Towards a theory of model distillation
2403.09053
0
0
Abstract
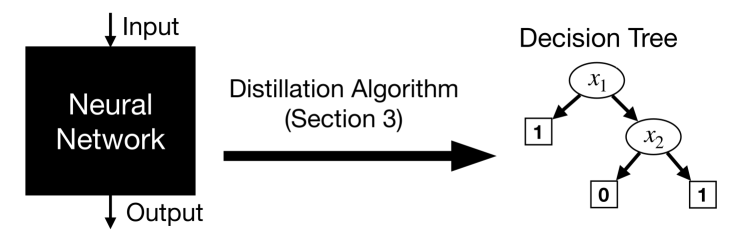
Distillation is the task of replacing a complicated machine learning model with a simpler model that approximates the original [BCNM06,HVD15]. Despite many practical applications, basic questions about the extent to which models can be distilled, and the runtime and amount of data needed to distill, remain largely open. To study these questions, we initiate a general theory of distillation, defining PAC-distillation in an analogous way to PAC-learning [Val84]. As applications of this theory: (1) we propose new algorithms to extract the knowledge stored in the trained weights of neural networks -- we show how to efficiently distill neural networks into succinct, explicit decision tree representations when possible by using the ``linear representation hypothesis''; and (2) we prove that distillation can be much cheaper than learning from scratch, and make progress on characterizing its complexity.
Create account to get full access
Overview
- Defines a new concept called "PAC-distillation" to analyze the theoretical properties of model distillation
- Presents guarantees for PAC-distillation under different assumptions about the student and teacher models
- Provides insights into how the properties of the student and teacher models impact the distillation process
Plain English Explanation
This paper introduces a new theoretical framework called "PAC-distillation" to study the process of model distillation. Model distillation is a technique where a smaller, more efficient "student" model is trained to mimic the behavior of a larger, more complex "teacher" model.
The key idea behind PAC-distillation is to understand how the properties of the student and teacher models, such as their expressive power and approximation ability, impact the distillation process. The paper provides theoretical guarantees for PAC-distillation under different assumptions about these model properties. For example, it shows that if the student model has enough capacity to approximate the teacher model, then the distillation process will be successful.
By establishing these theoretical foundations, the paper offers insights into how to design effective distillation strategies. For instance, it suggests that focusing on improving the student model's representation power may be more important than simply minimizing the distillation loss. This could lead to more efficient and reliable model compression techniques.
Technical Explanation
The paper introduces a new formalism called "PAC-distillation" to analyze the theoretical properties of model distillation. PAC-distillation is based on the Probably Approximately Correct (PAC) learning framework, which provides a way to quantify the generalization ability of machine learning models.
The key contributions of the paper are:
-
Defining PAC-distillation: The authors define PAC-distillation as a process where a "student" model is trained to PAC-learn the function represented by a "teacher" model. This allows them to analyze the theoretical guarantees of the distillation process.
-
Providing PAC-distillation guarantees: The paper presents several theorems that provide PAC-distillation guarantees under different assumptions about the student and teacher models. For example, it shows that if the student model has sufficient capacity to approximate the teacher model, then the distillation process will be successful.
-
Offering insights into distillation: By analyzing the theoretical properties of PAC-distillation, the paper provides insights into how the characteristics of the student and teacher models impact the distillation process. For instance, it suggests that improving the student model's representation power may be more important than simply minimizing the distillation loss.
The paper's theoretical analysis builds on concepts from PAC learning, knowledge distillation, and model compression. By establishing a formal framework for understanding model distillation, the authors aim to provide a foundation for developing more effective model compression techniques.
Critical Analysis
The paper provides a rigorous theoretical analysis of model distillation, which is a valuable contribution to the field. The PAC-distillation framework offers a principled way to study the properties of the distillation process and how they relate to the characteristics of the student and teacher models.
One potential limitation of the paper is that the theoretical guarantees are derived under specific assumptions, such as the student model having sufficient capacity to approximate the teacher model. In practice, these assumptions may not always hold, and the distillation process may not behave as predicted by the theory.
Additionally, the paper focuses on the theoretical aspects of distillation and does not provide extensive empirical validation of the proposed framework. While the theoretical insights are valuable, it would be helpful to see how well the PAC-distillation guarantees align with observed performance in real-world distillation tasks.
Overall, the paper makes a significant contribution to the theoretical understanding of model distillation, but further research may be needed to bridge the gap between the theoretical framework and practical applications.
Conclusion
This paper introduces a new theoretical framework called "PAC-distillation" to analyze the properties of the model distillation process. By defining PAC-distillation and providing theoretical guarantees under different assumptions, the paper offers insights into how the characteristics of the student and teacher models impact the success of the distillation process.
These theoretical insights could inform the design of more effective model compression techniques, as they suggest that improving the student model's representation power may be more important than simply minimizing the distillation loss. While the paper focuses on the theoretical aspects, its findings could have practical implications for developing efficient and reliable machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

What is Dataset Distillation Learning?
William Yang, Ye Zhu, Zhiwei Deng, Olga Russakovsky
0
0
Dataset distillation has emerged as a strategy to overcome the hurdles associated with large datasets by learning a compact set of synthetic data that retains essential information from the original dataset. While distilled data can be used to train high performing models, little is understood about how the information is stored. In this study, we posit and answer three questions about the behavior, representativeness, and point-wise information content of distilled data. We reveal distilled data cannot serve as a substitute for real data during training outside the standard evaluation setting for dataset distillation. Additionally, the distillation process retains high task performance by compressing information related to the early training dynamics of real models. Finally, we provide an framework for interpreting distilled data and reveal that individual distilled data points contain meaningful semantic information. This investigation sheds light on the intricate nature of distilled data, providing a better understanding on how they can be effectively utilized.
6/7/2024
👀
A Comprehensive Review of Knowledge Distillation in Computer Vision
Sheikh Musa Kaleem, Tufail Rouf, Gousia Habib, Tausifa jan Saleem, Brejesh Lall
0
0
Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
4/9/2024
💬
On the Surprising Efficacy of Distillation as an Alternative to Pre-Training Small Models
Sean Farhat, Deming Chen
0
0
In this paper, we propose that small models may not need to absorb the cost of pre-training to reap its benefits. Instead, they can capitalize on the astonishing results achieved by modern, enormous models to a surprising degree. We observe that, when distilled on a task from a pre-trained teacher model, a small model can achieve or surpass the performance it would achieve if it was pre-trained then finetuned on that task. To allow this phenomenon to be easily leveraged, we establish a connection reducing knowledge distillation to modern contrastive learning, opening two doors: (1) vastly different model architecture pairings can work for the distillation, and (2) most contrastive learning algorithms rooted in the theory of Noise Contrastive Estimation can be easily applied and used. We demonstrate this paradigm using pre-trained teacher models from open-source model hubs, Transformer and convolution based model combinations, and a novel distillation algorithm that massages the Alignment/Uniformity perspective of contrastive learning by Wang & Isola (2020) into a distillation objective. We choose this flavor of contrastive learning due to its low computational cost, an overarching theme of this work. We also observe that this phenomenon tends not to occur if the task is data-limited. However, this can be alleviated by leveraging yet another scale-inspired development: large, pre-trained generative models for dataset augmentation. Again, we use an open-source model, and our rudimentary prompts are sufficient to boost the small model`s performance. Thus, we highlight a training method for small models that is up to 94% faster than the standard pre-training paradigm without sacrificing performance. For practitioners discouraged from fully utilizing modern foundation datasets for their small models due to the prohibitive scale, we believe our work keeps that door open.
5/6/2024

Wisdom of Committee: Distilling from Foundation Model to Specialized Application Model
Zichang Liu, Qingyun Liu, Yuening Li, Liang Liu, Anshumali Shrivastava, Shuchao Bi, Lichan Hong, Ed H. Chi, Zhe Zhao
0
0
Recent advancements in foundation models have yielded impressive performance across a wide range of tasks. Meanwhile, for specific applications, practitioners have been developing specialized application models. To enjoy the benefits of both kinds of models, one natural path is to transfer the knowledge in foundation models into specialized application models, which are generally more efficient for serving. Techniques from knowledge distillation may be applied here, where the application model learns to mimic the foundation model. However, specialized application models and foundation models have substantial gaps in capacity, employing distinct architectures, using different input features from different modalities, and being optimized on different distributions. These differences in model characteristics lead to significant challenges for distillation methods. In this work, we propose creating a teaching committee comprising both foundation model teachers and complementary teachers. Complementary teachers possess model characteristics akin to the student's, aiming to bridge the gap between the foundation model and specialized application models for a smoother knowledge transfer. Further, to accommodate the dissimilarity among the teachers in the committee, we introduce DiverseDistill, which allows the student to understand the expertise of each teacher and extract task knowledge. Our evaluations demonstrate that adding complementary teachers enhances student performance. Finally, DiverseDistill consistently outperforms baseline distillation methods, regardless of the teacher choices, resulting in significantly improved student performance.
5/16/2024