Compass: Large Multilingual Language Model for South-east Asia
2404.09220
0
0

Abstract
Large language models have exhibited significant proficiency in languages endowed with extensive linguistic resources, such as English and Chinese. Nevertheless, their effectiveness notably diminishes when applied to languages characterized by limited linguistic resources, particularly within the Southeast Asian linguistic landscape, such as Indonesian. The scarcity of linguistic resources for these languages presents challenges associated with inadequate training, restricted vocabulary coverage, and challenging evaluation processes. In response to these exigencies, we have introduced CompassLLM, a large multilingual model specifically tailored for Southeast Asian languages, with the primary aim of supporting the developmental requirements of Shopee. Our methodology encompasses several key strategies. To progressively enhance multilingual proficiencies, we implemented a multi-stage pre-training strategy integrated with curriculum learning, gradually intensifying the focus on low-resource languages. Concurrently, to better accommodate low-resource human instructions, we curated and generated a repository of high-quality multilingual human instructions, culminating the CompassLLM-SFT model through supervised instruction fine-tuning. Finally, to reinforce the model's alignment with human preference behaviors, we have embraced the principle of Direct Preference Optimization (DPO) to obtain CompassLLM-DPO model. Preliminary evaluation of the CompassLLM model yields promising results, with our model surpassing benchmark models like Vicuna-7b-v1.5, Sealion, Falcon and SeaLLM, across diverse evaluation tasks, as verified through both automated and human-driven assessments. Notably, our model exhibits its superior performance in South-east Asia languages, such as Indonesian language.
Create account to get full access
Overview
- This paper introduces Compass, a large multilingual language model for South-east Asia.
- Compass is trained on a diverse corpus of text data from various languages and domains in the South-east Asian region.
- The model aims to serve as a powerful foundation for a wide range of natural language processing tasks in the region.
Plain English Explanation
Compass is a new artificial intelligence (AI) model that has been trained on a large amount of text data from countries in South-east Asia. This includes text written in many different languages that are commonly used in the region, such as Malay, Indonesian, Thai, Vietnamese, and more.
The goal of Compass is to create a powerful AI system that can understand and generate human language across these various South-east Asian languages. This could be useful for all kinds of applications, like building better language translation tools, improving voice assistants, or helping machines better comprehend text written in these languages.
By training Compass on such a diverse set of data, the researchers hope to create an AI model that has a deep understanding of the cultures, dialects, and nuances of language use across South-east Asia. This could make it a valuable tool for businesses, researchers, and developers working in the region.
Technical Explanation
The Compass paper describes the process of pretraining this large multilingual language model. The researchers collected a massive dataset of text from the internet, books, and other sources in over 20 different languages commonly used in South-east Asia.
This data was then used to train Compass using a variant of the popular Transformer architecture, which is a type of neural network well-suited for understanding and generating human language. The model was trained using self-supervised learning, meaning it learned to predict missing words in the text, rather than being explicitly programmed with linguistic rules.
The resulting Compass model has over 10 billion parameters, making it one of the largest language models ever created for the South-east Asian region. Tests show it achieves state-of-the-art performance on a variety of natural language tasks in these languages, outperforming previous multilingual models like SAILOR and Chinese Tiny LLM.
Critical Analysis
The Compass paper provides a thorough description of the model's pretraining process and demonstrates its strong performance on benchmarks. However, the authors acknowledge some limitations:
- The dataset, while large, may still not fully capture the diversity of languages, dialects, and text genres in South-east Asia. There could be biases or gaps in the training data.
- The model was trained using general-purpose self-supervised learning, rather than fine-tuning on specific downstream tasks. This may limit its capabilities on certain applications.
- The computational and energy requirements for training such a large model are substantial, which could pose challenges for real-world deployment, especially in resource-constrained settings.
Additionally, it would be valuable to see more analysis on how Compass handles code-switching, colloquialisms, and other linguistic phenomena common in multilingual South-east Asian contexts. Further research could also explore ways to make the model more efficient or adapt it to low-resource languages in the region.
Conclusion
Overall, the Compass model represents an important advance in building large-scale multilingual AI systems tailored for South-east Asia. By leveraging a diverse dataset and powerful neural network architecture, the researchers have created a foundation that could enable a wide range of natural language applications to better serve the linguistically diverse populations of the region. As AI continues to play a growing role in our lives, efforts like Compass will be crucial for ensuring these technologies are accessible and beneficial to all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
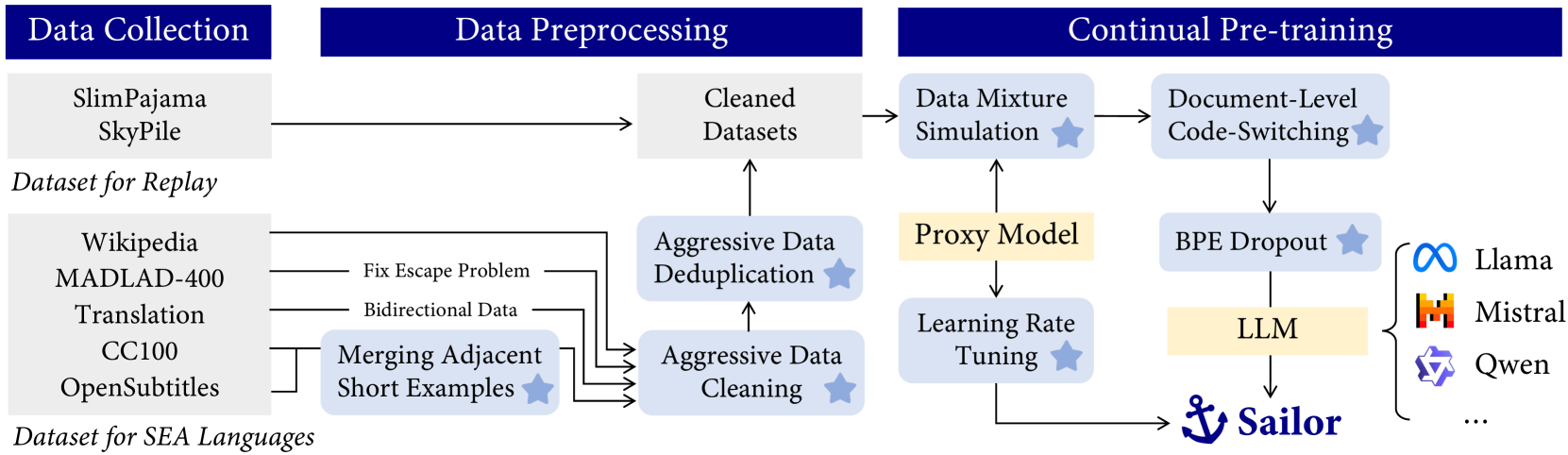
Sailor: Open Language Models for South-East Asia
Longxu Dou, Qian Liu, Guangtao Zeng, Jia Guo, Jiahui Zhou, Wei Lu, Min Lin
0
0
We present Sailor, a family of open language models ranging from 0.5B to 7B parameters, tailored for South-East Asian (SEA) languages. These models are continually pre-trained from Qwen1.5, a great language model for multilingual use cases. From Qwen1.5, Sailor models accept 200B to 400B tokens, primarily covering the languages of English, Chinese, Vietnamese, Thai, Indonesian, Malay, and Lao. The training leverages several techniques, including BPE dropout for improving the model robustness, aggressive data cleaning and deduplication, and small proxy models to optimize data mixture. Experimental results on four typical tasks indicate that Sailor models demonstrate strong performance across different benchmarks, including commonsense reasoning, question answering, reading comprehension and examination. Embracing the open-source spirit, we share our insights through this report to spark a wider interest in developing large language models for multilingual use cases.
4/5/2024
💬
Crossing Linguistic Horizons: Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
Sang T. Truong, Duc Q. Nguyen, Toan Nguyen, Dong D. Le, Nhi N. Truong, Tho Quan, Sanmi Koyejo
0
0
Recent advancements in large language models (LLMs) have underscored their importance in the evolution of artificial intelligence. However, despite extensive pretraining on multilingual datasets, available open-sourced LLMs exhibit limited effectiveness in processing Vietnamese. The challenge is exacerbated by the absence of systematic benchmark datasets and metrics tailored for Vietnamese LLM evaluation. To mitigate these issues, we have finetuned LLMs specifically for Vietnamese and developed a comprehensive evaluation framework encompassing 10 common tasks and 31 metrics. Our evaluation results reveal that the fine-tuned LLMs exhibit enhanced comprehension and generative capabilities in Vietnamese. Moreover, our analysis indicates that models with more parameters can introduce more biases and uncalibrated outputs and the key factor influencing LLM performance is the quality of the training or fine-tuning datasets. These insights underscore the significance of meticulous fine-tuning with high-quality datasets in enhancing LLM performance.
5/28/2024
💬
EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation
Atnafu Lambebo Tonja, Israel Abebe Azime, Tadesse Destaw Belay, Mesay Gemeda Yigezu, Moges Ahmed Mehamed, Abinew Ali Ayele, Ebrahim Chekol Jibril, Michael Melese Woldeyohannis, Olga Kolesnikova, Philipp Slusallek, Dietrich Klakow, Shengwu Xiong, Seid Muhie Yimam
0
0
Large language models (LLMs) have gained popularity recently due to their outstanding performance in various downstream Natural Language Processing (NLP) tasks. However, low-resource languages are still lagging behind current state-of-the-art (SOTA) developments in the field of NLP due to insufficient resources to train LLMs. Ethiopian languages exhibit remarkable linguistic diversity, encompassing a wide array of scripts, and are imbued with profound religious and cultural significance. This paper introduces EthioLLM -- multilingual large language models for five Ethiopian languages (Amharic, Ge'ez, Afan Oromo, Somali, and Tigrinya) and English, and Ethiobenchmark -- a new benchmark dataset for various downstream NLP tasks. We evaluate the performance of these models across five downstream NLP tasks. We open-source our multilingual language models, new benchmark datasets for various downstream tasks, and task-specific fine-tuned language models and discuss the performance of the models. Our dataset and models are available at the https://huggingface.co/EthioNLP repository.
6/26/2024
💬
Bridging the Bosphorus: Advancing Turkish Large Language Models through Strategies for Low-Resource Language Adaptation and Benchmarking
Emre Can Acikgoz, Mete Erdogan, Deniz Yuret
0
0
Large Language Models (LLMs) are becoming crucial across various fields, emphasizing the urgency for high-quality models in underrepresented languages. This study explores the unique challenges faced by low-resource languages, such as data scarcity, model selection, evaluation, and computational limitations, with a special focus on Turkish. We conduct an in-depth analysis to evaluate the impact of training strategies, model choices, and data availability on the performance of LLMs designed for underrepresented languages. Our approach includes two methodologies: (i) adapting existing LLMs originally pretrained in English to understand Turkish, and (ii) developing a model from the ground up using Turkish pretraining data, both supplemented with supervised fine-tuning on a novel Turkish instruction-tuning dataset aimed at enhancing reasoning capabilities. The relative performance of these methods is evaluated through the creation of a new leaderboard for Turkish LLMs, featuring benchmarks that assess different reasoning and knowledge skills. Furthermore, we conducted experiments on data and model scaling, both during pretraining and fine-tuning, simultaneously emphasizing the capacity for knowledge transfer across languages and addressing the challenges of catastrophic forgetting encountered during fine-tuning on a different language. Our goal is to offer a detailed guide for advancing the LLM framework in low-resource linguistic contexts, thereby making natural language processing (NLP) benefits more globally accessible.
5/9/2024