Quantifying the Capabilities of LLMs across Scale and Precision
2405.03146
0
0
🤔
Abstract
Scale is often attributed as one of the factors that cause an increase in the performance of LLMs, resulting in models with billion and trillion parameters. One of the limitations of such large models is the high computational requirements that limit their usage, deployment, and debugging in resource-constrained scenarios. Two commonly used alternatives to bypass these limitations are to use the smaller versions of LLMs (e.g. Llama 7B instead of Llama 70B) and lower the memory requirements by using quantization. While these approaches effectively address the limitation of resources, their impact on model performance needs thorough examination. In this study, we perform a comprehensive evaluation to investigate the effect of model scale and quantization on the performance. We experiment with two major families of open-source instruct models ranging from 7 billion to 70 billion parameters. Our extensive zero-shot experiments across various tasks including natural language understanding, reasoning, misinformation detection, and hallucination reveal that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. We found that larger models show exceptional resilience to precision reduction and can maintain high accuracy even at 4-bit quantization for numerous tasks and they serve as a better solution than using smaller models at high precision under similar memory requirements.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) with billions or trillions of parameters can have high performance, but also high computational requirements that limit their usage and deployment.
- Alternatives like using smaller versions of LLMs or quantizing (reducing precision of) the models can address resource constraints, but their impact on performance needs examination.
- This study comprehensively evaluates the effect of model scale and quantization on performance across various tasks.
Plain English Explanation
The researchers investigated how the size and precision of large language models impact their performance. Large models with billions or even trillions of parameters can achieve impressive results, but they also require a lot of computing power. This can make it difficult to use and deploy these models, especially in situations with limited resources.
To address this, the researchers looked at two common workarounds: using smaller versions of the models (e.g. Llama 7B instead of Llama 70B) and reducing the precision or "bitwidth" of the model parameters through a process called quantization. While these approaches can help with resource constraints, the researchers wanted to understand how they impact the model's performance.
They conducted extensive experiments across a variety of tasks, including natural language understanding, reasoning, misinformation detection, and hallucination. The key finding was that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. Interestingly, the researchers also discovered that the larger models showed exceptional resilience to precision reduction - they could maintain high accuracy even when the model parameters were quantized down to just 4 bits. This means that using a larger model with reduced precision can be a better solution than using a smaller model at high precision, while still meeting memory requirements.
Technical Explanation
The researchers conducted experiments with two major families of open-source "instruct" models, ranging from 7 billion to 70 billion parameters. They performed zero-shot evaluations across a diverse set of tasks, including natural language understanding, reasoning, misinformation detection, and hallucination.
The results showed that larger models generally outperformed their smaller counterparts, indicating that scale remains a crucial factor in enhancing model performance. Notably, the researchers found that the larger models demonstrated exceptional resilience to precision reduction. These models could maintain high accuracy even when their parameters were quantized down to 4-bit precision for numerous tasks.
This suggests that using a larger model with reduced precision can be a more effective solution than employing a smaller model at high precision, while still meeting memory constraints. The findings presented in this study provide valuable insights into the trade-offs between model scale, quantization, and performance, which can inform the deployment of large language models in resource-constrained scenarios.
Critical Analysis
The researchers acknowledge that their study focuses on the specific task domains and model families examined, and that the findings may not generalize to all possible use cases or model architectures. Additionally, they note that the impact of quantization on the models' uncertainty and calibration was not explicitly explored in this work, which could be an interesting avenue for future research (Benchmarking LLMs via Uncertainty Quantification).
One potential limitation of the study is that it does not delve into the underlying mechanisms or explanations for the observed resilience of larger models to precision reduction. Further investigation into the specific factors or architectural properties that contribute to this behavior could provide deeper insights (When Quantization Affects Confidence in Large Language Models).
Additionally, the researchers do not explore the potential tradeoffs between model size, quantization, and inference latency, which could be a relevant consideration for real-world deployment scenarios. A more comprehensive analysis that considers these additional performance metrics would be valuable (Accurate and Efficient Low-Bitwidth Quantization of Large Language Models).
Conclusion
This study provides important insights into the relationship between model scale, quantization, and performance for large language models. The key finding is that larger models generally outperform their smaller counterparts, and that they exhibit remarkable resilience to precision reduction, maintaining high accuracy even with significant quantization.
These results suggest that using a larger model with reduced precision can be a more effective solution than employing a smaller model at high precision, while still meeting memory constraints. This has significant implications for the deployment of large language models in resource-constrained scenarios, as it opens up the possibility of leveraging the capabilities of these powerful models in a wide range of applications and settings.
The insights from this research contribute to our understanding of the tradeoffs and design considerations involved in deploying large language models, and can inform the development of novel techniques and strategies for optimizing model performance and accessibility (Compressibility of Quantized Large Language Models).
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
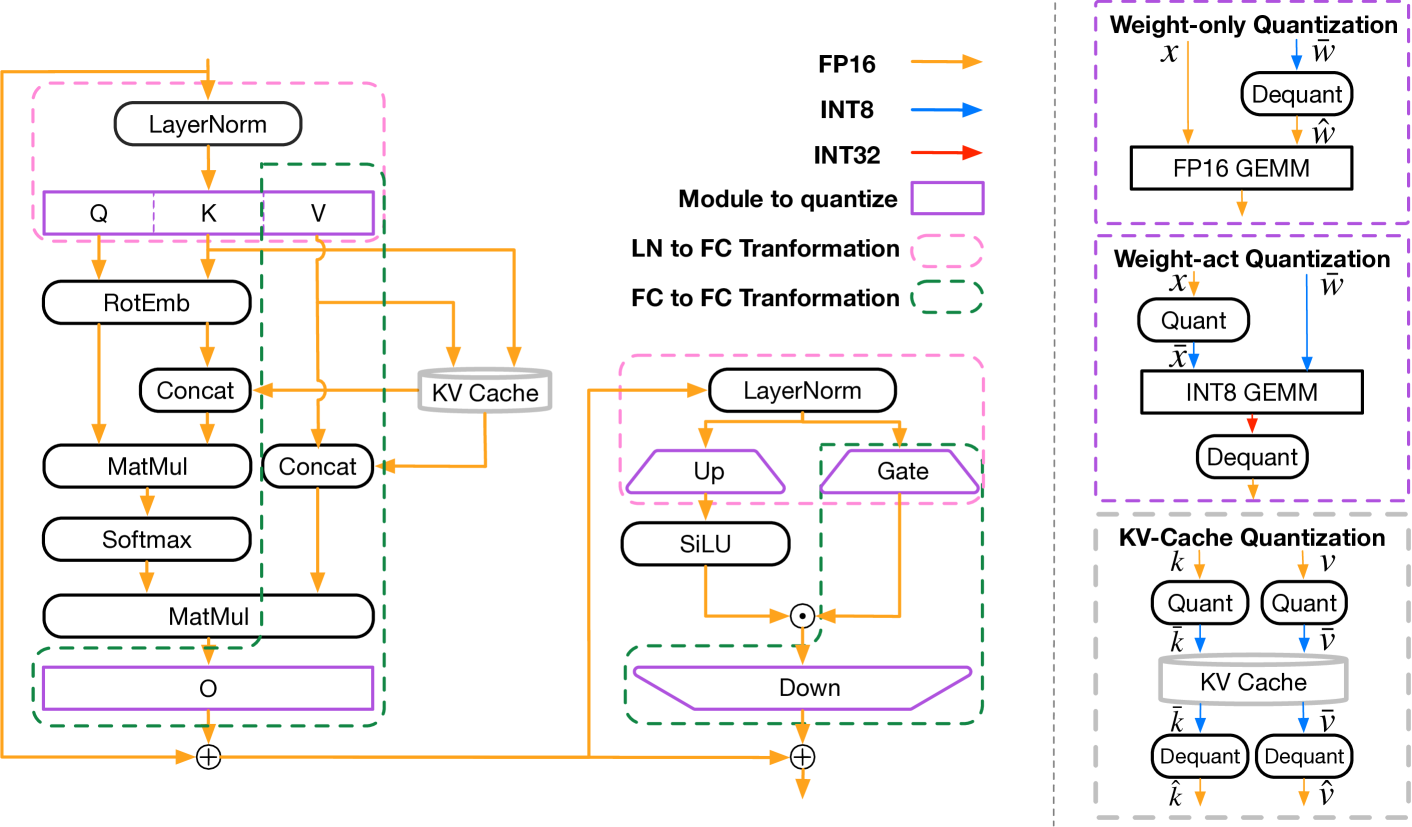
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao
0
0
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
5/13/2024
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024
🐍
Combining multiple post-training techniques to achieve most efficient quantized LLMs
Sayeh Sharify, Zifei Xu, Wanzin Yazar, Xin Wang
0
0
Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges. This paper explores the potential of quantization to mitigate these challenges. We systematically study the combined application of two well-known post-training techniques, SmoothQuant and GPTQ, and provide a comprehensive analysis of their interactions and implications for advancing LLM quantization. We enhance the versatility of both techniques by enabling quantization to microscaling (MX) formats, expanding their applicability beyond their initial fixed-point format targets. We show that by applying GPTQ and SmoothQuant, and employing MX formats for quantizing models, we can achieve a significant reduction in the size of OPT models by up to 4x and LLaMA models by up to 3x with a negligible perplexity increase of 1-3%.
5/14/2024
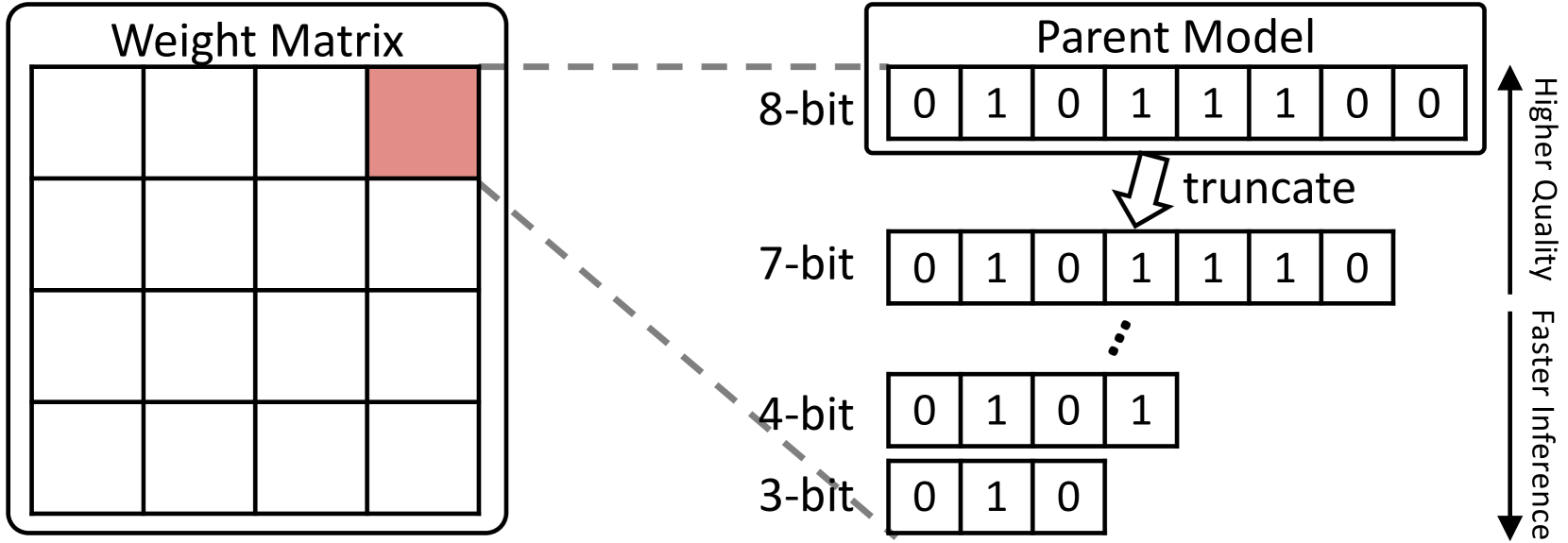
Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
Yeonhong Park, Jake Hyun, SangLyul Cho, Bonggeun Sim, Jae W. Lee
0
0
Recently, considerable efforts have been directed towards compressing Large Language Models (LLMs), which showcase groundbreaking capabilities across diverse applications but entail significant deployment costs due to their large sizes. Meanwhile, much less attention has been given to mitigating the costs associated with deploying multiple LLMs of varying sizes despite its practical significance. Thus, this paper introduces emph{any-precision LLM}, extending the concept of any-precision DNN to LLMs. Addressing challenges in any-precision LLM, we propose a lightweight method for any-precision quantization of LLMs, leveraging a post-training quantization framework, and develop a specialized software engine for its efficient serving. As a result, our solution significantly reduces the high costs of deploying multiple, different-sized LLMs by overlaying LLMs quantized to varying bit-widths, such as 3, 4, ..., $n$ bits, into a memory footprint comparable to a single $n$-bit LLM. All the supported LLMs with varying bit-widths demonstrate state-of-the-art model quality and inference throughput, proving itself to be a compelling option for deployment of multiple, different-sized LLMs. Our code is open-sourced and available online.
5/8/2024