done manually by human developers. By evaluating the performance of these models, the researchers aimed to provide insights into the strengths and limitations of using AI to automate code documentation.
Technical Explanation
The researchers conducted a comparative analysis of several large language models for the task of code documentation generation. They evaluated the performance of CodeBERT, GPT-3, and Codex on a dataset of code snippets and their corresponding documentation.
The models were assessed on their ability to generate relevant and coherent documentation for the given code. The researchers used both automatic metrics, such as BLEU and METEOR scores, as well as human evaluation to measure the quality of the generated documentation.
The results showed that the performance of the large language models varied significantly, with some models performing better than others on specific aspects of the task. The researchers also found that the models had difficulty capturing the nuances and contextual information required for high-quality code documentation.
Critical Analysis
The paper provides a comprehensive evaluation of large language models for code documentation generation, but it also acknowledges several limitations and areas for further research. One key limitation is the relatively small size of the dataset used in the study, which may not capture the full diversity of code and documentation styles encountered in real-world software development.
Additionally, the paper does not delve deeply into the specific architectural differences and training approaches of the evaluated models, which could provide valuable insights into the factors that contribute to their performance. The researchers also note that the evaluation metrics used may not fully capture the complexity and subjective nature of code documentation quality.
Further research could explore the use of larger and more diverse datasets, as well as investigate novel model architectures or training techniques that might be better suited for the code documentation task. Additionally, incorporating user feedback and studying the real-world impact of AI-generated code documentation would be valuable next steps.
Conclusion
This paper presents a comparative analysis of large language models for the task of automated code documentation generation. The researchers evaluated the performance of several state-of-the-art models, including CodeBERT, GPT-3, and Codex, on a dataset of code snippets and their corresponding documentation.
The results provide valuable insights into the strengths and limitations of using large language models for this task, which has important implications for automating and improving code documentation in software development. While the models showed promising performance, the researchers also identified areas for further improvement, such as better capturing contextual information and nuances in code documentation.
Overall, this study serves as a valuable reference for researchers and practitioners interested in exploring the potential of AI-powered tools for enhancing software development workflows, particularly in the area of code documentation generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
0
0
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
5/31/2024

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
💬
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
0
0
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
5/24/2024

A Systematic Evaluation of Large Language Models for Natural Language Generation Tasks
Xuanfan Ni, Piji Li
0
0
Recent efforts have evaluated large language models (LLMs) in areas such as commonsense reasoning, mathematical reasoning, and code generation. However, to the best of our knowledge, no work has specifically investigated the performance of LLMs in natural language generation (NLG) tasks, a pivotal criterion for determining model excellence. Thus, this paper conducts a comprehensive evaluation of well-known and high-performing LLMs, namely ChatGPT, ChatGLM, T5-based models, LLaMA-based models, and Pythia-based models, in the context of NLG tasks. We select English and Chinese datasets encompassing Dialogue Generation and Text Summarization. Moreover, we propose a common evaluation setting that incorporates input templates and post-processing strategies. Our study reports both automatic results, accompanied by a detailed analysis.
5/17/2024