A Comprehensive View of Personalized Federated Learning on Heterogeneous Clinical Datasets

0
Sign in to get full access
Overview
- This paper presents FENDA-FL, a personalized federated learning approach for healthcare applications with heterogeneous clinical datasets.
- Federated learning allows training machine learning models on decentralized data without sharing the raw data.
- FENDA-FL aims to improve model performance on individual clients by adapting to their unique data distributions.
Plain English Explanation
FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets is a new approach to federated learning that can create more personalized models for individual healthcare providers.
Federated learning is a technique that allows machine learning models to be trained across multiple devices or organizations without the raw data ever leaving those locations. This is important for healthcare, where patient data privacy is critical.
However, traditional federated learning approaches have struggled when the data from each location is quite different, which is common in healthcare. FENDA-FL addresses this by adapting the global model to better fit the unique data distribution of each individual healthcare provider.
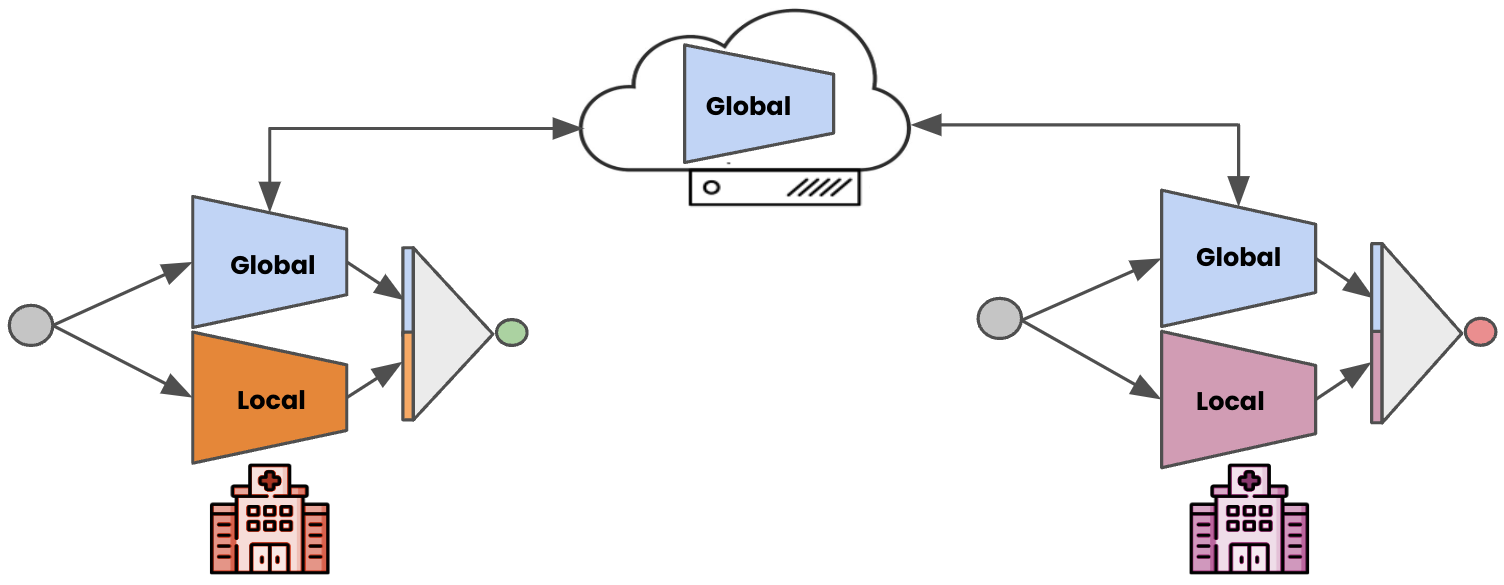
This personalization is achieved through a multi-level process. First, the model is trained on the aggregate data from all providers. Then, the global model is further fine-tuned on each provider's local data. Finally, a provider-specific model head is learned to adapt the global model to each provider's needs.
The researchers show that FENDA-FL outperforms standard federated learning approaches, especially when the data is highly heterogeneous across providers. This suggests FENDA-FL could be a valuable tool for deploying accurate and privacy-preserving machine learning models in the healthcare industry.
Technical Explanation
FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets introduces a novel personalized federated learning framework called FENDA-FL to address the challenge of training accurate models on decentralized, heterogeneous healthcare data.
The key components of FENDA-FL include:
-
Global Model Training: A base model is trained on the aggregate data from all participating healthcare providers.
-
Local Fine-Tuning: The global model is then fine-tuned on each provider's local data to adapt it to their unique data distribution.
-
Provider-Specific Model Head: A separate model head is learned for each provider to further personalize the global model to their needs.
The researchers evaluate FENDA-FL on several healthcare classification tasks using real-world datasets that exhibit high heterogeneity across providers. They show that FENDA-FL significantly outperforms standard federated learning approaches, as well as centralized training on pooled data.
The personalization achieved by FENDA-FL is particularly important in healthcare, where data can vary widely across institutions due to differences in patient populations, clinical practices, and data collection processes. By adapting the global model to each provider's local characteristics, FENDA-FL is able to deliver more accurate and useful predictions for individual healthcare organizations.
Critical Analysis
The FENDA-FL paper provides a robust evaluation of the proposed approach, including comparisons to several baseline federated learning methods. The results demonstrate the clear benefits of the personalization strategy, especially in the presence of high data heterogeneity.
However, the paper does not discuss some potential limitations or areas for future work. For example, it would be interesting to understand how FENDA-FL scales as the number of participating providers increases, and whether there are any communication or computational bottlenecks that may arise.
Additionally, the paper focuses solely on classification tasks, but many real-world healthcare applications also involve regression or other problem types. Extending FENDA-FL to handle a broader range of machine learning problems could further enhance its practical utility.
Finally, while the paper highlights the importance of preserving patient privacy, it does not provide any empirical analysis of the privacy-preserving properties of FENDA-FL compared to other federated learning approaches. Quantifying the privacy guarantees would help readers better understand the tradeoffs and limitations of the proposed method.
Overall, the FENDA-FL paper presents a compelling personalized federated learning solution for healthcare applications, but further research could explore its scalability, generalizability, and privacy implications in more depth.
Conclusion
FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets introduces a novel approach to federated learning that can create more personalized machine learning models for individual healthcare providers. By adapting a global model to each provider's unique data distribution, FENDA-FL is able to deliver superior predictive performance compared to standard federated learning techniques.
This personalization capability is particularly valuable in the healthcare domain, where data can vary significantly across institutions due to differences in patient populations, clinical practices, and data collection processes. FENDA-FL's ability to address these challenges while preserving patient privacy makes it a promising solution for deploying accurate and useful machine learning models in real-world healthcare settings.
While the paper provides a strong technical foundation and empirical validation of FENDA-FL, further research could explore its scalability, generalizability, and quantifiable privacy guarantees. Nonetheless, this work represents an important step forward in developing personalized, privacy-preserving machine learning solutions for the healthcare industry.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Comprehensive View of Personalized Federated Learning on Heterogeneous Clinical Datasets
Fatemeh Tavakoli, D. B. Emerson, Sana Ayromlou, John Jewell, Amrit Krishnan, Yuchong Zhang, Amol Verma, Fahad Razak
Federated learning (FL) is increasingly being recognized as a key approach to overcoming the data silos that so frequently obstruct the training and deployment of machine-learning models in clinical settings. This work contributes to a growing body of FL research specifically focused on clinical applications along three important directions. First, we expand the FLamby benchmark (du Terrail et al., 2022a) to include a comprehensive evaluation of personalized FL methods and demonstrate substantive performance improvements over the original results. Next, we advocate for a comprehensive checkpointing and evaluation framework for FL to reflect practical settings and provide multiple comparison baselines. To this end, an open-source library aimed at making FL experimentation simpler and more reproducible is released. Finally, we propose an important ablation of PerFCL (Zhang et al., 2022). This ablation results in a natural extension of FENDA (Kim et al., 2016) to the FL setting. Experiments conducted on the FLamby benchmark and GEMINI datasets (Verma et al., 2017) show that the proposed approach is robust to heterogeneous clinical data and often outperforms existing global and personalized FL techniques, including PerFCL.
Read more7/8/2024
📶
0
Personalized Federated Learning Techniques: Empirical Analysis
Azal Ahmad Khan, Ahmad Faraz Khan, Haider Ali, Ali Anwar
Personalized Federated Learning (pFL) holds immense promise for tailoring machine learning models to individual users while preserving data privacy. However, achieving optimal performance in pFL often requires a careful balancing act between memory overhead costs and model accuracy. This paper delves into the trade-offs inherent in pFL, offering valuable insights for selecting the right algorithms for diverse real-world scenarios. We empirically evaluate ten prominent pFL techniques across various datasets and data splits, uncovering significant differences in their performance. Our study reveals interesting insights into how pFL methods that utilize personalized (local) aggregation exhibit the fastest convergence due to their efficiency in communication and computation. Conversely, fine-tuning methods face limitations in handling data heterogeneity and potential adversarial attacks while multi-objective learning methods achieve higher accuracy at the cost of additional training and resource consumption. Our study emphasizes the critical role of communication efficiency in scaling pFL, demonstrating how it can significantly affect resource usage in real-world deployments.
Read more9/12/2024
📊
0
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
Read more5/13/2024

0
On the Impact of Data Heterogeneity in Federated Learning Environments with Application to Healthcare Networks
Usevalad Milasheuski, Luca Barbieri, Bernardo Camajori Tedeschini, Monica Nicoli, Stefano Savazzi
Federated Learning (FL) allows multiple privacy-sensitive applications to leverage their dataset for a global model construction without any disclosure of the information. One of those domains is healthcare, where groups of silos collaborate in order to generate a global predictor with improved accuracy and generalization. However, the inherent challenge lies in the high heterogeneity of medical data, necessitating sophisticated techniques for assessment and compensation. This paper presents a comprehensive exploration of the mathematical formalization and taxonomy of heterogeneity within FL environments, focusing on the intricacies of medical data. In particular, we address the evaluation and comparison of the most popular FL algorithms with respect to their ability to cope with quantity-based, feature and label distribution-based heterogeneity. The goal is to provide a quantitative evaluation of the impact of data heterogeneity in FL systems for healthcare networks as well as a guideline on FL algorithm selection. Our research extends beyond existing studies by benchmarking seven of the most common FL algorithms against the unique challenges posed by medical data use cases. The paper targets the prediction of the risk of stroke recurrence through a set of tabular clinical reports collected by different federated hospital silos: data heterogeneity frequently encountered in this scenario and its impact on FL performance are discussed.
Read more9/6/2024