Sailor: Open Language Models for South-East Asia
2404.03608
0
0
Abstract
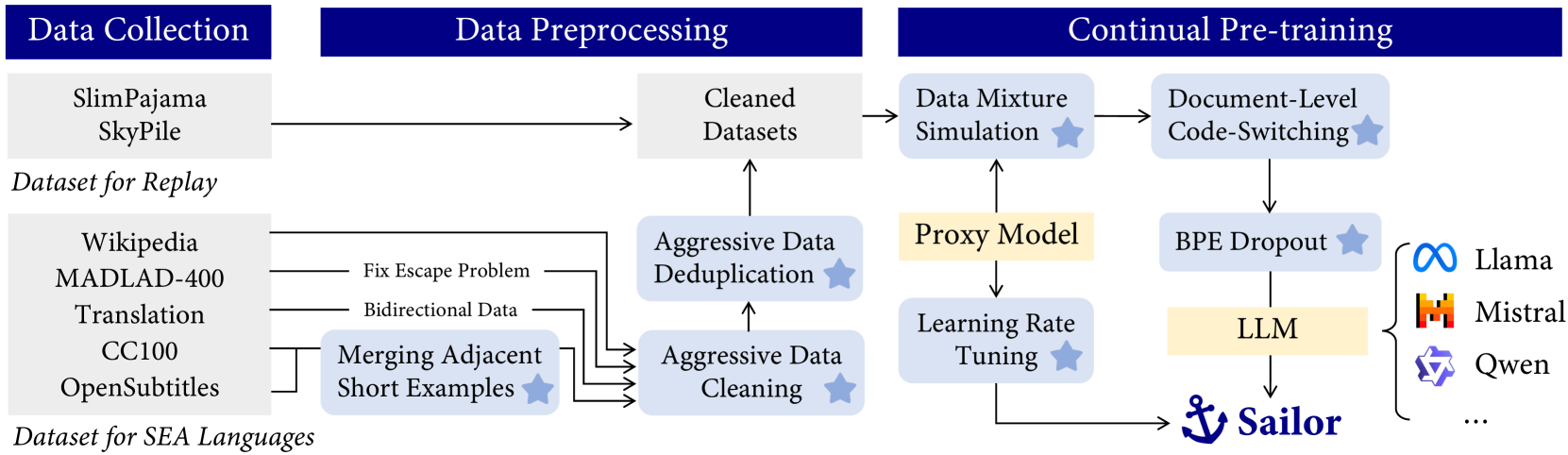
We present Sailor, a family of open language models ranging from 0.5B to 7B parameters, tailored for South-East Asian (SEA) languages. These models are continually pre-trained from Qwen1.5, a great language model for multilingual use cases. From Qwen1.5, Sailor models accept 200B to 400B tokens, primarily covering the languages of English, Chinese, Vietnamese, Thai, Indonesian, Malay, and Lao. The training leverages several techniques, including BPE dropout for improving the model robustness, aggressive data cleaning and deduplication, and small proxy models to optimize data mixture. Experimental results on four typical tasks indicate that Sailor models demonstrate strong performance across different benchmarks, including commonsense reasoning, question answering, reading comprehension and examination. Embracing the open-source spirit, we share our insights through this report to spark a wider interest in developing large language models for multilingual use cases.
Create account to get full access
Overview
- This paper introduces Sailor, a set of open-source language models designed for South-East Asian languages.
- The models are trained on a diverse dataset of text from various sources, including websites, books, and social media.
- The goal is to create language models that can better understand and generate text in South-East Asian languages, which have been underserved by existing large language models.
Plain English Explanation
Language models are artificial intelligence systems that are trained on vast amounts of text data to learn the patterns and structure of a language. These models can then be used to generate human-like text, translate between languages, and perform other language-related tasks.
However, most of the existing large language models have been trained primarily on text data from English and other Western languages. This means they often struggle with understanding and producing text in other languages, especially those that use different writing systems or have unique grammatical structures.
The Sailor project aims to address this issue by creating open-source language models specifically for South-East Asian languages, such as Bahasa Indonesian, Thai, and Vietnamese. The researchers have collected a diverse dataset of text from various sources, including websites, books, and social media, to train these models.
By focusing on South-East Asian languages, the Sailor models are expected to better understand the nuances and complexities of these languages, leading to improved performance on a wide range of language-related tasks. This could have significant implications for industries and applications that rely on natural language processing, such as machine translation, chatbots, and content generation.
Technical Explanation
The Sailor project involves the development of a suite of open-source language models for South-East Asian languages. The researchers have compiled a large and diverse dataset of text from various sources, including websites, books, and social media, to train these models.
The dataset covers a wide range of topics and genres, including news articles, social media posts, and literary works, to ensure that the models can handle the diverse language use found in real-world applications. The researchers have also taken steps to address potential biases and imbalances in the dataset, such as ensuring that the data includes content from diverse perspectives and backgrounds.
The Sailor models are built using state-of-the-art neural network architectures, similar to those used in large language models like BERT and GPT-3. The models are trained using a combination of unsupervised and supervised learning techniques, with the goal of not only capturing the general patterns and structure of the languages but also developing specialized capabilities for tasks like machine translation, text summarization, and dialogue generation.
The key insights from this research include the importance of developing language models that are tailored to the unique characteristics of under-represented languages, the benefits of using diverse and representative datasets, and the potential for open-source language models to democratize access to advanced natural language processing capabilities in various regions and communities.
Critical Analysis
The Sailor project represents an important step towards addressing the imbalance in the development of large language models, which have historically been dominated by a few major languages, primarily English. By focusing on South-East Asian languages, the researchers are expanding the reach and applicability of these powerful AI systems to a diverse and underserved region.
However, it's important to note that the success of these models will ultimately depend on their real-world performance and their ability to generalize to a wide range of tasks and applications. The researchers acknowledge that further evaluation and testing will be necessary to fully assess the capabilities and limitations of the Sailor models.
Additionally, while the use of diverse datasets is a commendable approach, there may still be challenges in ensuring that the models capture the nuances and regional variations within South-East Asian languages. Ongoing monitoring and iterative refinement of the models will be crucial to address these potential issues.
Another area for further research is the potential societal implications of these language models, particularly in terms of their impact on language preservation, digital inclusion, and the democratization of access to advanced natural language processing capabilities. The researchers may want to consider exploring these aspects in greater depth.
Conclusion
The Sailor project represents a significant contribution to the development of open-source language models for South-East Asian languages. By creating models that are specifically tailored to the unique characteristics of these languages, the researchers are laying the groundwork for improved natural language processing capabilities in a region that has historically been underserved by large language models.
The insights and methodologies presented in this research have the potential to inform the development of similar initiatives for other under-represented languages, ultimately leading to a more inclusive and equitable landscape for natural language processing technologies. As these models are further evaluated and refined, they could have a transformative impact on a wide range of industries and applications that rely on advanced language understanding and generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Holy Lovenia, Rahmad Mahendra, Salsabil Maulana Akbar, Lester James V. Miranda, Jennifer Santoso, Elyanah Aco, Akhdan Fadhilah, Jonibek Mansurov, Joseph Marvin Imperial, Onno P. Kampman, Joel Ruben Antony Moniz, Muhammad Ravi Shulthan Habibi, Frederikus Hudi, Railey Montalan, Ryan Ignatius, Joanito Agili Lopo, William Nixon, Borje F. Karlsson, James Jaya, Ryandito Diandaru, Yuze Gao, Patrick Amadeus, Bin Wang, Jan Christian Blaise Cruz, Chenxi Whitehouse, Ivan Halim Parmonangan, Maria Khelli, Wenyu Zhang, Lucky Susanto, Reynard Adha Ryanda, Sonny Lazuardi Hermawan, Dan John Velasco, Muhammad Dehan Al Kautsar, Willy Fitra Hendria, Yasmin Moslem, Noah Flynn, Muhammad Farid Adilazuarda, Haochen Li, Johanes Lee, R. Damanhuri, Shuo Sun, Muhammad Reza Qorib, Amirbek Djanibekov, Wei Qi Leong, Quyet V. Do, Niklas Muennighoff, Tanrada Pansuwan, Ilham Firdausi Putra, Yan Xu, Ngee Chia Tai, Ayu Purwarianti, Sebastian Ruder, William Tjhi, Peerat Limkonchotiwat, Alham Fikri Aji, Sedrick Keh, Genta Indra Winata, Ruochen Zhang, Fajri Koto, Zheng-Xin Yong, Samuel Cahyawijaya
0
0
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
6/17/2024

Compass: Large Multilingual Language Model for South-east Asia
Sophia Maria
0
0
Large language models have exhibited significant proficiency in languages endowed with extensive linguistic resources, such as English and Chinese. Nevertheless, their effectiveness notably diminishes when applied to languages characterized by limited linguistic resources, particularly within the Southeast Asian linguistic landscape, such as Indonesian. The scarcity of linguistic resources for these languages presents challenges associated with inadequate training, restricted vocabulary coverage, and challenging evaluation processes. In response to these exigencies, we have introduced CompassLLM, a large multilingual model specifically tailored for Southeast Asian languages, with the primary aim of supporting the developmental requirements of Shopee. Our methodology encompasses several key strategies. To progressively enhance multilingual proficiencies, we implemented a multi-stage pre-training strategy integrated with curriculum learning, gradually intensifying the focus on low-resource languages. Concurrently, to better accommodate low-resource human instructions, we curated and generated a repository of high-quality multilingual human instructions, culminating the CompassLLM-SFT model through supervised instruction fine-tuning. Finally, to reinforce the model's alignment with human preference behaviors, we have embraced the principle of Direct Preference Optimization (DPO) to obtain CompassLLM-DPO model. Preliminary evaluation of the CompassLLM model yields promising results, with our model surpassing benchmark models like Vicuna-7b-v1.5, Sealion, Falcon and SeaLLM, across diverse evaluation tasks, as verified through both automated and human-driven assessments. Notably, our model exhibits its superior performance in South-east Asia languages, such as Indonesian language.
4/16/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Taishi Nakamura, Mayank Mishra, Simone Tedeschi, Yekun Chai, Jason T Stillerman, Felix Friedrich, Prateek Yadav, Tanmay Laud, Vu Minh Chien, Terry Yue Zhuo, Diganta Misra, Ben Bogin, Xuan-Son Vu, Marzena Karpinska, Arnav Varma Dantuluri, Wojciech Kusa, Tommaso Furlanello, Rio Yokota, Niklas Muennighoff, Suhas Pai, Tosin Adewumi, Veronika Laippala, Xiaozhe Yao, Adalberto Junior, Alpay Ariyak, Aleksandr Drozd, Jordan Clive, Kshitij Gupta, Liangyu Chen, Qi Sun, Ken Tsui, Noah Persaud, Nour Fahmy, Tianlong Chen, Mohit Bansal, Nicolo Monti, Tai Dang, Ziyang Luo, Tien-Tung Bui, Roberto Navigli, Virendra Mehta, Matthew Blumberg, Victor May, Huu Nguyen, Sampo Pyysalo
0
0
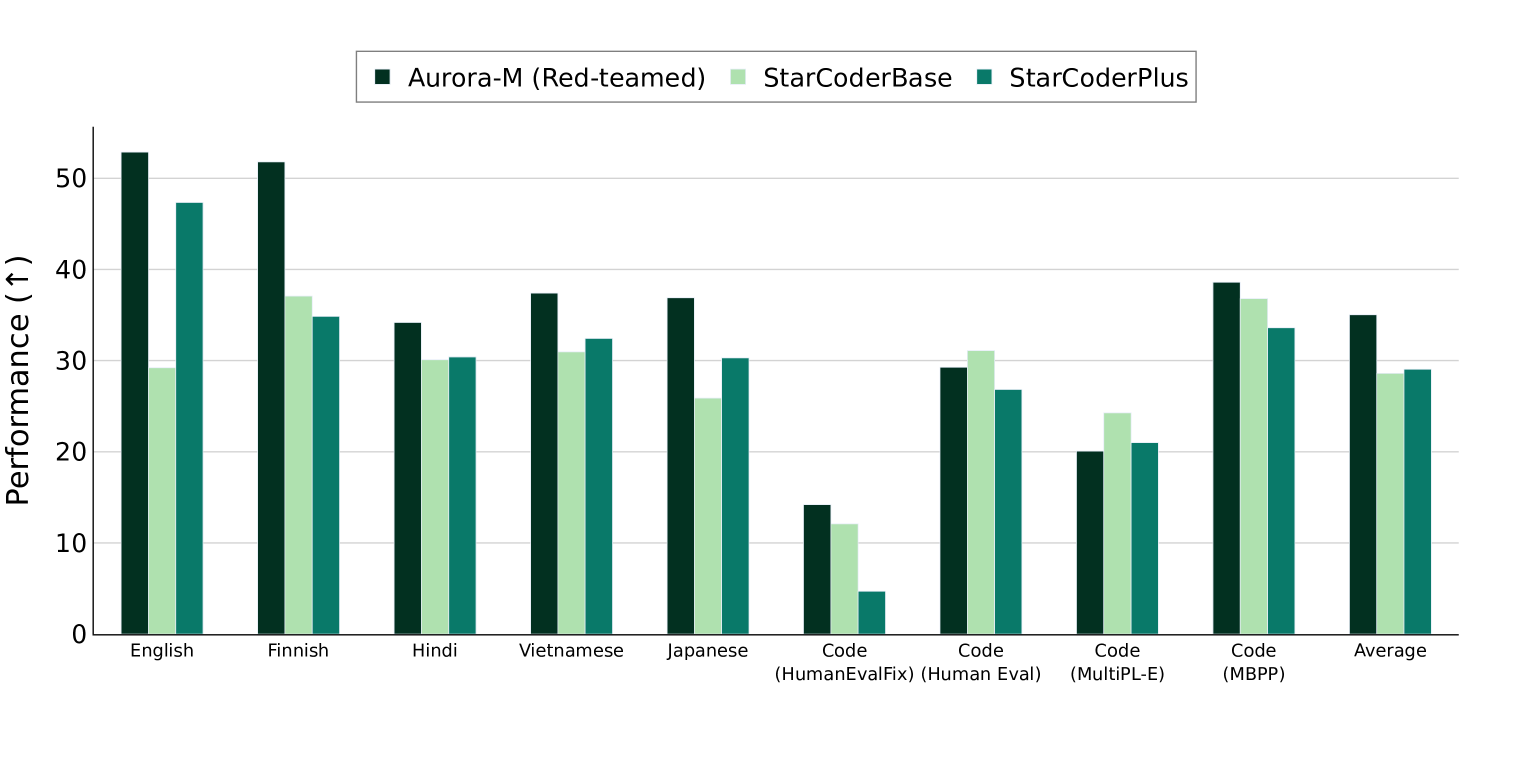
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
4/24/2024