Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
2401.01974
0
0

Abstract
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
Create account to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) as programmers for visual reasoning tasks.
- The key idea is to leverage the powerful language understanding and generation capabilities of LLMs to programmatically solve visual reasoning problems, rather than relying on end-to-end neural networks.
- The researchers propose a framework that allows LLMs to generate executable programs that can be applied to visual inputs to produce the desired outputs, enabling truly zero-shot compositional visual reasoning.
Plain English Explanation
The paper presents a new approach to solving visual reasoning tasks, which are challenges that require understanding and reasoning about visual information. Instead of using traditional machine learning models that try to learn these tasks directly from data, the researchers propose using Large Language Models (LLMs) as "programmers" to generate executable programs that can solve the tasks.
LLMs are a type of AI model that have become very advanced at understanding and generating human language. The key insight of this work is that these language-based models can be leveraged to programmatically solve visual reasoning problems, rather than trying to learn the tasks directly from visual data.
The framework works by having the LLM generate a step-by-step program (a set of instructions) that can be applied to a given visual input to produce the desired output. For example, if the task is to count the number of red objects in an image, the LLM would generate a program that segments the image, identifies the red objects, and then counts them.
This approach has several potential advantages over end-to-end neural network models. First, it allows for truly zero-shot compositional reasoning, where the model can solve novel combinations of visual reasoning tasks without requiring additional training. Second, the generated programs can be inspected and debugged, providing more transparency and interpretability compared to black-box neural networks. Finally, the modular nature of the approach may allow for better generalization and transfer learning than end-to-end models.
Technical Explanation
The core of the proposed framework is a Large Language Model (LLM) that is trained to generate executable programs in a domain-specific language (DSL) for solving visual reasoning tasks. The DSL provides a set of primitive operations, such as object detection, segmentation, counting, and logical reasoning, that the LLM can compose to solve complex visual tasks.
During inference, the LLM takes a visual input and a natural language description of the task as input, and generates a program in the DSL that can be executed to produce the desired output. The researchers experiment with different architectural choices for the LLM, such as prompting strategies and program execution mechanisms, to optimize the performance of the framework.
The key technical contributions of the paper include:
- A novel framework that leverages the capabilities of LLMs to programmatically solve visual reasoning tasks, enabling true zero-shot compositional reasoning.
- The design of a domain-specific language tailored for visual reasoning tasks, which provides the necessary primitives for the LLM to compose into executable programs.
- Extensive experiments on a range of visual reasoning benchmarks, demonstrating the effectiveness of the proposed approach compared to end-to-end neural network models.
- Analyses of the generated programs, showing that they can be interpreted and debugged, providing insights into the model's reasoning process.
Critical Analysis
The proposed framework is a promising step towards truly zero-shot compositional visual reasoning, an important challenge in artificial intelligence. By leveraging the language understanding and generation capabilities of LLMs, the authors have demonstrated an approach that can potentially generalize to novel combinations of visual reasoning tasks without requiring additional training.
However, the paper also acknowledges several limitations and areas for future research. First, the current DSL may not be expressive enough to capture the full range of visual reasoning tasks, and expanding the language's primitives and composition rules could be an important direction. Second, the performance of the framework is still behind that of specialized neural network models on some benchmarks, suggesting that further improvements are needed in the program generation and execution mechanisms.
Additionally, the paper does not address the potential issues of safety and robustness when using LLMs as programmers. LLMs can sometimes produce biased or even harmful output, and ensuring the generated programs are reliable and aligned with human values is a critical challenge that warrants further investigation.
Finally, the interpretability and transparency provided by the modular program-based approach is a promising feature, but the paper does not explore how this can be leveraged for deeper scientific understanding or human-AI collaboration.
Conclusion
This paper presents a novel framework that uses Large Language Models as programmers to solve visual reasoning tasks in a truly zero-shot and compositional manner. By generating executable programs that can be applied to visual inputs, the approach holds the potential to overcome some of the limitations of end-to-end neural network models, such as their black-box nature and difficulty in generalizing to novel task compositions.
While the proposed framework shows promising results, there are still several technical and conceptual challenges that need to be addressed, such as expanding the expressiveness of the domain-specific language, improving the program generation and execution mechanisms, and ensuring the safety and robustness of the LLM-based approach.
Overall, this work represents an important step towards the goal of building AI systems that can flexibly and compositionally reason about the visual world, with potential applications in areas such as computer vision, robotics, and scientific discovery. As the field of AI continues to evolve, approaches that leverage the complementary strengths of language models and specialized neural networks, like the one presented in this paper, may play a crucial role in advancing the state of the art in visual reasoning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
0
0
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
5/14/2024

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024

ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
Irene Huang, Wei Lin, M. Jehanzeb Mirza, Jacob A. Hansen, Sivan Doveh, Victor Ion Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuhene, Trevor Darrel, Chuang Gan, Aude Oliva, Rogerio Feris, Leonid Karlinsky
0
0
Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM-only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
6/13/2024
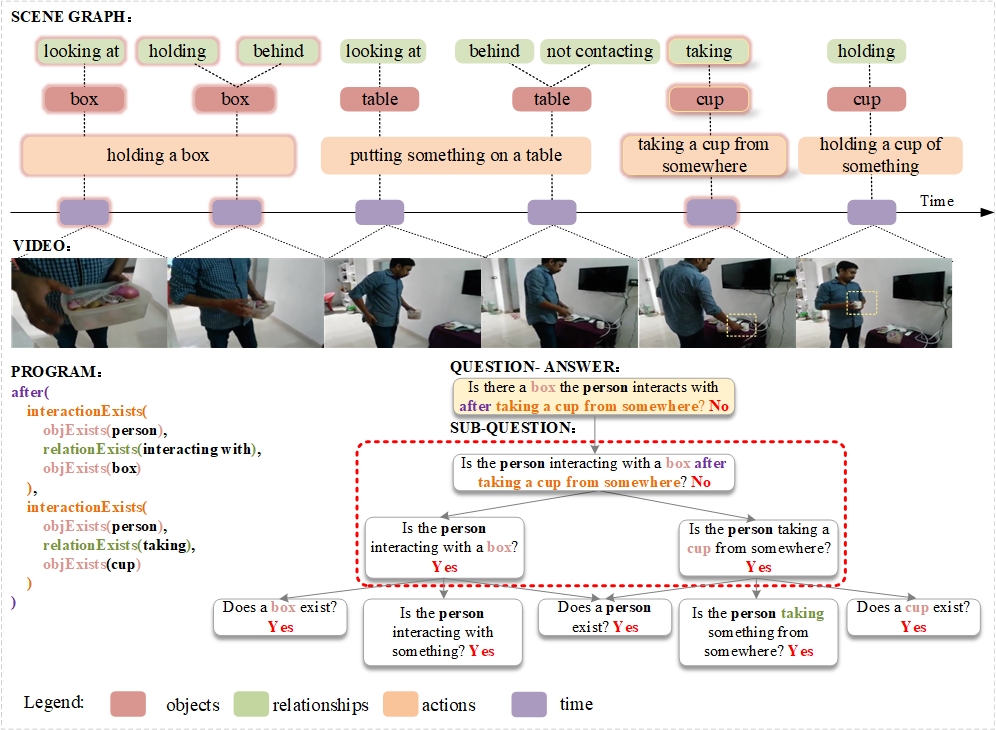
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Lili Liang, Guanglu Sun, Jin Qiu, Lizhong Zhang
0
0
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
4/8/2024