Computational Limits of Low-Rank Adaptation (LoRA) for Transformer-Based Models

0
⚙️
Sign in to get full access
Overview
- This paper introduces a new technique called Batched Low-Rank Adaptation (BLRA) for fine-tuning large language models (LLMs) in a parameter-efficient manner.
- BLRA builds on previous work like LORA, ALORA, and OLORA by adding a novel batching mechanism.
- The key idea is to split the adaptation parameters into smaller "batches" that can be fine-tuned independently, allowing for more parameter-efficient fine-tuning of LLMs.
Plain English Explanation
The paper introduces a new technique called Batched Low-Rank Adaptation (BLRA) that can help fine-tune large language models (LLMs) more efficiently. LLMs are massive AI models that have been trained on huge amounts of data and can perform a wide variety of language tasks. However, to use an LLM for a specific task, it often needs to be fine-tuned on a smaller dataset relevant to that task.
Previous methods like LORA, ALORA, and OLORA have shown that you can fine-tune LLMs in a more parameter-efficient way by only updating a small subset of the model's parameters. BLRA builds on these ideas by further splitting the adaptation parameters into smaller "batches" that can be fine-tuned independently.
The key advantage of BLRA is that it allows for more flexibility in how the fine-tuning parameters are allocated, which can lead to better performance on specific tasks compared to previous methods. By fine-tuning the model in smaller batches, BLRA can potentially capture more nuanced relationships in the data without requiring as many overall parameters to be updated.
Technical Explanation
The paper proposes a new technique called Batched Low-Rank Adaptation (BLRA) for fine-tuning large language models (LLMs) in a parameter-efficient manner. BLRA builds on previous work like LORA, ALORA, and OLORA, which have shown that low-rank adaptation can be an effective way to fine-tune LLMs without modifying the main model parameters.
The key innovation in BLRA is the addition of a batching mechanism. Instead of updating a single set of low-rank adaptation parameters, BLRA splits the adaptation parameters into multiple "batches" that can be fine-tuned independently. This allows for more flexible allocation of the adaptation parameters, which the authors hypothesize can lead to better performance on specific tasks compared to previous low-rank adaptation methods.
The paper presents a detailed experimental evaluation of BLRA on a range of language tasks, including text classification, question answering, and natural language inference. The results show that BLRA can achieve competitive or better performance compared to full fine-tuning of the LLM, while using significantly fewer parameters. For example, on the GLUE benchmark, BLRA achieved 88.0% of the performance of full fine-tuning while only updating 0.67% of the model parameters.
Critical Analysis
The BLRA paper provides a solid technical contribution by building on previous work in parameter-efficient fine-tuning of large language models. The batching mechanism introduced in BLRA is a clever way to add more flexibility to the adaptation process, which the results suggest can lead to improved performance in certain cases.
That said, the paper does not delve deeply into the underlying reasons why the batching approach is beneficial. It would be helpful to have a more thorough analysis of how the batched adaptation parameters interact with the main model, and why the specific batching strategy used in BLRA is effective. Additionally, the paper only evaluates BLRA on a limited set of tasks, so further testing on a wider range of applications would strengthen the conclusions.
Another potential limitation is the reliance on low-rank adaptation in general. While this approach has shown promise, it fundamentally imposes constraints on the type of adaptations that can be learned. It's possible that other parameter-efficient fine-tuning techniques, such as those based on sparse or modular updates, could provide complementary advantages that are worth exploring.
Overall, the BLRA paper makes a useful contribution to the field of parameter-efficient fine-tuning, but there is still room for further research to fully understand the strengths and limitations of this approach.
Conclusion
The Batched Low-Rank Adaptation (BLRA) technique introduced in this paper represents an interesting advancement in the field of parameter-efficient fine-tuning of large language models. By splitting the adaptation parameters into smaller batches, BLRA provides more flexibility in how the model is updated, which can lead to improved performance on specific tasks compared to previous low-rank adaptation methods.
The experimental results demonstrate the potential of BLRA, showing that it can achieve competitive task performance while updating only a small fraction of the model parameters. This has important implications for making large language models more accessible and usable in resource-constrained environments, such as on edge devices or in low-power settings.
While the paper lays a solid foundation, further research is needed to fully understand the strengths and limitations of the BLRA approach. Exploring the underlying reasons for its effectiveness, evaluating it on a wider range of tasks, and comparing it to other parameter-efficient fine-tuning techniques could all yield valuable insights. Nonetheless, the BLRA paper represents an important step forward in the ongoing quest to make large language models more flexible, efficient, and widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Computational Limits of Low-Rank Adaptation (LoRA) for Transformer-Based Models
Jerry Yao-Chieh Hu, Maojiang Su, En-Jui Kuo, Zhao Song, Han Liu
We study the computational limits of Low-Rank Adaptation (LoRA) update for finetuning transformer-based models using fine-grained complexity theory. Our key observation is that the existence of low-rank decompositions within the gradient computation of LoRA adaptation leads to possible algorithmic speedup. This allows us to (i) identify a phase transition behavior and (ii) prove the existence of nearly linear algorithms by controlling the LoRA update computation term by term, assuming the Strong Exponential Time Hypothesis (SETH). For the former, we identify a sharp transition in the efficiency of all possible rank-$r$ LoRA update algorithms for transformers, based on specific norms resulting from the multiplications of the input sequence $mathbf{X}$, pretrained weights $mathbf{W^star}$, and adapter matrices $alpha mathbf{B} mathbf{A} / r$. Specifically, we derive a shared upper bound threshold for such norms and show that efficient (sub-quadratic) approximation algorithms of LoRA exist only below this threshold. For the latter, we prove the existence of nearly linear approximation algorithms for LoRA adaptation by utilizing the hierarchical low-rank structures of LoRA gradients and approximating the gradients with a series of chained low-rank approximations. To showcase our theory, we consider two practical scenarios: partial (e.g., only $mathbf{W}_V$ and $mathbf{W}_Q$) and full adaptations (e.g., $mathbf{W}_Q$, $mathbf{W}_V$, and $mathbf{W}_K$) of weights in attention heads.
Read more6/6/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024
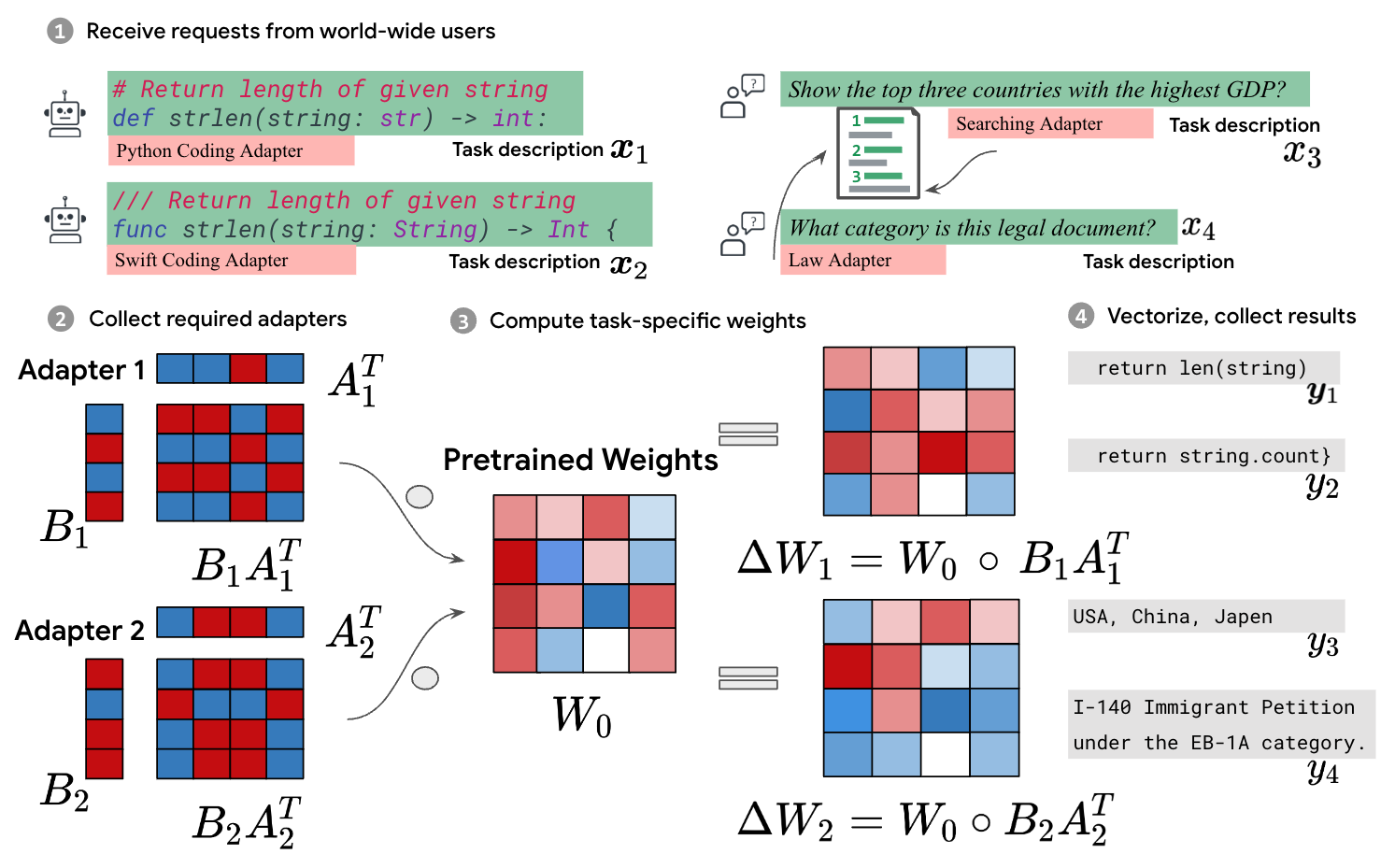
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
0
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
Read more4/16/2024