Analyzing the Performance of Large Language Models on Code Summarization
2404.08018
0
0
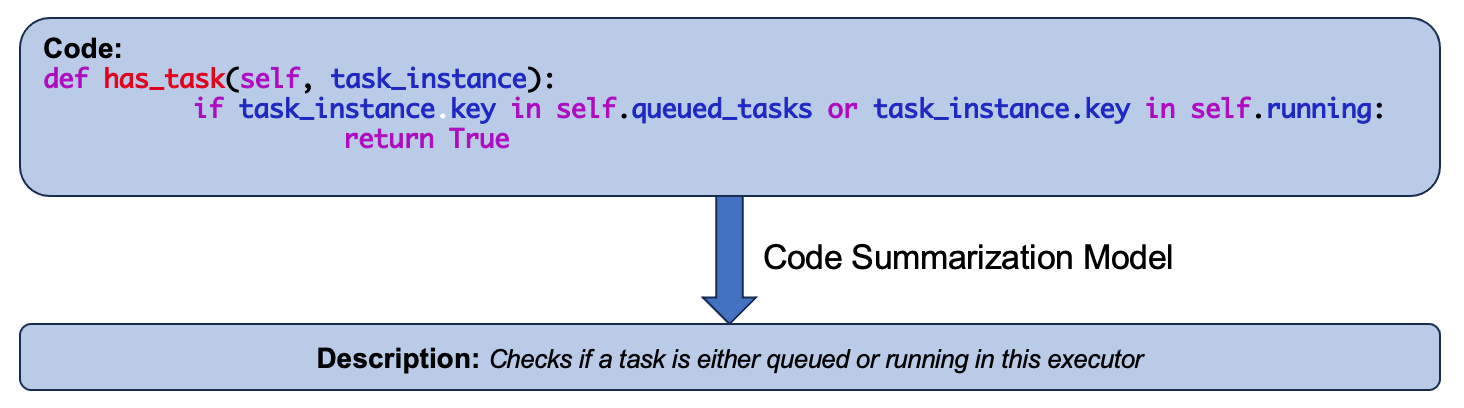
Abstract
Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines the performance of large language models (LLMs) on the task of code summarization
- Compares the effectiveness of different LLM approaches for generating concise and accurate summaries of code snippets
- Provides insights into the capabilities and limitations of LLMs in the context of code-related natural language processing
Plain English Explanation
This research paper investigates how well large language models (LLMs) - powerful AI systems trained on massive amounts of text data - can perform the task of code summarization. Code summarization involves taking a piece of computer code and generating a concise, natural language description that captures the key functionality of the code. This is an important task in software engineering, as it can help developers quickly understand and reason about unfamiliar code.
The researchers compare the performance of different LLM approaches on a dataset of code snippets and their corresponding human-written summaries. They examine factors such as the length and accuracy of the summaries generated by the LLMs, as well as their ability to capture the essential meaning of the code. The findings provide insights into the strengths and limitations of using LLMs for this type of code-related language processing task.
Overall, this research contributes to our understanding of how advanced AI systems can be leveraged to assist software developers and improve code comprehension and documentation. By exploring the capabilities and shortcomings of LLMs in the context of code summarization, the researchers help pave the way for more effective AI-powered tools and workflows in the field of software engineering.
Technical Explanation
The paper presents an empirical evaluation of the performance of large language models (LLMs) on the task of code summarization. The researchers compared the effectiveness of different LLM architectures, including Adapted Large Language Models Can Outperform Medical Experts on Clinician Note Understanding Tasks and Evaluating Context Learning in Libraries for Code Generation, in generating concise and accurate summaries of code snippets.
The study was conducted using a dataset of code samples and human-written summaries, which allowed the researchers to assess the LLMs' ability to capture the essential meaning and functionality of the code. Metrics such as summary length, ROUGE scores, and human evaluation were used to measure the performance of the different LLM approaches.
The findings suggest that LLMs can be effective at code summarization, but their performance is influenced by factors such as the specific model architecture, the quality and quantity of the training data, and the characteristics of the code being summarized. The researchers also identified areas where LLMs struggle, such as accurately capturing complex logical structures or rare edge cases in the code.
Critical Analysis
The paper provides a thorough and well-designed evaluation of LLMs for code summarization, but it also acknowledges several limitations and areas for further research. For example, the dataset used in the study may not be representative of the full diversity of code encountered in real-world software development, and the evaluation metrics may not fully capture all aspects of the summarization task.
Additionally, the paper does not explore the potential challenges of using LLMs in a production environment, such as the computational costs or the difficulty of interpreting and debugging the model's decision-making process. CodeEditorBench: Evaluating Code Editing Capability of Large Language Models highlights the importance of considering these practical concerns when applying LLMs to code-related tasks.
Further research could also investigate the potential for LLMs to be combined with other AI techniques, such as Testing the Effect of Code Documentation on the Performance of Large Language Models or Characterizing Multimodal Long-Form Summarization: A Case Study, to improve their performance and robustness in code summarization and other software engineering applications.
Conclusion
This research paper provides valuable insights into the capabilities and limitations of large language models (LLMs) for the task of code summarization. The findings suggest that LLMs can be effective at generating concise and accurate summaries of code, but their performance is influenced by various factors and they still struggle with certain aspects of the task.
The research contributes to our understanding of how advanced AI systems can be leveraged to assist software developers and improve code comprehension and documentation. By exploring the strengths and weaknesses of LLMs in the context of code summarization, the paper paves the way for the development of more effective AI-powered tools and workflows in the field of software engineering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Comparative Analysis of Large Language Models for Code Documentation Generation
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, Dhruv Kumar
0
0
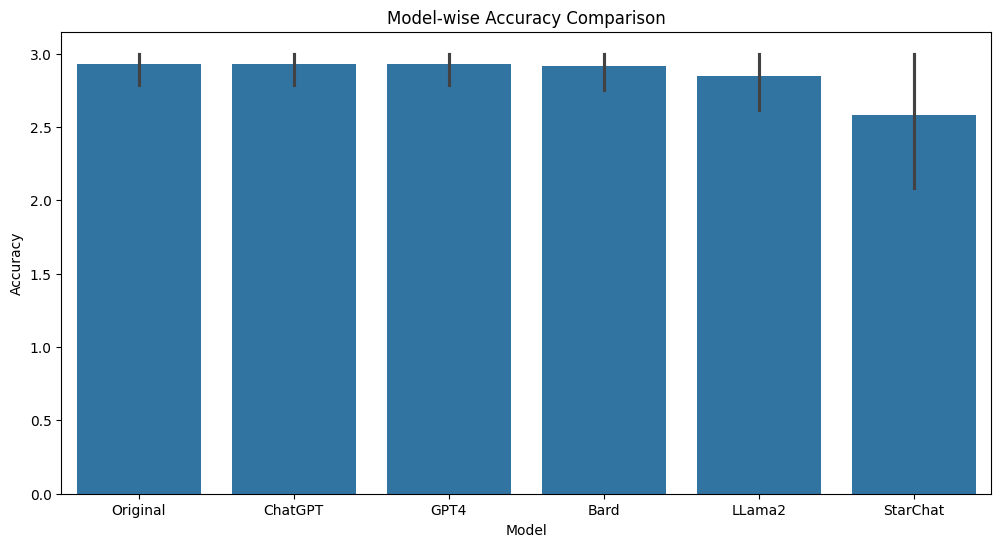
This paper presents a comprehensive comparative analysis of Large Language Models (LLMs) for generation of code documentation. Code documentation is an essential part of the software writing process. The paper evaluates models such as GPT-3.5, GPT-4, Bard, Llama2, and Starchat on various parameters like Accuracy, Completeness, Relevance, Understandability, Readability and Time Taken for different levels of code documentation. Our evaluation employs a checklist-based system to minimize subjectivity, providing a more objective assessment. We find that, barring Starchat, all LLMs consistently outperform the original documentation. Notably, closed-source models GPT-3.5, GPT-4, and Bard exhibit superior performance across various parameters compared to open-source/source-available LLMs, namely LLama 2 and StarChat. Considering the time taken for generation, GPT-4 demonstrated the longest duration, followed by Llama2, Bard, with ChatGPT and Starchat having comparable generation times. Additionally, file level documentation had a considerably worse performance across all parameters (except for time taken) as compared to inline and function level documentation.
4/30/2024
🔮
Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores
Yuvraj Virk, Premkumar Devanbu, Toufique Ahmed
0
0
A good summary can often be very useful during program comprehension. While a brief, fluent, and relevant summary can be helpful, it does require significant human effort to produce. Often, good summaries are unavailable in software projects, thus making maintenance more difficult. There has been a considerable body of research into automated AI-based methods, using Large Language models (LLMs), to generate summaries of code; there also has been quite a bit work on ways to measure the performance of such summarization methods, with special attention paid to how closely these AI-generated summaries resemble a summary a human might have produced. Measures such as BERTScore and BLEU have been suggested and evaluated with human-subject studies. However, LLMs often err and generate something quite unlike what a human might say. Given an LLM-produced code summary, is there a way to gauge whether it's likely to be sufficiently similar to a human produced summary, or not? In this paper, we study this question, as a calibration problem: given a summary from an LLM, can we compute a confidence measure, which is a good indication of whether the summary is sufficiently similar to what a human would have produced in this situation? We examine this question using several LLMs, for several languages, and in several different settings. We suggest an approach which provides well-calibrated predictions of likelihood of similarity to human summaries.
5/1/2024
💬
Can Large Language Models Write Parallel Code?
Daniel Nichols, Joshua H. Davis, Zhaojun Xie, Arjun Rajaram, Abhinav Bhatele
0
0
Large language models are increasingly becoming a popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for complex programs. In this paper, we study the capabilities of state-of-the-art language models to generate parallel code. In order to evaluate language models, we create a benchmark, ParEval, consisting of prompts that represent 420 different coding tasks related to scientific and parallel computing. We use ParEval to evaluate the effectiveness of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for evaluating the performance of generated code, and use them to explore how well each large language model performs for 12 different computational problem types and six different parallel programming models.
5/15/2024
➖
Performance-Aligned LLMs for Generating Fast Code
Daniel Nichols, Pranav Polasam, Harshitha Menon, Aniruddha Marathe, Todd Gamblin, Abhinav Bhatele
0
0
Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
4/30/2024