An evaluation framework for synthetic data generation models
2404.08866
0
0
Abstract
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents an evaluation framework for assessing the quality of synthetic data generation models for tabular data.
- The framework covers key aspects such as utility, privacy, and fairness, providing a comprehensive approach to evaluating the strengths and limitations of these models.
- The authors also showcase the application of the framework on several popular synthetic data generation algorithms, offering valuable insights and best practices.
Plain English Explanation
Synthetic data generation models are a type of AI model that can create artificial data that closely resembles real-world data. This is useful in situations where the original data may be sensitive or difficult to obtain. However, it's important to ensure that the synthetic data is of high quality and doesn't introduce any biases or privacy issues.
This paper introduces an evaluation framework that helps assess the quality of synthetic data generation models. The framework looks at three key aspects: utility, privacy, and fairness.
Utility refers to how well the synthetic data can be used in place of the original data for tasks like training machine learning models. Privacy looks at whether the synthetic data protects the privacy of individuals in the original dataset. And fairness examines whether the synthetic data accurately represents different demographic groups without introducing biases.
By evaluating synthetic data generation models across these dimensions, the framework provides a comprehensive way to understand the strengths and limitations of these models. The authors also demonstrate the application of the framework on several popular synthetic data generation algorithms, sharing best practices and lessons learned that can help guide the development and use of these models.
Technical Explanation
The paper introduces a structured evaluation framework for assessing the quality of synthetic data generation models for tabular data. The framework covers three key aspects:
-
Utility: This evaluates how well the synthetic data can be used as a substitute for the original data. Metrics like prediction accuracy, data utility, and task-specific performance are used to assess the utility of the synthetic data.
-
Privacy: The framework analyzes the privacy preservation capabilities of the synthetic data generation model. This includes evaluating membership inference attacks, model inversion attacks, and other privacy risk metrics.
-
Fairness: Fairness is assessed by examining whether the synthetic data accurately represents different demographic groups without introducing biases. Metrics like demographic parity, equal opportunity, and equalized odds are used for this purpose.
The authors demonstrate the application of this evaluation framework on several popular synthetic data generation algorithms, including CTGAN, TVAE, and Synthetic Data Vault. Through this analysis, they provide best practices and lessons learned for developing and deploying synthetic data generation models.
Critical Analysis
The evaluation framework presented in this paper provides a comprehensive and structured approach to assessing the quality of synthetic data generation models. By considering utility, privacy, and fairness, it addresses key concerns that are often overlooked when working with synthetic data.
That said, the paper acknowledges that the framework is not exhaustive, and there may be other important aspects to consider, such as the transferability of synthetic data for transfer learning or the ability to generate realistic and diverse synthetic data. Additionally, the evaluation metrics used in the framework may not capture all nuances of these complex concepts, and further research may be needed to develop more robust and comprehensive evaluation methods.
Overall, this paper offers a valuable contribution to the field of synthetic data generation, providing a practical tool for researchers and practitioners to critically evaluate the quality of their models. By encouraging a more rigorous and holistic approach to model evaluation, the authors help pave the way for the responsible development and deployment of these increasingly important AI-powered data generation techniques.
Conclusion
This paper presents a comprehensive evaluation framework for assessing the quality of synthetic data generation models for tabular data. By considering utility, privacy, and fairness, the framework provides a structured approach to evaluating the strengths and limitations of these models.
The authors demonstrate the application of the framework on several popular synthetic data generation algorithms, offering best practices and lessons learned that can guide the development and deployment of these models. The insights gained from this research can help ensure that synthetic data is used responsibly and effectively, ultimately contributing to the advancement of AI-powered data generation techniques that benefit both researchers and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
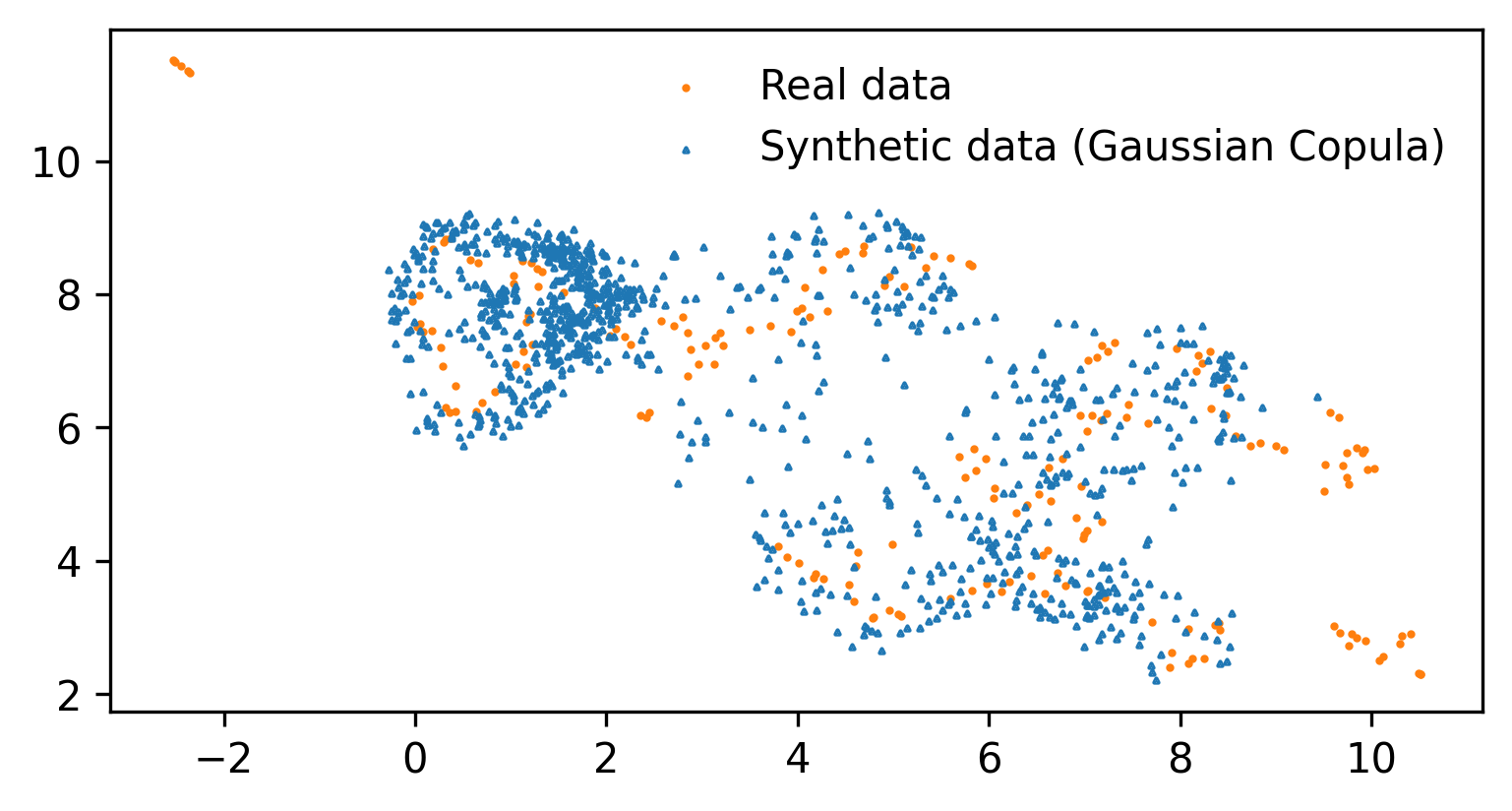
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
Structured Evaluation of Synthetic Tabular Data
Scott Cheng-Hsin Yang, Baxter Eaves, Michael Schmidt, Ken Swanson, Patrick Shafto
0
0
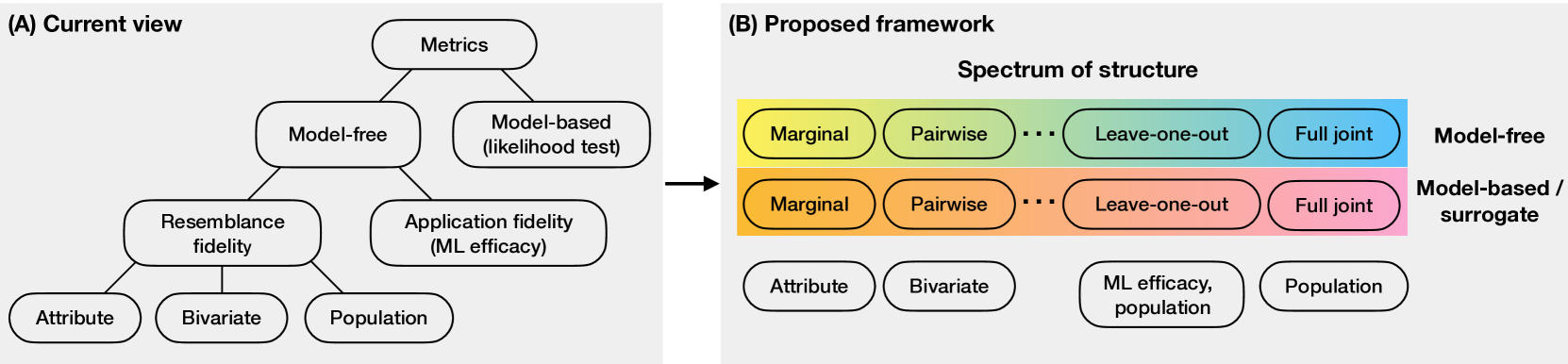
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
4/1/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024

Permissioned Blockchain-based Framework for Ranking Synthetic Data Generators
Narasimha Raghavan Veeraragavan, Mohammad Hossein Tabatabaei, Severin Elvatun, Vibeke Binz Vallevik, Siri Lar{o}nningen, Jan F Nyg{aa}rd
0
0
Synthetic data generation is increasingly recognized as a crucial solution to address data related challenges such as scarcity, bias, and privacy concerns. As synthetic data proliferates, the need for a robust evaluation framework to select a synthetic data generator becomes more pressing given the variety of options available. In this research study, we investigate two primary questions: 1) How can we select the most suitable synthetic data generator from a set of options for a specific purpose? 2) How can we make the selection process more transparent, accountable, and auditable? To address these questions, we introduce a novel approach in which the proposed ranking algorithm is implemented as a smart contract within a permissioned blockchain framework called Sawtooth. Through comprehensive experiments and comparisons with state-of-the-art baseline ranking solutions, our framework demonstrates its effectiveness in providing nuanced rankings that consider both desirable and undesirable properties. Furthermore, our framework serves as a valuable tool for selecting the optimal synthetic data generators for specific needs while ensuring compliance with data protection principles.
5/14/2024