Computational Sentence-level Metrics Predicting Human Sentence Comprehension
2403.15822
0
0

Abstract
The majority of research in computational psycholinguistics has concentrated on the processing of words. This study introduces innovative methods for computing sentence-level metrics using multilingual large language models. The metrics developed sentence surprisal and sentence relevance and then are tested and compared to validate whether they can predict how humans comprehend sentences as a whole across languages. These metrics offer significant interpretability and achieve high accuracy in predicting human sentence reading speeds. Our results indicate that these computational sentence-level metrics are exceptionally effective at predicting and elucidating the processing difficulties encountered by readers in comprehending sentences as a whole across a variety of languages. Their impressive performance and generalization capabilities provide a promising avenue for future research in integrating LLMs and cognitive science.
Create account to get full access
Overview
- The paper explores computational metrics that can predict human sentence comprehension.
- It investigates how well various linguistic features and machine learning models can estimate human understanding of sentences.
- The goal is to develop automated methods for evaluating text complexity and readability.
Plain English Explanation
This research paper looks at ways to measure how easy or difficult it is for people to understand different sentences. The researchers wanted to find computational methods that could predict how well humans would comprehend various sentences.
By analyzing linguistic features of sentences, like word complexity, sentence structure, and contextual information, the researchers tested different machine learning models to see how accurately they could estimate human understanding of those sentences. The aim is to develop automated tools that can evaluate text complexity and readability without relying solely on human judgments.
Technical Explanation
The paper examines a range of computational metrics that could potentially predict human sentence comprehension. The researchers conducted experiments to assess how well various linguistic features and machine learning models can estimate people's understanding of different sentences.
The study used several datasets that collected human ratings of sentence complexity and difficulty. The researchers then extracted linguistic properties of those sentences, such as word frequency, syntactic structure, and semantic information. They trained regression models to predict the human-provided ratings based on these computational features.
The results showed that models leveraging a combination of linguistic metrics were able to achieve strong correlations with the human comprehension judgments. Factors like word familiarity, sentence length, and semantic richness were found to be particularly informative for predicting sentence complexity.
Critical Analysis
The paper presents a promising approach for automating the assessment of text readability and difficulty. By developing computational models that can estimate human understanding of sentences, the researchers have taken an important step towards creating more scalable and objective ways to evaluate written material.
However, the study also acknowledges some limitations. The datasets used were relatively small, and the sentences were primarily from academic or formal domains. More diverse text sources and larger human evaluation datasets may be needed to build robust, generalizable models.
Additionally, the paper notes that the current approaches focus only on local, sentence-level features. Incorporating higher-level contextual information and discourse-level factors could further improve the predictive power of these computational metrics.
Future research should also explore how these models perform on more challenging, ambiguous, or subjective language, where human comprehension may be more variable and difficult to capture with simple linguistic features.
Conclusion
This research demonstrates the potential for computational methods to serve as proxy measures of human sentence comprehension. By identifying linguistic features that correlate with human judgments of text complexity, the paper lays the groundwork for developing automated tools to evaluate readability and text difficulty.
Such techniques could have important applications in areas like education, content writing, and information accessibility. By providing more objective and scalable ways to assess textual complexity, these computational metrics could help create more effective and inclusive communication.
The findings also suggest promising avenues for further research, such as exploring more diverse data sources, incorporating higher-level contextual cues, and testing the models' performance on a wider range of language use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
0
0
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
7/2/2024
🚀
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Taojun Hu, Xiao-Hua Zhou
0
0
Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
4/16/2024
💬
Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
Huiming Wang, Zhaodonghui Li, Liying Cheng, Soh De Wen, Lidong Bing
0
0
Recently, large language models (LLMs) have emerged as a groundbreaking technology and their unparalleled text generation capabilities have sparked interest in their application to the fundamental sentence representation learning task. Existing methods have explored utilizing LLMs as data annotators to generate synthesized data for training contrastive learning based sentence embedding models such as SimCSE. However, since contrastive learning models are sensitive to the quality of sentence pairs, the effectiveness of these methods is largely influenced by the content generated from LLMs, highlighting the need for more refined generation in the context of sentence representation learning. Building upon this premise, we propose MultiCSR, a multi-level contrastive sentence representation learning framework that decomposes the process of prompting LLMs to generate a corpus for training base sentence embedding models into three stages (i.e., sentence generation, sentence pair construction, in-batch training) and refines the generated content at these three distinct stages, ensuring only high-quality sentence pairs are utilized to train a base contrastive learning model. Our extensive experiments reveal that MultiCSR enables a less advanced LLM to surpass the performance of ChatGPT, while applying it to ChatGPT achieves better state-of-the-art results. Comprehensive analyses further underscore the potential of our framework in various application scenarios and achieving better sentence representation learning with LLMs.
5/20/2024
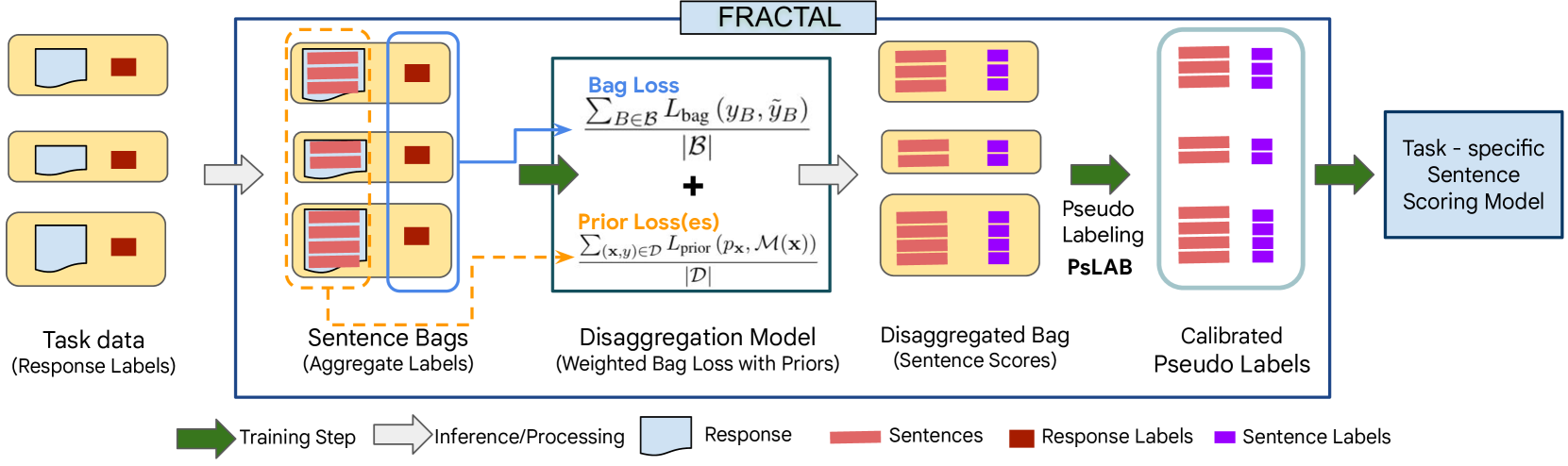
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Yukti Makhija, Priyanka Agrawal, Rishi Saket, Aravindan Raghuveer
0
0
Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
4/9/2024