Learning to Compose: Improving Object Centric Learning by Injecting Compositionality

0
🔎
Sign in to get full access
Overview
- Learning compositional representation is crucial for object-centric learning, enabling flexible systematic generalization and complex visual reasoning.
- Existing approaches often rely on auto-encoding objectives, where compositionality is implicitly imposed by architectural or algorithmic biases in the encoder.
- This misalignment between auto-encoding and learning compositionality can lead to failure in capturing meaningful object representations.
Plain English Explanation
Object-centric learning is a field of AI that aims to build models that understand the world in terms of discrete objects and their relationships. Compositionality is a key aspect of this, as it allows the model to flexibly combine and recombine representations of objects in a systematic way. This supports complex visual reasoning and the ability to generalize to new situations.
However, most existing approaches to object-centric learning rely on an auto-encoding objective, where the model tries to reconstruct the original input image. The compositionality is then imposed indirectly through the architecture or algorithms used in the encoder. This can lead to a mismatch, where the model may fail to capture meaningful representations of the individual objects.
To address this, the researchers in this study propose a new objective that explicitly encourages the model to learn compositional representations. Building on existing object-centric frameworks like slot attention, they add additional constraints that encourage the model to treat object representations as modular building blocks that can be combined in valid ways.
Technical Explanation
The key technical contribution of this work is a novel objective function that explicitly encourages the model to learn compositional object representations. This is in contrast to standard auto-encoding approaches, where compositionality is only implicitly encouraged through architectural or algorithmic biases.
The new objective function has two main components:
- Reconstruction Loss: This is the standard auto-encoding loss, where the model tries to reconstruct the original input image.
- Compositionality Loss: This additional loss term encourages the model to treat the object representations as modular building blocks. Specifically, it maximizes the likelihood of composite images formed by combining object representations from different input images.
By incorporating this compositionality loss, the researchers show that the model is able to learn more meaningful and robust object representations, leading to improved performance on various object-centric learning tasks. This approach also makes the model less sensitive to the specific architectural choices, indicating that the compositionality objective is a more reliable way of encouraging this desirable property.
Critical Analysis
The researchers present a compelling approach to improving the compositionality of object representations in object-centric learning models. The explicit compositionality loss is a novel and promising direction, and the empirical results demonstrate its effectiveness.
However, the paper does not discuss some potential limitations or areas for further exploration. For example, it would be interesting to understand how this approach scales to more complex scenes with a larger number of objects, or how it might handle occlusions and other challenging real-world situations.
Additionally, the paper could benefit from a more thorough discussion of the potential downsides or failure modes of the proposed method. While the results are positive, it's important to also consider potential issues or edge cases that may arise in practice.
Overall, this is a well-executed study that makes a valuable contribution to the field of compositional neural textures. Encouraging readers to think critically about the research and its limitations is an important aspect of contrasting intra-modal and cross-modal approaches in this domain.
Conclusion
This research proposes a novel objective function that explicitly encourages the learning of compositional object representations in object-centric learning models. By adding a compositionality loss term to the standard auto-encoding objective, the researchers show that their approach leads to more meaningful and robust object representations, improving performance on various tasks.
This work is an important step towards building AI systems that can reason about the world in terms of discrete objects and their relationships, a key capability for advancing visual understanding and reasoning. The explicit focus on compositionality is a promising direction that could have far-reaching implications for the field of object-centric learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Learning to Compose: Improving Object Centric Learning by Injecting Compositionality
Whie Jung, Jaehoon Yoo, Sungjin Ahn, Seunghoon Hong
Learning compositional representation is a key aspect of object-centric learning as it enables flexible systematic generalization and supports complex visual reasoning. However, most of the existing approaches rely on auto-encoding objective, while the compositionality is implicitly imposed by the architectural or algorithmic bias in the encoder. This misalignment between auto-encoding objective and learning compositionality often results in failure of capturing meaningful object representations. In this study, we propose a novel objective that explicitly encourages compositionality of the representations. Built upon the existing object-centric learning framework (e.g., slot attention), our method incorporates additional constraints that an arbitrary mixture of object representations from two images should be valid by maximizing the likelihood of the composite data. We demonstrate that incorporating our objective to the existing framework consistently improves the objective-centric learning and enhances the robustness to the architectural choices.
Read more5/2/2024

0
Weak-to-Strong Compositional Learning from Generative Models for Language-based Object Detection
Kwanyong Park, Kuniaki Saito, Donghyun Kim
Vision-language (VL) models often exhibit a limited understanding of complex expressions of visual objects (e.g., attributes, shapes, and their relations), given complex and diverse language queries. Traditional approaches attempt to improve VL models using hard negative synthetic text, but their effectiveness is limited. In this paper, we harness the exceptional compositional understanding capabilities of generative foundational models. We introduce a novel method for structured synthetic data generation aimed at enhancing the compositional understanding of VL models in language-based object detection. Our framework generates densely paired positive and negative triplets (image, text descriptions, and bounding boxes) in both image and text domains. By leveraging these synthetic triplets, we transform 'weaker' VL models into 'stronger' models in terms of compositional understanding, a process we call Weak-to-Strong Compositional Learning (WSCL). To achieve this, we propose a new compositional contrastive learning formulation that discovers semantics and structures in complex descriptions from synthetic triplets. As a result, VL models trained with our synthetic data generation exhibit a significant performance boost in the Omnilabel benchmark by up to +5AP and the D3 benchmark by +6.9AP upon existing baselines.
Read more7/23/2024

0
Zero-Shot Object-Centric Representation Learning
Aniket Didolkar, Andrii Zadaianchuk, Anirudh Goyal, Mike Mozer, Yoshua Bengio, Georg Martius, Maximilian Seitzer
The goal of object-centric representation learning is to decompose visual scenes into a structured representation that isolates the entities. Recent successes have shown that object-centric representation learning can be scaled to real-world scenes by utilizing pre-trained self-supervised features. However, so far, object-centric methods have mostly been applied in-distribution, with models trained and evaluated on the same dataset. This is in contrast to the wider trend in machine learning towards general-purpose models directly applicable to unseen data and tasks. Thus, in this work, we study current object-centric methods through the lens of zero-shot generalization by introducing a benchmark comprising eight different synthetic and real-world datasets. We analyze the factors influencing zero-shot performance and find that training on diverse real-world images improves transferability to unseen scenarios. Furthermore, inspired by the success of task-specific fine-tuning in foundation models, we introduce a novel fine-tuning strategy to adapt pre-trained vision encoders for the task of object discovery. We find that the proposed approach results in state-of-the-art performance for unsupervised object discovery, exhibiting strong zero-shot transfer to unseen datasets.
Read more8/20/2024
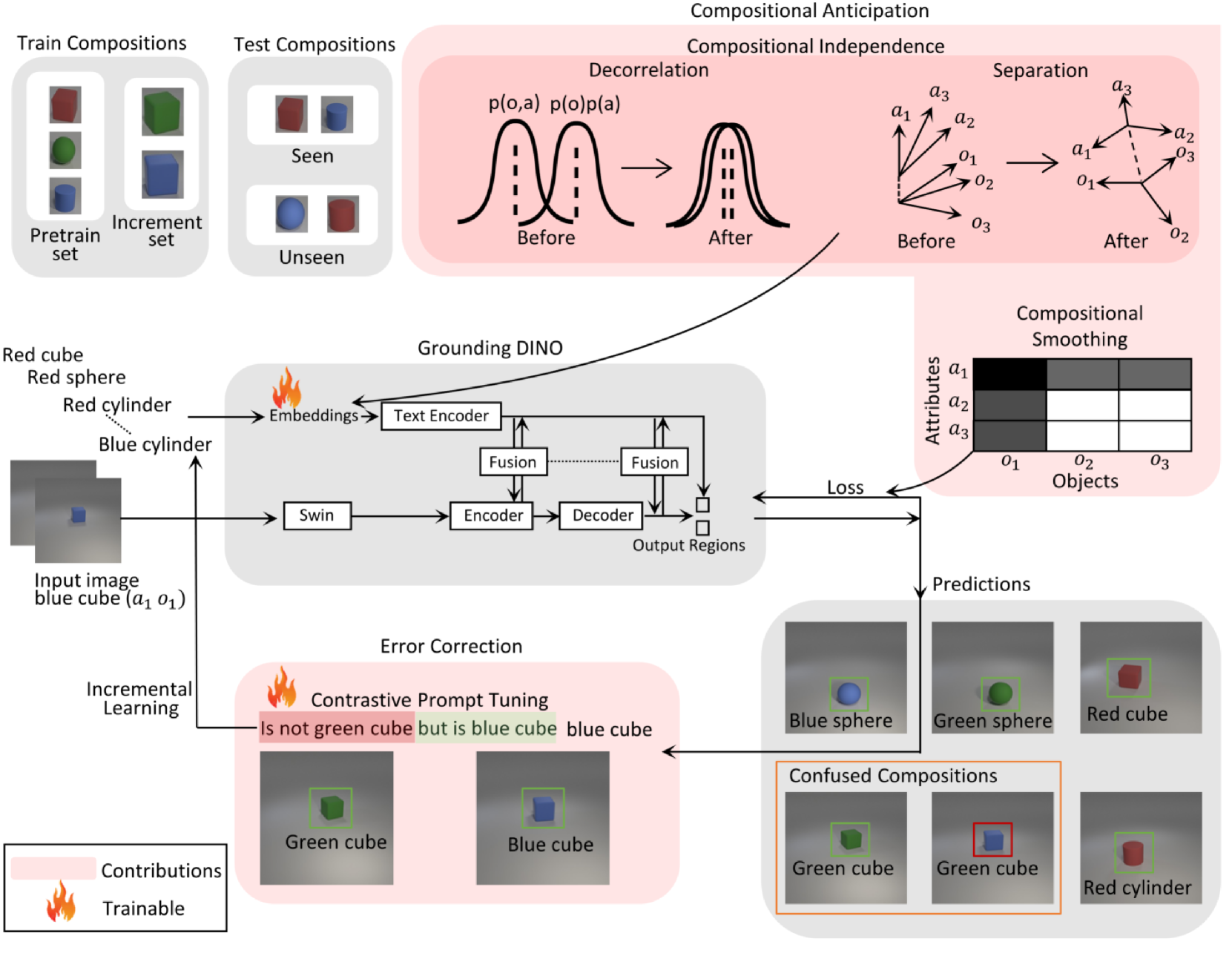
0
Anticipating Future Object Compositions without Forgetting
Youssef Zahran, Gertjan Burghouts, Yke Bauke Eisma
Despite the significant advancements in computer vision models, their ability to generalize to novel object-attribute compositions remains limited. Existing methods for Compositional Zero-Shot Learning (CZSL) mainly focus on image classification. This paper aims to enhance CZSL in object detection without forgetting prior learned knowledge. We use Grounding DINO and incorporate Compositional Soft Prompting (CSP) into it and extend it with Compositional Anticipation. We achieve a 70.5% improvement over CSP on the harmonic mean (HM) between seen and unseen compositions on the CLEVR dataset. Furthermore, we introduce Contrastive Prompt Tuning to incrementally address model confusion between similar compositions. We demonstrate the effectiveness of this method and achieve an increase of 14.5% in HM across the pretrain, increment, and unseen sets. Collectively, these methods provide a framework for learning various compositions with limited data, as well as improving the performance of underperforming compositions when additional data becomes available.
Read more9/4/2024