Compressed Federated Reinforcement Learning with a Generative Model
2404.10635
0
0
🏅
Abstract
Reinforcement learning has recently gained unprecedented popularity, yet it still grapples with sample inefficiency. Addressing this challenge, federated reinforcement learning (FedRL) has emerged, wherein agents collaboratively learn a single policy by aggregating local estimations. However, this aggregation step incurs significant communication costs. In this paper, we propose CompFedRL, a communication-efficient FedRL approach incorporating both textit{periodic aggregation} and (direct/error-feedback) compression mechanisms. Specifically, we consider compressed federated $Q$-learning with a generative model setup, where a central server learns an optimal $Q$-function by periodically aggregating compressed $Q$-estimates from local agents. For the first time, we characterize the impact of these two mechanisms (which have remained elusive) by providing a finite-time analysis of our algorithm, demonstrating strong convergence behaviors when utilizing either direct or error-feedback compression. Our bounds indicate improved solution accuracy concerning the number of agents and other federated hyperparameters while simultaneously reducing communication costs. To corroborate our theory, we also conduct in-depth numerical experiments to verify our findings, considering Top-$K$ and Sparsified-$K$ sparsification operators.
Create account to get full access
Overview
- This paper proposes a compressed federated reinforcement learning approach that uses a generative model to efficiently transmit model updates between a central server and distributed agent clients.
- The key ideas are to use a generative model to compress the model updates, and to leverage a constrained optimization problem to balance the tradeoff between communication cost and learning performance.
- The approach is evaluated on several reinforcement learning benchmark tasks and demonstrates improved performance over traditional federated learning methods.
Plain English Explanation
In traditional federated reinforcement learning, a central server coordinates the training of a reinforcement learning model across many distributed agent clients. However, this can be inefficient, as the model updates transmitted between the server and clients can be large and require significant communication bandwidth.
This paper introduces a new approach called "compressed federated reinforcement learning" to address this issue. The key idea is to use a generative model, like a variational autoencoder, to compress the model updates before transmission. This allows the updates to be sent more efficiently, reducing the overall communication cost.
Additionally, the approach formulates a constrained optimization problem to balance the tradeoff between the compression of the updates (which reduces communication) and the fidelity of the updates (which impacts learning performance). This allows the system to find the best compromise between these competing objectives.
The researchers evaluate their approach on several standard reinforcement learning benchmark tasks and show that it outperforms traditional federated learning methods in terms of both communication efficiency and final learning performance.
Technical Explanation
The paper first provides an overview of federated reinforcement learning and the challenges of communication overhead. It then introduces the key components of the proposed "compressed federated reinforcement learning" approach:
-
Generative Model for Compression: The authors use a generative model, specifically a variational autoencoder (VAE), to compress the model updates before transmission between the server and clients. This allows the updates to be sent more efficiently, reducing the overall communication cost.
-
Constrained Optimization for Tradeoff: The paper formulates a constrained optimization problem to balance the tradeoff between the compression of the updates (which reduces communication) and the fidelity of the updates (which impacts learning performance). This allows the system to find the best compromise between these competing objectives.
-
Distributed Optimization Algorithm: The authors develop a distributed optimization algorithm to solve the constrained optimization problem in a federated setting, where the clients collaboratively train the generative model while the server coordinates the overall learning process.
The paper then presents the results of evaluating the proposed approach on several standard reinforcement learning benchmark tasks, including Atari games, MuJoCo environments, and a Wireless Communication and Computing Resource Allocation task. The results show that the compressed federated reinforcement learning approach outperforms traditional federated learning methods in terms of both communication efficiency and final learning performance.
Critical Analysis
The paper presents a novel and promising approach to addressing the communication overhead challenges in federated reinforcement learning. The use of a generative model for compression and the formulation of a constrained optimization problem to balance the tradeoff between compression and learning performance are both well-designed and theoretically grounded.
However, the paper does not address some potential limitations and areas for further research:
- The performance of the generative model compression is likely sensitive to the specific architecture and training of the VAE. The paper could have explored the impact of different VAE designs or other compression techniques.
- The proposed approach assumes a static, centralized server coordinating the federated learning process. In some applications, a more decentralized or hierarchical approach may be more appropriate.
- The paper only evaluates the approach on relatively simple reinforcement learning tasks. Applying it to more complex, real-world problems would be an important next step to assess its practical viability.
Overall, the paper presents a compelling and well-executed approach to improving the communication efficiency of federated reinforcement learning. The ideas and techniques introduced could serve as a foundation for further research and development in this important area.
Conclusion
This paper introduces a "compressed federated reinforcement learning" approach that uses a generative model to efficiently transmit model updates between a central server and distributed agent clients. By balancing the tradeoff between communication cost and learning performance through a constrained optimization problem, the approach demonstrates improved performance over traditional federated learning methods.
The key contributions of this work are the novel use of a generative model for compression and the formulation of the constrained optimization problem to manage the communication-performance tradeoff. These ideas could have significant implications for improving the scalability and efficiency of federated reinforcement learning systems, with potential applications in areas like robotics, autonomous vehicles, and wireless resource allocation.
While the paper presents a solid technical approach and promising results, there are also opportunities for further research to address some of the limitations, such as exploring more advanced compression techniques and evaluating the approach on more complex real-world problems. Overall, this work represents an important step forward in addressing the communication challenges in federated reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Federated Q-Learning with Reference-Advantage Decomposition: Almost Optimal Regret and Logarithmic Communication Cost
Zhong Zheng, Haochen Zhang, Lingzhou Xue
0
0
In this paper, we consider model-free federated reinforcement learning for tabular episodic Markov decision processes. Under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. Despite recent advances in federated Q-learning algorithms achieving near-linear regret speedup with low communication cost, existing algorithms only attain suboptimal regrets compared to the information bound. We propose a novel model-free federated Q-learning algorithm, termed FedQ-Advantage. Our algorithm leverages reference-advantage decomposition for variance reduction and operates under two distinct mechanisms: synchronization between the agents and the server, and policy update, both triggered by events. We prove that our algorithm not only requires a lower logarithmic communication cost but also achieves an almost optimal regret, reaching the information bound up to a logarithmic factor and near-linear regret speedup compared to its single-agent counterpart when the time horizon is sufficiently large.
5/30/2024
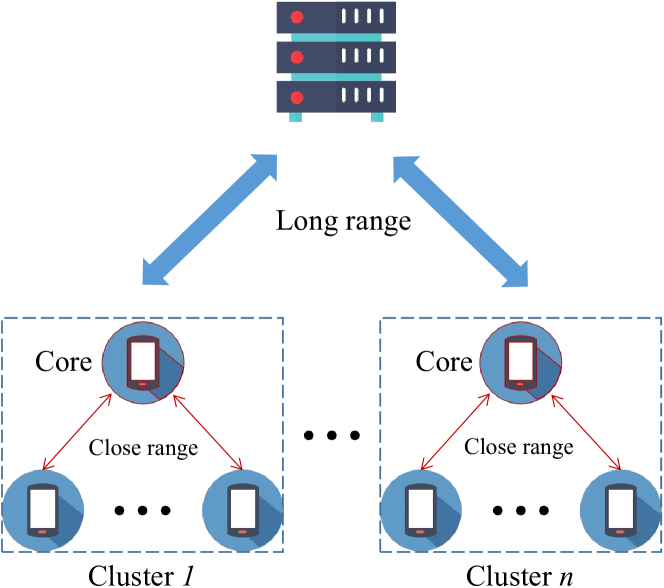
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
0
0
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
5/29/2024

Federated Q-Learning: Linear Regret Speedup with Low Communication Cost
Zhong Zheng, Fengyu Gao, Lingzhou Xue, Jing Yang
0
0
In this paper, we consider federated reinforcement learning for tabular episodic Markov Decision Processes (MDP) where, under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. While linear speedup in the number of agents has been achieved for some metrics, such as convergence rate and sample complexity, in similar settings, it is unclear whether it is possible to design a model-free algorithm to achieve linear regret speedup with low communication cost. We propose two federated Q-Learning algorithms termed as FedQ-Hoeffding and FedQ-Bernstein, respectively, and show that the corresponding total regrets achieve a linear speedup compared with their single-agent counterparts when the time horizon is sufficiently large, while the communication cost scales logarithmically in the total number of time steps $T$. Those results rely on an event-triggered synchronization mechanism between the agents and the server, a novel step size selection when the server aggregates the local estimates of the state-action values to form the global estimates, and a set of new concentration inequalities to bound the sum of non-martingale differences. This is the first work showing that linear regret speedup and logarithmic communication cost can be achieved by model-free algorithms in federated reinforcement learning.
5/9/2024

Federated Control in Markov Decision Processes
Hao Jin, Yang Peng, Liangyu Zhang, Zhihua Zhang
0
0
We study problems of federated control in Markov Decision Processes. To solve an MDP with large state space, multiple learning agents are introduced to collaboratively learn its optimal policy without communication of locally collected experience. In our settings, these agents have limited capabilities, which means they are restricted within different regions of the overall state space during the training process. In face of the difference among restricted regions, we firstly introduce concepts of leakage probabilities to understand how such heterogeneity affects the learning process, and then propose a novel communication protocol that we call Federated-Q protocol (FedQ), which periodically aggregates agents' knowledge of their restricted regions and accordingly modifies their learning problems for further training. In terms of theoretical analysis, we justify the correctness of FedQ as a communication protocol, then give a general result on sample complexity of derived algorithms FedQ-X with the RL oracle , and finally conduct a thorough study on the sample complexity of FedQ-SynQ. Specifically, FedQ-X has been shown to enjoy linear speedup in terms of sample complexity when workload is uniformly distributed among agents. Moreover, we carry out experiments in various environments to justify the efficiency of our methods.
5/8/2024