A Comprehensive Review of Few-shot Action Recognition

0

Sign in to get full access
Overview
- This paper provides a comprehensive review of few-shot action recognition, a field that focuses on developing models that can recognize actions from limited training data.
- The review covers the latest advances in few-shot action recognition, including meta-learning approaches, cross-domain techniques, and weakly-supervised methods.
- The paper also discusses related surveys and outlines the key challenges and open research questions in this area.
Plain English Explanation
Few-shot action recognition is a subfield of machine learning that aims to develop models that can recognize actions in videos, even when only a small amount of training data is available. This is an important problem because many real-world applications, such as video surveillance or human-robot interaction, may not have access to large, labeled datasets of video actions.
The paper reviewed in this blog post provides a detailed overview of the state-of-the-art in few-shot action recognition. It covers a range of techniques, including:
- Meta-learning: These methods aim to learn a model that can quickly adapt to new actions using only a few examples.
- Cross-domain techniques: These approaches try to leverage knowledge from other related domains, such as images or other action datasets, to improve few-shot performance.
- Weakly-supervised methods: These techniques use less-detailed supervision, such as video-level labels instead of per-frame annotations, to train models with limited data.
The paper also discusses the key challenges and open research questions in this field, such as how to effectively transfer knowledge between different action domains and how to design more sample-efficient learning algorithms.
Technical Explanation
The paper begins by introducing the problem of few-shot action recognition, which involves developing models that can recognize actions in videos from only a small number of training examples. The authors note that this is an important challenge, as many real-world applications may not have access to large, labeled datasets of video actions.
The paper then provides an overview of related surveys in the field of few-shot learning, including those focused on computer vision tasks more broadly and those specifically targeting action recognition. The authors highlight how their survey aims to provide a more comprehensive and up-to-date review of the few-shot action recognition literature.
The core of the paper focuses on categorizing and summarizing the key technical approaches that have been proposed for few-shot action recognition. This includes:
-
Meta-learning: These methods aim to learn a model that can quickly adapt to new actions using only a few examples. Techniques in this category include model-agnostic meta-learning (MAML), prototypical networks, and relation networks.
-
Cross-domain techniques: These approaches try to leverage knowledge from other related domains, such as images or other action datasets, to improve few-shot performance. Examples include transfer learning, domain adaptation, and cross-modal techniques.
-
Weakly-supervised methods: These techniques use less-detailed supervision, such as video-level labels instead of per-frame annotations, to train models with limited data. This can help address the data scarcity challenge in few-shot settings.
For each category, the paper provides a detailed technical overview of the key methods, their underlying principles, and their performance on benchmark datasets.
The paper also discusses the key challenges and open research questions in this field, such as how to effectively transfer knowledge between different action domains, how to design more sample-efficient learning algorithms, and how to improve the generalization capabilities of few-shot action recognition models.
Critical Analysis
The paper provides a comprehensive and well-structured review of the few-shot action recognition literature. The authors have done an excellent job of categorizing the various technical approaches and providing detailed summaries of the key methods within each category.
One potential limitation of the paper is that it focuses primarily on academic research and may not cover some of the latest advancements being made in industry or other non-academic settings. Additionally, the paper does not delve deeply into the specific trade-offs and design choices involved in implementing these few-shot action recognition techniques in real-world applications.
The authors also acknowledge that the field of few-shot action recognition is still relatively young, with many open challenges and research questions remaining. For example, the paper highlights the need for better cross-domain transfer learning techniques, more sample-efficient learning algorithms, and improved generalization capabilities of few-shot models.
Overall, this paper provides a valuable and comprehensive resource for researchers and practitioners interested in understanding the state-of-the-art in few-shot action recognition. It serves as an excellent starting point for further exploration of this important and rapidly evolving field.
Conclusion
The paper reviewed in this blog post offers a comprehensive overview of the latest advancements in few-shot action recognition, a subfield of machine learning that focuses on developing models that can recognize actions from limited training data.
The paper covers a range of technical approaches, including meta-learning, cross-domain techniques, and weakly-supervised methods, and provides detailed summaries of the key methods within each category. It also discusses the key challenges and open research questions in this field, such as the need for better cross-domain transfer learning and more sample-efficient learning algorithms.
This review serves as a valuable resource for researchers and practitioners working in the field of few-shot action recognition, as it provides a thorough and up-to-date understanding of the state-of-the-art and the future directions of this important and rapidly evolving area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive Review of Few-shot Action Recognition
Yuyang Wanyan, Xiaoshan Yang, Weiming Dong, Changsheng Xu
Few-shot action recognition aims to address the high cost and impracticality of manually labeling complex and variable video data in action recognition. It requires accurately classifying human actions in videos using only a few labeled examples per class. Compared to few-shot learning in image scenarios, few-shot action recognition is more challenging due to the intrinsic complexity of video data. Recognizing actions involves modeling intricate temporal sequences and extracting rich semantic information, which goes beyond mere human and object identification in each frame. Furthermore, the issue of intra-class variance becomes particularly pronounced with limited video samples, complicating the learning of representative features for novel action categories. To overcome these challenges, numerous approaches have driven significant advancements in few-shot action recognition, which underscores the need for a comprehensive survey. Unlike early surveys that focus on few-shot image or text classification, we deeply consider the unique challenges of few-shot action recognition. In this survey, we review a wide variety of recent methods and summarize the general framework. Additionally, the survey presents the commonly used benchmarks and discusses relevant advanced topics and promising future directions. We hope this survey can serve as a valuable resource for researchers, offering essential guidance to newcomers and stimulating seasoned researchers with fresh insights.
Read more7/23/2024
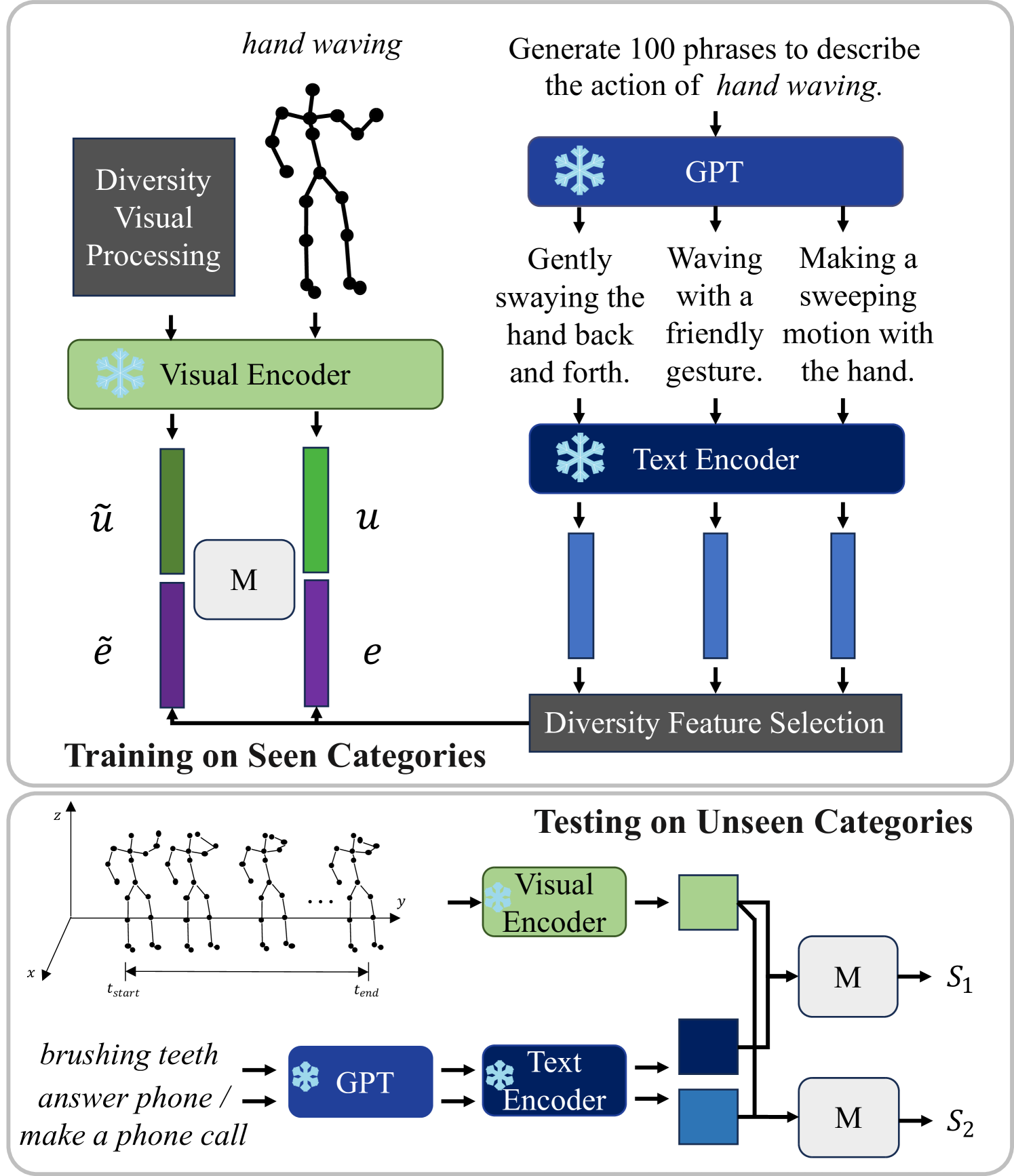
0
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024

0
Exploring Explainability in Video Action Recognition
Avinab Saha, Shashank Gupta, Sravan Kumar Ankireddy, Karl Chahine, Joydeep Ghosh
Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
Read more4/16/2024
👁️
0
Comparative Analysis: Violence Recognition from Videos using Transfer Learning
Dursun Dashdamirov
Action recognition has become a hot topic in computer vision. However, the main applications of computer vision in video processing have focused on detection of relatively simple actions while complex events such as violence detection have been comparatively less investigated. This study focuses on the benchmarking of various deep learning techniques on a complex dataset. Next, a larger dataset is utilized to test the uplift from increasing volume of data. The dataset size increase from 500 to 1,600 videos resulted in a notable average accuracy improvement of 6% across four models.
Read more8/28/2024