A Competitive Algorithm for Agnostic Active Learning

0
🔍
Sign in to get full access
Overview
- Active agnostic learning can require exponentially fewer samples than passive learning for some hypothesis classes and input distributions, but offer little to no improvement for others.
- The most popular algorithms for agnostic active learning rely on a parameter called the disagreement coefficient, but can be inefficient on certain inputs.
- This paper presents a new algorithm for agnostic active learning that is competitive with the optimal algorithm for any binary hypothesis class and distribution.
Plain English Explanation
In machine learning, there are two main approaches to training models: active learning and passive learning. In passive learning, the model is trained on a fixed dataset. In active learning, the model can actively choose which data samples to learn from.
For some types of machine learning problems and data, active learning can be much more efficient than passive learning. It may only need a fraction of the samples to achieve the same level of accuracy. However, this isn't always the case - for other problems and data, active learning offers little or no advantage.
The most common algorithms for a type of active learning called "agnostic active learning" rely on a mathematical parameter called the "disagreement coefficient." But these algorithms can perform poorly on certain types of inputs.
This paper introduces a new algorithm for agnostic active learning that is competitive with the best possible algorithm for any binary classification problem and dataset. Specifically, if the optimal algorithm can achieve a certain error rate using m* samples, this new algorithm can achieve the same error rate using only O(m* log |H|) samples, where |H| is the size of the hypothesis class (the set of possible models).
The paper also shows that it's computationally hard to do significantly better than this O(log |H|) overhead in general.
Technical Explanation
The key idea behind this new agnostic active learning algorithm is to build on the "splitting-based" approach introduced by Dasgupta in 2004. Dasgupta's method was designed for the "realizable" setting, where there exists a perfect model in the hypothesis class.
This paper extends Dasgupta's splitting-based approach to the more general "agnostic" setting, where there may not be a perfect model in the hypothesis class. The new algorithm maintains a partition of the hypothesis class and selects queries that split this partition, gradually refining the partition to identify a good model.
Importantly, the algorithm is able to achieve a sample complexity that is nearly optimal, using only O(m* log |H|) queries to get the same error rate O(η) as the best possible algorithm, which uses m* queries. This is done by carefully managing the refinement of the partition to balance exploration and exploitation.
The paper also establishes a lower bound, showing that it is NP-hard to do significantly better than this O(log |H|) overhead in the general agnostic setting.
Critical Analysis
The main strength of this work is that it provides a new agnostic active learning algorithm with strong theoretical guarantees, improving upon the limitations of previous approaches that relied on the disagreement coefficient.
However, the analysis is focused on the sample complexity (number of queries) and does not address other practical considerations, such as the computational complexity of the algorithm or its robustness to noise or other real-world challenges.
Additionally, the lower bound result suggests that further asymptotic improvements may be difficult to achieve. It would be interesting to see if there are ways to optimize the constants or develop specialized algorithms for particular hypothesis classes or data distributions.
Overall, this paper makes an important theoretical contribution, but more work may be needed to translate these ideas into practical, high-performing agnostic active learning systems.
Conclusion
This paper presents a new algorithm for agnostic active learning that is nearly optimal in terms of sample complexity, using only O(m* log |H|) queries to achieve the same error rate as the best possible algorithm. This improves upon previous approaches that relied on the disagreement coefficient, which can be inefficient on certain inputs.
The key technical insight is to extend the splitting-based approach of Dasgupta to the more general agnostic setting, carefully managing the refinement of the hypothesis class partition. The paper also establishes a lower bound, showing that it is computationally hard to do significantly better than this O(log |H|) overhead.
While this work is an important theoretical advance, further research may be needed to translate these ideas into practical, high-performing agnostic active learning systems that can address additional considerations beyond sample complexity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
A Competitive Algorithm for Agnostic Active Learning
Eric Price, Yihan Zhou
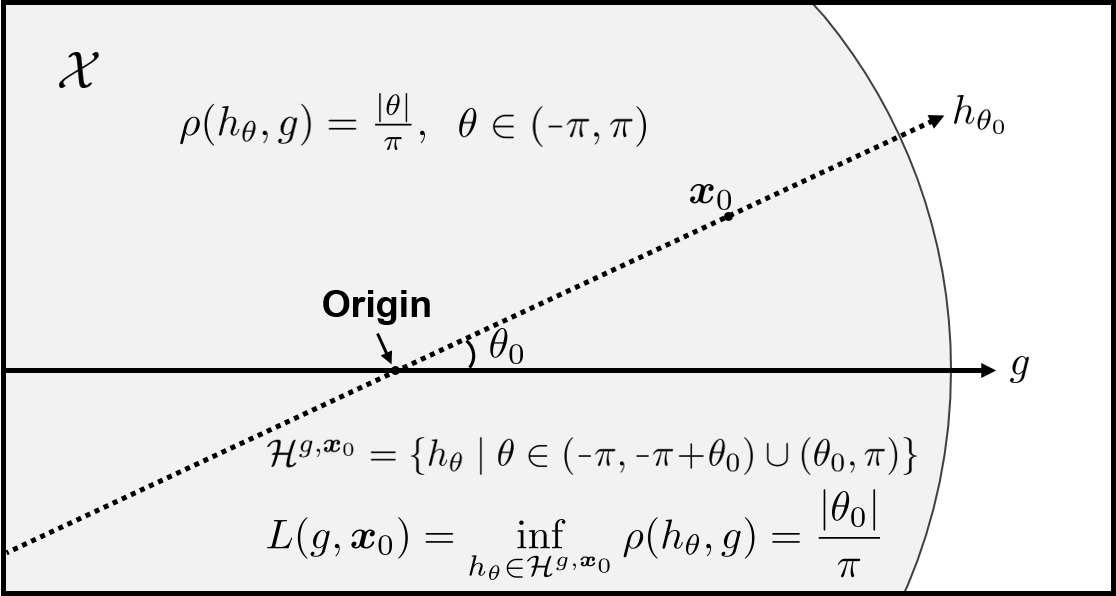
For some hypothesis classes and input distributions, active agnostic learning needs exponentially fewer samples than passive learning; for other classes and distributions, it offers little to no improvement. The most popular algorithms for agnostic active learning express their performance in terms of a parameter called the disagreement coefficient, but it is known that these algorithms are inefficient on some inputs. We take a different approach to agnostic active learning, getting an algorithm that is competitive with the optimal algorithm for any binary hypothesis class $H$ and distribution $D_X$ over $X$. In particular, if any algorithm can use $m^*$ queries to get $O(eta)$ error, then our algorithm uses $O(m^* log |H|)$ queries to get $O(eta)$ error. Our algorithm lies in the vein of the splitting-based approach of Dasgupta [2004], which gets a similar result for the realizable ($eta = 0$) setting. We also show that it is NP-hard to do better than our algorithm's $O(log |H|)$ overhead in general.
Read more5/24/2024
📈
0
Agnostic Active Learning of Single Index Models with Linear Sample Complexity
Aarshvi Gajjar, Wai Ming Tai, Xingyu Xu, Chinmay Hegde, Yi Li, Christopher Musco
We study active learning methods for single index models of the form $F({mathbf x}) = f(langle {mathbf w}, {mathbf x}rangle)$, where $f:mathbb{R} to mathbb{R}$ and ${mathbf x,mathbf w} in mathbb{R}^d$. In addition to their theoretical interest as simple examples of non-linear neural networks, single index models have received significant recent attention due to applications in scientific machine learning like surrogate modeling for partial differential equations (PDEs). Such applications require sample-efficient active learning methods that are robust to adversarial noise. I.e., that work even in the challenging agnostic learning setting. We provide two main results on agnostic active learning of single index models. First, when $f$ is known and Lipschitz, we show that $tilde{O}(d)$ samples collected via {statistical leverage score sampling} are sufficient to learn a near-optimal single index model. Leverage score sampling is simple to implement, efficient, and already widely used for actively learning linear models. Our result requires no assumptions on the data distribution, is optimal up to log factors, and improves quadratically on a recent ${O}(d^{2})$ bound of cite{gajjar2023active}. Second, we show that $tilde{O}(d)$ samples suffice even in the more difficult setting when $f$ is emph{unknown}. Our results leverage tools from high dimensional probability, including Dudley's inequality and dual Sudakov minoration, as well as a novel, distribution-aware discretization of the class of Lipschitz functions.
Read more7/11/2024
0
Querying Easily Flip-flopped Samples for Deep Active Learning
Seong Jin Cho, Gwangsu Kim, Junghyun Lee, Jinwoo Shin, Chang D. Yoo
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
Read more5/17/2024
🏅
0
Active Learning with Simple Questions
Vasilis Kontonis, Mingchen Ma, Christos Tzamos
We consider an active learning setting where a learner is presented with a pool S of n unlabeled examples belonging to a domain X and asks queries to find the underlying labeling that agrees with a target concept h^* in H. In contrast to traditional active learning that queries a single example for its label, we study more general region queries that allow the learner to pick a subset of the domain T subset X and a target label y and ask a labeler whether h^*(x) = y for every example in the set T cap S. Such more powerful queries allow us to bypass the limitations of traditional active learning and use significantly fewer rounds of interactions to learn but can potentially lead to a significantly more complex query language. Our main contribution is quantifying the trade-off between the number of queries and the complexity of the query language used by the learner. We measure the complexity of the region queries via the VC dimension of the family of regions. We show that given any hypothesis class H with VC dimension d, one can design a region query family Q with VC dimension O(d) such that for every set of n examples S subset X and every h^* in H, a learner can submit O(d log n) queries from Q to a labeler and perfectly label S. We show a matching lower bound by designing a hypothesis class H with VC dimension d and a dataset S subset X of size n such that any learning algorithm using any query class with VC dimension less than O(d) must make poly(n) queries to label S perfectly. Finally, we focus on well-studied hypothesis classes including unions of intervals, high-dimensional boxes, and d-dimensional halfspaces, and obtain stronger results. In particular, we design learning algorithms that (i) are computationally efficient and (ii) work even when the queries are not answered based on the learner's pool of examples S but on some unknown superset L of S
Read more6/11/2024