Iterated Learning Improves Compositionality in Large Vision-Language Models
2404.02145
0
0
Abstract
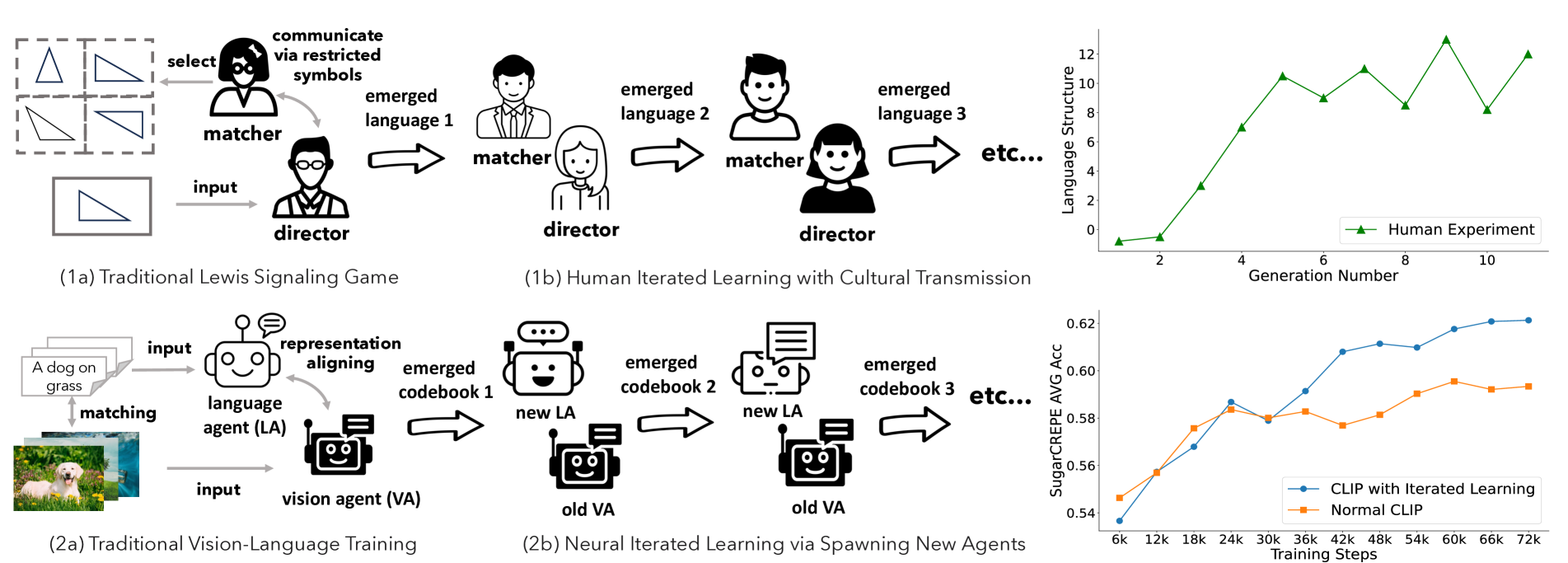
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most-if not all-our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of a girl in white facing a man in black and a girl in black facing a man in white. Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission-the need to teach a new generation-as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become easier to learn, a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how "iterated learning" can improve the compositional abilities of large vision-language models.
- Iterated learning involves training models using data generated by other models, rather than human-created data.
- The authors find that this approach enhances the models' ability to combine visual and linguistic concepts in novel ways.
- This has implications for building more flexible and versatile AI systems that can better understand and generate complex, compositional language.
Plain English Explanation
Large vision-language models are AI systems that can understand and generate human language while also analyzing visual information. However, these models often struggle with compositionality - the ability to flexibly combine basic concepts into novel, more complex expressions.
The researchers in this paper propose a new training approach called "iterated learning" to address this challenge. Instead of training the models solely on human-created data, they have the models learn from data generated by other models. This iterative process allows the models to develop richer internal representations and more flexible reasoning capabilities.
Imagine you're trying to learn a new language. The traditional approach would be to study vocabulary and grammar rules from textbooks and conversations with native speakers. But an iterated learning approach would involve you teaching what you've learned to a language learner bot, then having that bot teach you back what it's learned. This back-and-forth process could help you gain a deeper, more nuanced understanding of the language.
Similarly, the iterated learning technique helps vision-language models go beyond simply memorizing associations between words and visual concepts. Instead, the models learn to dynamically combine these building blocks in novel ways, showing more human-like compositionality and creativity.
Technical Explanation
The key technical contributions of this paper are:
-
Iterated Learning Procedure: The authors develop an iterated learning framework where a "student" model is trained on data generated by a "teacher" model. This process is repeated over multiple iterations, allowing the student model to gradually develop more sophisticated language and reasoning abilities.
-
Compositional Evaluation: To assess the models' compositional skills, the authors design a suite of novel evaluation tasks that test the models' ability to understand and generate complex, compositional expressions involving visual and linguistic concepts.
-
Architectural Insights: The authors analyze the internal representations of the iterated learning models and find that this approach encourages the development of more disentangled and modular representations, which facilitates compositional reasoning.
Through extensive experiments, the authors demonstrate that the iterated learning approach significantly boosts the compositional performance of large vision-language models compared to standard training techniques. This suggests iterated learning could be a valuable tool for building more flexible and versatile AI systems.
Critical Analysis
The paper provides a thoughtful and rigorous exploration of iterated learning for improving compositional abilities in vision-language models. However, a few caveats and areas for further research are worth noting:
-
Scalability: While effective on the benchmarks tested, it's unclear how well the iterated learning approach would scale to larger, more complex model architectures and datasets. The computational overhead of the iterative training process may become prohibitive.
-
Real-World Applicability: The evaluation tasks, while designed to test compositional skills, may not fully capture the nuances of how these models would perform in real-world language understanding and generation scenarios. Further research is needed to understand the practical implications.
-
Human-Centricity: The paper focuses on improving the compositional abilities of AI models, but does not explore how this might impact the human experience of interacting with such systems. Potential issues around transparency, trust, and mental models should be considered.
Overall, this paper represents an important step forward in addressing the compositionality challenge for large vision-language models. The iterated learning approach is a promising technique that warrants further investigation and refinement.
Conclusion
This research demonstrates that the iterated learning framework can significantly enhance the compositional abilities of large-scale vision-language models. By having models learn from other models, rather than just human-created data, they develop more flexible and generative language understanding and generation capabilities.
While further work is needed to address scalability and real-world applicability, this work represents an important advance in the quest to build AI systems that can engage in more human-like, creative language use. As these models continue to improve, they may enable more natural and intuitive interactions between humans and machines, with profound implications for how we work, learn, and communicate in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Development of Compositionality and Generalization through Interactive Learning of Language and Action of Robots
Prasanna Vijayaraghavan, Jeffrey Frederic Queisser, Sergio Verduzco Flores, Jun Tani
0
0
Humans excel at applying learned behavior to unlearned situations. A crucial component of this generalization behavior is our ability to compose/decompose a whole into reusable parts, an attribute known as compositionality. One of the fundamental questions in robotics concerns this characteristic. How can linguistic compositionality be developed concomitantly with sensorimotor skills through associative learning, particularly when individuals only learn partial linguistic compositions and their corresponding sensorimotor patterns? To address this question, we propose a brain-inspired neural network model that integrates vision, proprioception, and language into a framework of predictive coding and active inference, based on the free-energy principle. The effectiveness and capabilities of this model were assessed through various simulation experiments conducted with a robot arm. Our results show that generalization in learning to unlearned verb-noun compositions, is significantly enhanced when training variations of task composition are increased. We attribute this to self-organized compositional structures in linguistic latent state space being influenced significantly by sensorimotor learning. Ablation studies show that visual attention and working memory are essential to accurately generate visuo-motor sequences to achieve linguistically represented goals. These insights advance our understanding of mechanisms underlying development of compositionality through interactions of linguistic and sensorimotor experience.
4/1/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024
💬
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
0
0
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
5/14/2024
🏅
Compositional Learning of Visually-Grounded Concepts Using Reinforcement
Zijun Lin, Haidi Azaman, M Ganesh Kumar, Cheston Tan
0
0
Children can rapidly generalize compositionally-constructed rules to unseen test sets. On the other hand, deep reinforcement learning (RL) agents need to be trained over millions of episodes, and their ability to generalize to unseen combinations remains unclear. Hence, we investigate the compositional abilities of RL agents, using the task of navigating to specified color-shape targets in synthetic 3D environments. First, we show that when RL agents are naively trained to navigate to target color-shape combinations, they implicitly learn to decompose the combinations, allowing them to (re-)compose these and succeed at held-out test combinations (compositional learning). Second, when agents are pretrained to learn invariant shape and color concepts (concept learning), the number of episodes subsequently needed for compositional learning decreased by 20 times. Furthermore, only agents trained on both concept and compositional learning could solve a more complex, out-of-distribution environment in zero-shot fashion. Finally, we verified that only text encoders pretrained on image-text datasets (e.g. CLIP) reduced the number of training episodes needed for our agents to demonstrate compositional learning, and also generalized to 5 unseen colors in zero-shot fashion. Overall, our results are the first to demonstrate that RL agents can be trained to implicitly learn concepts and compositionality, to solve more complex environments in zero-shot fashion.
5/6/2024