Compositional Learning of Visually-Grounded Concepts Using Reinforcement
2309.04504
0
0
🏅
Abstract
Children can rapidly generalize compositionally-constructed rules to unseen test sets. On the other hand, deep reinforcement learning (RL) agents need to be trained over millions of episodes, and their ability to generalize to unseen combinations remains unclear. Hence, we investigate the compositional abilities of RL agents, using the task of navigating to specified color-shape targets in synthetic 3D environments. First, we show that when RL agents are naively trained to navigate to target color-shape combinations, they implicitly learn to decompose the combinations, allowing them to (re-)compose these and succeed at held-out test combinations (compositional learning). Second, when agents are pretrained to learn invariant shape and color concepts (concept learning), the number of episodes subsequently needed for compositional learning decreased by 20 times. Furthermore, only agents trained on both concept and compositional learning could solve a more complex, out-of-distribution environment in zero-shot fashion. Finally, we verified that only text encoders pretrained on image-text datasets (e.g. CLIP) reduced the number of training episodes needed for our agents to demonstrate compositional learning, and also generalized to 5 unseen colors in zero-shot fashion. Overall, our results are the first to demonstrate that RL agents can be trained to implicitly learn concepts and compositionality, to solve more complex environments in zero-shot fashion.
Create account to get full access
Overview
- Children can quickly learn and apply rules to new situations, while deep reinforcement learning (RL) agents require extensive training to achieve comparable abilities.
- This paper investigates the compositional learning abilities of RL agents in navigating to specified color-shape targets in synthetic 3D environments.
- The researchers found that RL agents can implicitly learn to decompose and re-compose color-shape combinations, and that pre-training on concept learning further improves their compositional learning abilities.
- Agents trained on both concept and compositional learning were able to solve more complex, out-of-distribution environments in a zero-shot fashion.
- The researchers also found that pre-training on image-text datasets like CLIP can reduce the number of training episodes needed for agents to demonstrate compositional learning and generalize to unseen colors.
Plain English Explanation
When children learn a new rule or concept, they can often apply it to completely novel situations with ease. For example, if a child learns that red squares and blue circles are targets to find, they can immediately start looking for other color-shape combinations they've never seen before.
On the other hand, deep reinforcement learning agents, which are AI systems that learn by trial-and-error, typically need to be trained over millions of repetitions before they can match this kind of flexible, "compositional" learning. It's been unclear whether RL agents can actually learn to decompose and recombine concepts in the way that children do.
In this paper, the researchers set out to investigate the compositional learning abilities of RL agents. They trained the agents to navigate to target color-shape combinations in synthetic 3D environments. They found that even when the agents were just trained to find specific color-shape targets, they were able to implicitly learn to break down those combinations and then recombine the components to succeed at new, unseen test scenarios.
Furthermore, when the agents were first pre-trained to learn general concepts of color and shape, they needed 20 times fewer training episodes to demonstrate this compositional learning ability. Agents trained this way could also solve more complex, out-of-distribution environments in a "zero-shot" fashion - without any additional training.
The researchers also discovered that pre-training the agents on large image-text datasets like CLIP could similarly reduce the training needed for compositional learning, and allow the agents to generalize to completely new colors.
Overall, this study is the first to show that RL agents can be trained to implicitly learn both conceptual knowledge and the ability to compose that knowledge in flexible ways, allowing them to solve increasingly complex tasks. This brings us closer to AI systems that can learn and apply knowledge as fluidly as young children.
Technical Explanation
The researchers investigated the compositional learning abilities of deep reinforcement learning (RL) agents in the context of navigating to specified color-shape targets in synthetic 3D environments.
First, they showed that when RL agents are trained to navigate to particular color-shape combinations, they implicitly learn to decompose those combinations, allowing them to (re-)compose the elements and succeed at held-out test combinations. This demonstrates a form of "compositional learning" in RL agents.
Second, the researchers found that when agents are pre-trained to learn invariant shape and color concepts ("concept learning"), the number of training episodes subsequently needed for compositional learning decreased by 20 times. Furthermore, only agents trained on both concept and compositional learning could solve a more complex, out-of-distribution environment in zero-shot fashion.
Finally, the researchers verified that pre-training text encoders on large image-text datasets like CLIP could also reduce the training needed for agents to demonstrate compositional learning. These pretrained agents were also able to generalize to 5 unseen colors in a zero-shot manner.
Overall, this work provides the first demonstration that RL agents can be trained to implicitly learn both conceptual knowledge and the ability to compose that knowledge in flexible ways, enabling them to solve increasingly complex tasks.
Critical Analysis
The paper presents compelling evidence that RL agents can learn compositional skills, challenging the narrative that they struggle to generalize beyond their training. However, the authors acknowledge that their experiments are limited to synthetic 3D environments, and it remains to be seen how well these findings would translate to more complex, real-world scenarios.
Additionally, the paper does not delve into the specifics of the RL agent architecture or training procedures, making it difficult to assess the broader applicability of their approach. More details on the model design choices and hyperparameter tuning would help other researchers build upon this work.
Furthermore, the researchers only tested generalization to novel color-shape combinations and unseen colors. It would be valuable to explore the agents' ability to compose concepts in more complex ways, such as navigating to targets defined by multiple attributes (e.g., red circle and blue square) or handling hierarchical compositions (e.g., navigating to the red object that contains a blue shape).
Finally, while the use of pre-trained CLIP encoders is an intriguing finding, the paper does not provide a clear explanation for why this approach is effective. Additional analysis into the representations learned by CLIP and how they enable efficient compositional learning in RL agents would strengthen the paper's theoretical contributions.
Overall, this work represents an important step forward in understanding the compositional learning capabilities of RL agents, but further research is needed to fully characterize the limits and potential of this approach.
Conclusion
This study demonstrates that deep reinforcement learning (RL) agents can implicitly learn to decompose and recombine color-shape concepts, overcoming the common perception that they struggle with compositional learning. By pre-training agents on both conceptual knowledge and compositional tasks, the researchers were able to significantly reduce the amount of training required for agents to exhibit flexible, generalized abilities.
The finding that pre-trained CLIP encoders can further boost compositional learning in RL agents is particularly intriguing, suggesting that leveraging large-scale vision-language models may be a promising path for enhancing the generalization capabilities of RL systems.
Overall, this work takes an important step towards developing AI agents that can learn and apply knowledge as fluidly as young children. By continuing to explore compositional learning in RL, researchers may uncover the key principles that enable flexible, human-like reasoning in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
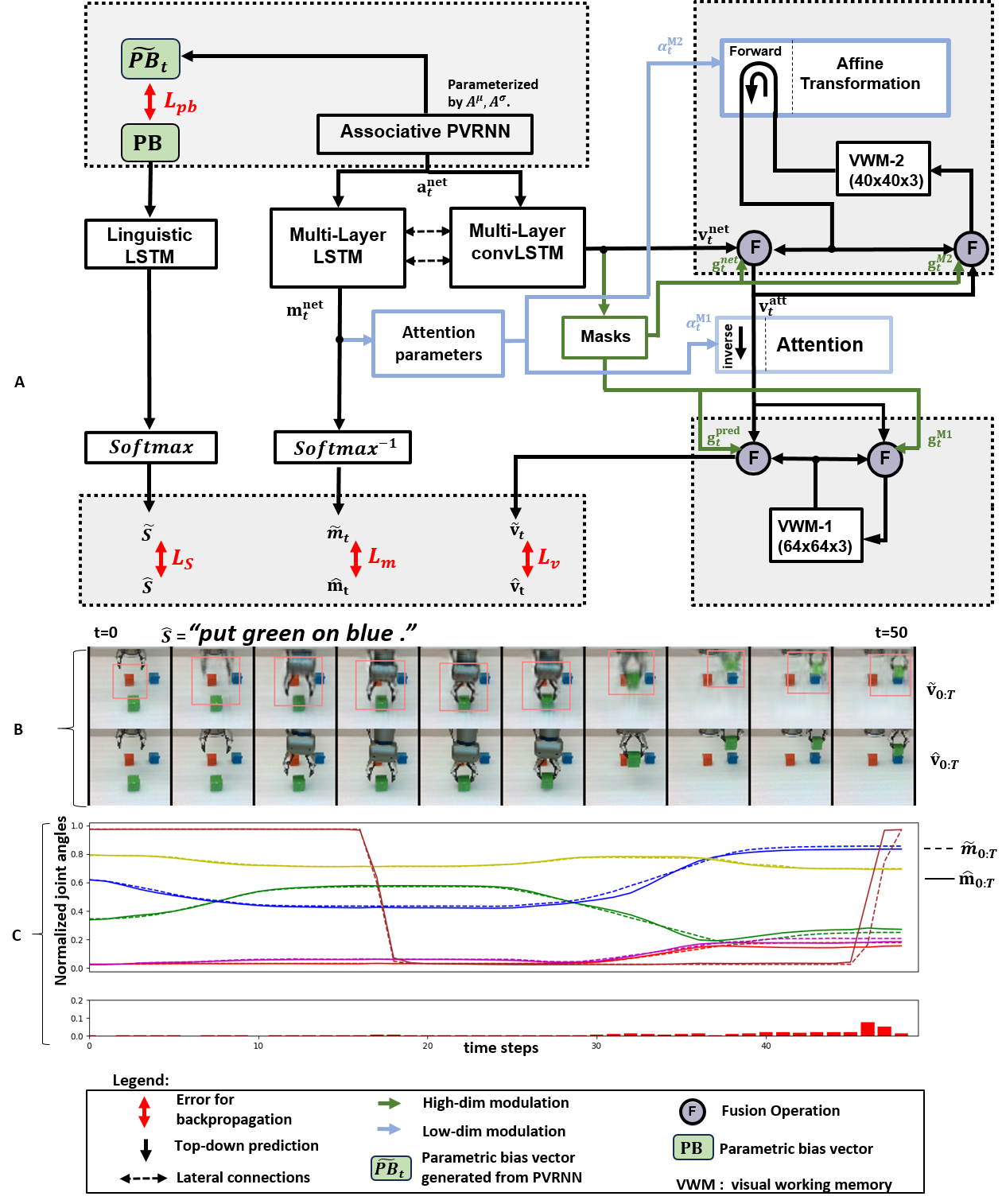
Development of Compositionality and Generalization through Interactive Learning of Language and Action of Robots
Prasanna Vijayaraghavan, Jeffrey Frederic Queisser, Sergio Verduzco Flores, Jun Tani
0
0
Humans excel at applying learned behavior to unlearned situations. A crucial component of this generalization behavior is our ability to compose/decompose a whole into reusable parts, an attribute known as compositionality. One of the fundamental questions in robotics concerns this characteristic. How can linguistic compositionality be developed concomitantly with sensorimotor skills through associative learning, particularly when individuals only learn partial linguistic compositions and their corresponding sensorimotor patterns? To address this question, we propose a brain-inspired neural network model that integrates vision, proprioception, and language into a framework of predictive coding and active inference, based on the free-energy principle. The effectiveness and capabilities of this model were assessed through various simulation experiments conducted with a robot arm. Our results show that generalization in learning to unlearned verb-noun compositions, is significantly enhanced when training variations of task composition are increased. We attribute this to self-organized compositional structures in linguistic latent state space being influenced significantly by sensorimotor learning. Ablation studies show that visual attention and working memory are essential to accurately generate visuo-motor sequences to achieve linguistically represented goals. These insights advance our understanding of mechanisms underlying development of compositionality through interactions of linguistic and sensorimotor experience.
4/1/2024
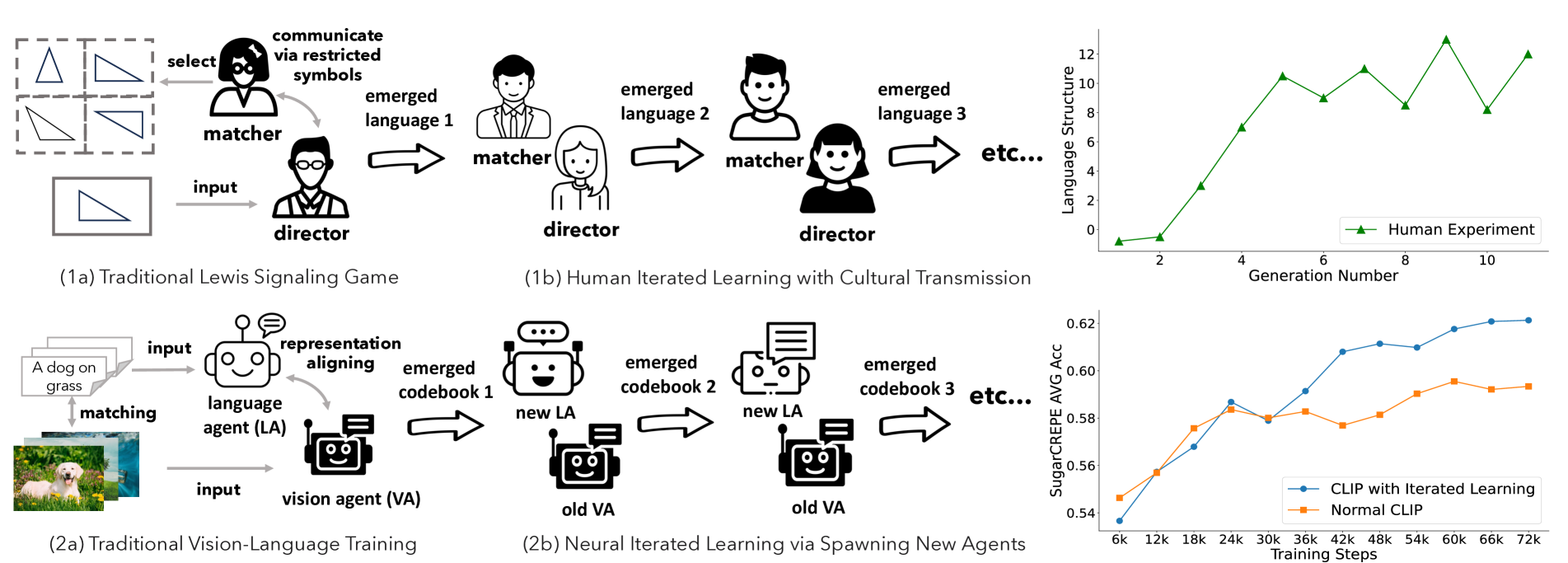
Iterated Learning Improves Compositionality in Large Vision-Language Models
Chenhao Zheng, Jieyu Zhang, Aniruddha Kembhavi, Ranjay Krishna
0
0
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most-if not all-our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of a girl in white facing a man in black and a girl in black facing a man in white. Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission-the need to teach a new generation-as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become easier to learn, a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
4/3/2024

A Survey on Compositional Learning of AI Models: Theoretical and Experimetnal Practices
Sania Sinha, Tanawan Premsri, Parisa Kordjamshidi
0
0
Compositional learning, mastering the ability to combine basic concepts and construct more intricate ones, is crucial for human cognition, especially in human language comprehension and visual perception. This notion is tightly connected to generalization over unobserved situations. Despite its integral role in intelligence, there is a lack of systematic theoretical and experimental research methodologies, making it difficult to analyze the compositional learning abilities of computational models. In this paper, we survey the literature on compositional learning of AI models and the connections made to cognitive studies. We identify abstract concepts of compositionality in cognitive and linguistic studies and connect these to the computational challenges faced by language and vision models in compositional reasoning. We overview the formal definitions, tasks, evaluation benchmarks, variety of computational models, and theoretical findings. We cover modern studies on large language models to provide a deeper understanding of the cutting-edge compositional capabilities exhibited by state-of-the-art AI models and pinpoint important directions for future research.
6/14/2024

Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Aleksandar Stani'c, Sergi Caelles, Michael Tschannen
0
0
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
5/16/2024