Expansive Synthesis: Generating Large-Scale Datasets from Minimal Samples
2406.17238
0
0

Abstract
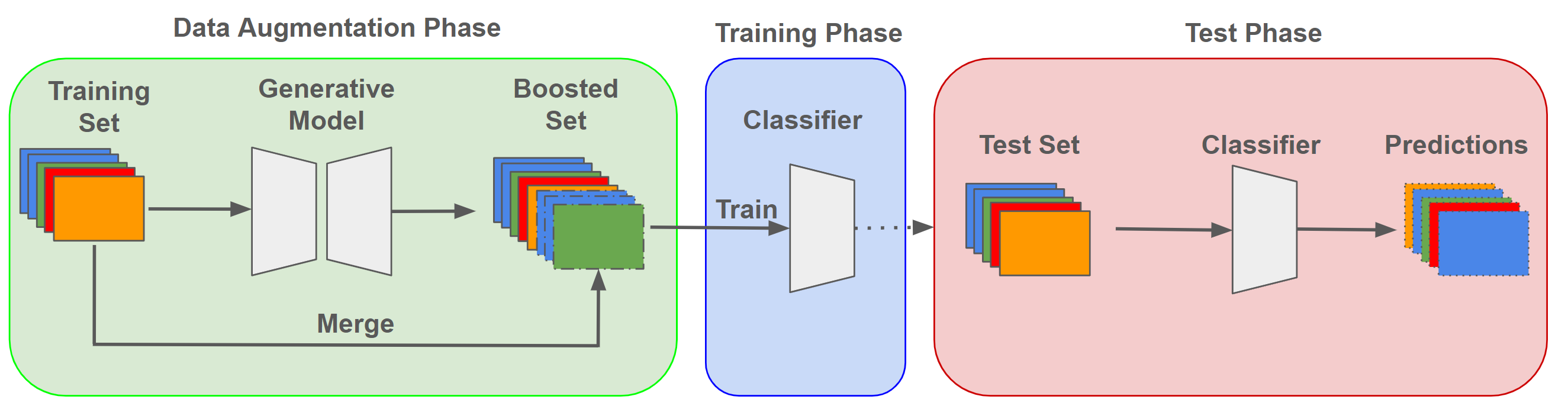
The challenge of limited availability of data for training in machine learning arises in many applications and the impact on performance and generalization is serious. Traditional data augmentation methods aim to enhance training with a moderately sufficient data set. Generative models like Generative Adversarial Networks (GANs) often face problematic convergence when generating significant and diverse data samples. Diffusion models, though effective, still struggle with high computational cost and long training times. This paper introduces an innovative Expansive Synthesis model that generates large-scale, high-fidelity datasets from minimal samples. The proposed approach exploits expander graph mappings and feature interpolation to synthesize expanded datasets while preserving the intrinsic data distribution and feature structural relationships. The rationale of the model is rooted in the non-linear property of neural networks' latent space and in its capture by a Koopman operator to yield a linear space of features to facilitate the construction of larger and enriched consistent datasets starting with a much smaller dataset. This process is optimized by an autoencoder architecture enhanced with self-attention layers and further refined for distributional consistency by optimal transport. We validate our Expansive Synthesis by training classifiers on the generated datasets and comparing their performance to classifiers trained on larger, original datasets. Experimental results demonstrate that classifiers trained on synthesized data achieve performance metrics on par with those trained on full-scale datasets, showcasing the model's potential to effectively augment training data. This work represents a significant advancement in data generation, offering a robust solution to data scarcity and paving the way for enhanced data availability in machine learning applications.
Create account to get full access
Overview
- This paper introduces "Expansive Synthesis," a novel approach to generating large-scale datasets from minimal samples.
- The key idea is to leverage diffusion models to synthesize diverse and realistic data samples that expand on a small initial dataset.
- The authors demonstrate the effectiveness of Expansive Synthesis across various domains, including images, text, and tabular data.
Plain English Explanation
Imagine you have a small collection of images, documents, or other data, and you want to create a much larger dataset to train machine learning models. Expansive Synthesis provides a way to do this automatically.
The core of the approach is using a type of AI model called a "diffusion model" to generate new samples that are similar to the original data. Diffusion models work by gradually adding noise to an image or other data, then learning how to reverse that process and generate new, realistic-looking samples.
By training a diffusion model on a small initial dataset, the researchers found they could then use that model to create a much larger, diverse dataset that captures the same underlying patterns and distributions as the original. This "expansive synthesis" allows machine learning researchers and practitioners to bootstrap their way to large-scale datasets, even when they only have access to a small amount of data to start with.
The team tested this approach across different domains, including images, text, and tabular data, demonstrating its versatility and effectiveness in expanding dataset size and diversity.
Technical Explanation
The core innovation of Expansive Synthesis is the use of diffusion models to generate large-scale datasets from minimal samples. Diffusion models work by gradually adding noise to input data, then learning how to reverse that process and generate new, realistic-looking samples.
The authors trained diffusion models on small initial datasets across various domains, including images, text, and tabular data. They then used these trained models to generate large numbers of synthetic samples that expanded on the original data, capturing the same underlying distributions and statistical patterns.
To evaluate the effectiveness of this approach, the researchers conducted experiments comparing models trained on the original small datasets versus the expanded datasets generated through Expansive Synthesis. They found that the expanded datasets consistently led to significant performance improvements, demonstrating the value of this data augmentation technique.
The authors also explored ways to further enhance the quality and utility of the generated datasets, such as pruning low-quality samples and iterative retraining of the diffusion models.
Critical Analysis
The authors present a compelling and well-executed approach to dataset expansion, with thorough experimentation and analysis to validate the effectiveness of Expansive Synthesis. However, the paper does not delve deeply into potential limitations or caveats of the method.
For example, the quality and diversity of the generated samples are likely to be highly dependent on the quality and diversity of the initial dataset. If the starting point is a biased or narrow dataset, the expanded version may simply amplify those biases. More research is needed to understand the limits of this approach and how to mitigate potential issues.
Additionally, the computational and memory requirements of training diffusion models could be a barrier to adoption, especially for resource-constrained practitioners. Exploring ways to make the Expansive Synthesis pipeline more efficient and scalable would be a valuable direction for future work.
Conclusion
Expansive Synthesis represents a significant advance in the field of dataset generation and augmentation. By leveraging diffusion models, the approach can create large-scale, diverse datasets from minimal initial samples, opening up new possibilities for machine learning research and applications.
The versatility of the method, as demonstrated across different data modalities, suggests it could have a broad impact in fields where data scarcity is a common challenge. As the authors continue to refine and explore the technique, it has the potential to become an essential tool in the machine learning practitioner's toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Distribution-Aware Data Expansion with Diffusion Models
Haowei Zhu, Ling Yang, Jun-Hai Yong, Hongzhi Yin, Jiawei Jiang, Meng Xiao, Wentao Zhang, Bin Wang
0
0
The scale and quality of a dataset significantly impact the performance of deep models. However, acquiring large-scale annotated datasets is both a costly and time-consuming endeavor. To address this challenge, dataset expansion technologies aim to automatically augment datasets, unlocking the full potential of deep models. Current data expansion techniques include image transformation and image synthesis methods. Transformation-based methods introduce only local variations, leading to limited diversity. In contrast, synthesis-based methods generate entirely new content, greatly enhancing informativeness. However, existing synthesis methods carry the risk of distribution deviations, potentially degrading model performance with out-of-distribution samples. In this paper, we propose DistDiff, a training-free data expansion framework based on the distribution-aware diffusion model. DistDiff constructs hierarchical prototypes to approximate the real data distribution, optimizing latent data points within diffusion models with hierarchical energy guidance. We demonstrate its capability to generate distribution-consistent samples, significantly improving data expansion tasks. DistDiff consistently enhances accuracy across a diverse range of datasets compared to models trained solely on original data. Furthermore, our approach consistently outperforms existing synthesis-based techniques and demonstrates compatibility with widely adopted transformation-based augmentation methods. Additionally, the expanded dataset exhibits robustness across various architectural frameworks. Our code is available at https://github.com/haoweiz23/DistDiff
6/6/2024

Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
Yunzhen Feng, Elvis Dohmatob, Pu Yang, Francois Charton, Julia Kempe
0
0
Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes. We illustrate our theoretical predictions on two practical problems: computing matrix eigenvalues with transformers and news summarization with large language models, which both undergo model collapse when trained on model-generated data. We show that training from feedback-augmented synthesized data, either by pruning incorrect predictions or by selecting the best of several guesses, can prevent model collapse, validating popular approaches like RLHF.
6/12/2024
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Qikai Yang, Panfeng Li, Xinhe Xu, Zhicheng Ding, Wenjing Zhou, Yi Nian
0
0
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
4/30/2024
📊
Enhancing Medical Imaging with GANs Synthesizing Realistic Images from Limited Data
Yinqiu Feng, Bo Zhang, Lingxi Xiao, Yutian Yang, Tana Gegen, Zexi Chen
0
0
In this research, we introduce an innovative method for synthesizing medical images using generative adversarial networks (GANs). Our proposed GANs method demonstrates the capability to produce realistic synthetic images even when trained on a limited quantity of real medical image data, showcasing commendable generalization prowess. To achieve this, we devised a generator and discriminator network architecture founded on deep convolutional neural networks (CNNs), leveraging the adversarial training paradigm for model optimization. Through extensive experimentation across diverse medical image datasets, our method exhibits robust performance, consistently generating synthetic images that closely emulate the structural and textural attributes of authentic medical images.
6/28/2024