Active Learning with Simple Questions
2405.07937
0
0
🏅
Abstract
We consider an active learning setting where a learner is presented with a pool S of n unlabeled examples belonging to a domain X and asks queries to find the underlying labeling that agrees with a target concept h^* in H.
In contrast to traditional active learning that queries a single example for its label, we study more general region queries that allow the learner to pick a subset of the domain T subset X and a target label y and ask a labeler whether h^
Create account to get full access
Overview
- This paper explores an active learning setting where a learner is presented with a pool of unlabeled examples and can ask queries to determine the underlying labeling that agrees with a target concept.
- Instead of querying individual examples, the learner can submit more powerful "region queries" that ask whether a subset of the domain has a particular label.
- The paper aims to quantify the trade-off between the number of queries and the complexity of the query language used by the learner.
- The complexity of the region queries is measured by the VC dimension of the family of regions.
- The main contributions include design of region query families with low VC dimension and matching lower bounds.
- The paper also focuses on specific hypothesis classes like unions of intervals, high-dimensional boxes, and halfspaces, and presents more efficient learning algorithms.
Plain English Explanation
In this research, the authors are studying a machine learning setting where a computer system is trying to learn about the world by asking questions. Traditionally, these systems would ask about the label (e.g. is this image a cat or a dog?) of individual examples. However, the authors explore a more powerful approach where the system can ask about the labels of entire
For example, instead of asking "Is this specific image a cat?", the system could ask "Are all images in this rectangular region of the input space cats?". This allows the system to gather information more efficiently and learn the underlying concept (e.g. what defines a cat) using fewer questions.
The key challenge is to find the right balance between the number of questions asked and the complexity of the questions themselves. More complex questions can provide more information per query, but may also be more difficult for the system to formulate. The authors quantify this trade-off using a concept called "VC dimension", which measures the expressiveness of the set of possible questions.
The main contributions of the paper are:
- Designing families of region queries with low VC dimension that allow the system to learn the target concept using a small number of queries.
- Proving that this is the best possible, by showing matching lower bounds - any system using queries with low VC dimension must make a large number of queries.
- Focusing on specific, well-studied types of concepts (like intervals or halfspaces) and developing even more efficient learning algorithms for those cases.
The significance of this work is that it helps push the boundaries of what's possible in
Technical Explanation
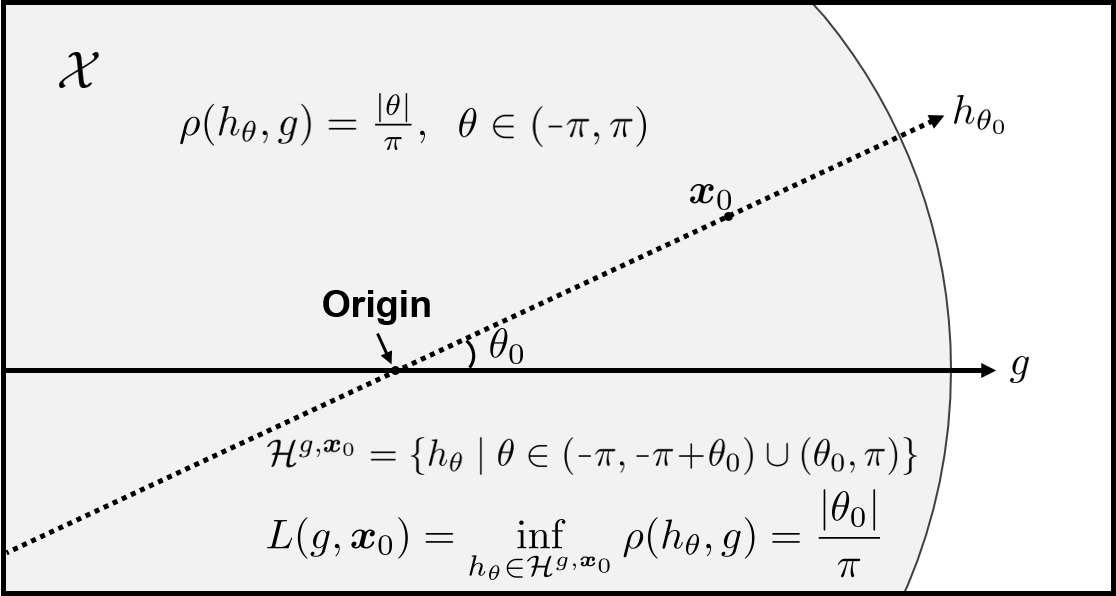
The authors consider an S of n unlabeled examples from a domain X, and the goal is to determine the underlying labeling that agrees with a target concept h* in a hypothesis class H.
In contrast to traditional active learning that queries single examples, the authors study T of the domain X and a target label y, and ask a labeler whether h*(x) = y for every x in T ∩ S. These more powerful queries can lead to significantly fewer rounds of interaction to learn the target concept, but also introduce the challenge of a more complex query language.
The authors measure the complexity of the region queries using the Q. They show that given any hypothesis class H with VC dimension d, one can design a region query family Q with VC dimension O(d) such that the learner can perfectly label the pool S using O(d log n) queries from Q.
Conversely, the authors provide a matching lower bound by designing a hypothesis class H with VC dimension d and a dataset S of size n, such that any learning algorithm using any query class with VC dimension O(d) must make poly(n) queries to label S perfectly.
Finally, the paper focuses on specific well-studied hypothesis classes, including unions of intervals, high-dimensional boxes, and d-dimensional halfspaces. For these cases, the authors develop S, but on some unknown superset L of S.
Critical Analysis
The paper makes a valuable contribution by studying the trade-off between query complexity and query expressiveness in active learning. The authors' results provide theoretical insights and practical guidelines for designing effective active learning systems.
One potential limitation is that the analysis assumes the learner has access to a perfect labeling oracle, which may not be realistic in many real-world scenarios.
Additionally, the paper focuses on passive region queries, where the learner cannot adaptively choose the queries based on previous responses. Exploring
Overall, this work provides a solid theoretical foundation for understanding the capabilities and limitations of active learning with region queries. The insights can inform the design of practical active learning systems in a variety of domains.
Conclusion
This paper presents an in-depth study of an active learning setting where a learner can submit powerful "region queries" to a labeler, rather than querying individual examples. The authors quantify the trade-off between the number of queries and the complexity of the query language, and provide both upper and lower bounds on the query complexity.
The key contributions include the design of region query families with low VC dimension that allow efficient learning, as well as the development of computationally efficient algorithms for specific hypothesis classes. This work advances our understanding of active learning and can inform the development of more effective machine learning systems that can learn from fewer, more informative queries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Transductive Active Learning: Theory and Applications
Jonas Hubotter, Bhavya Sukhija, Lenart Treven, Yarden As, Andreas Krause
0
0
We generalize active learning to address real-world settings with concrete prediction targets where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. We analyze a family of decision rules that sample adaptively to minimize uncertainty about prediction targets. We are the first to show, under general regularity assumptions, that such decision rules converge uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate their strong sample efficiency in two key applications: Active few-shot fine-tuning of large neural networks and safe Bayesian optimization, where they improve significantly upon the state-of-the-art.
5/24/2024

Open Problem: Active Representation Learning
Nikola Milosevic, Gesine Muller, Jan Huisken, Nico Scherf
0
0
In this work, we introduce the concept of Active Representation Learning, a novel class of problems that intertwines exploration and representation learning within partially observable environments. We extend ideas from Active Simultaneous Localization and Mapping (active SLAM), and translate them to scientific discovery problems, exemplified by adaptive microscopy. We explore the need for a framework that derives exploration skills from representations that are in some sense actionable, aiming to enhance the efficiency and effectiveness of data collection and model building in the natural sciences.
6/7/2024
Querying Easily Flip-flopped Samples for Deep Active Learning
Seong Jin Cho, Gwangsu Kim, Junghyun Lee, Jinwoo Shin, Chang D. Yoo
0
0
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
5/17/2024

Hyperbolic Active Learning for Semantic Segmentation under Domain Shift
Luca Franco, Paolo Mandica, Konstantinos Kallidromitis, Devin Guillory, Yu-Teng Li, Trevor Darrell, Fabio Galasso
0
0
We introduce a hyperbolic neural network approach to pixel-level active learning for semantic segmentation. Analysis of the data statistics leads to a novel interpretation of the hyperbolic radius as an indicator of data scarcity. In HALO (Hyperbolic Active Learning Optimization), for the first time, we propose the use of epistemic uncertainty as a data acquisition strategy, following the intuition of selecting data points that are the least known. The hyperbolic radius, complemented by the widely-adopted prediction entropy, effectively approximates epistemic uncertainty. We perform extensive experimental analysis based on two established synthetic-to-real benchmarks, i.e. GTAV $rightarrow$ Cityscapes and SYNTHIA $rightarrow$ Cityscapes. Additionally, we test HALO on Cityscape $rightarrow$ ACDC for domain adaptation under adverse weather conditions, and we benchmark both convolutional and attention-based backbones. HALO sets a new state-of-the-art in active learning for semantic segmentation under domain shift and it is the first active learning approach that surpasses the performance of supervised domain adaptation while using only a small portion of labels (i.e., 1%).
6/5/2024