FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
2404.04817
0
0
Abstract
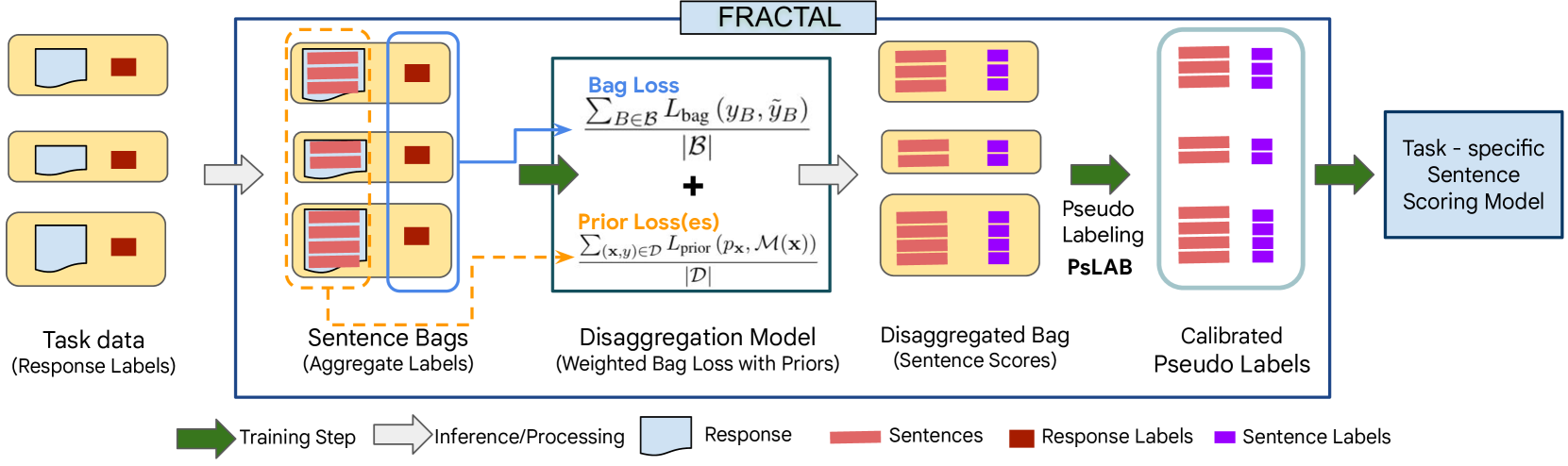
Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
Create account to get full access
Overview
- This paper introduces FRACTAL, a new method for generating fine-grained scoring from aggregate text labels.
- FRACTAL leverages large language models to predict scoring distributions from text, enabling more granular assessment of various attributes.
- The approach is evaluated on a range of tasks, including text classification, confidence scoring, and text regression, demonstrating its versatility.
Plain English Explanation
FRACTAL is a new technique that allows us to get more detailed scores from text data. Normally, when we have text labels like "good" or "bad", we can only get a coarse score. But FRACTAL uses large language models to predict a whole distribution of scores, giving us much more fine-grained and nuanced information.
For example, imagine you have reviews of a product, and the reviews just say "good" or "bad". With FRACTAL, you could get a score distribution that shows the product is mostly good, with a small chance of being mediocre. This is much more useful than a simple binary "good" or "bad" label.
FRACTAL has been tested on all kinds of text-based tasks, like classifying text, estimating confidence scores, and predicting numeric values from text. The key is that it can extract much richer information from text compared to traditional methods.
Technical Explanation
FRACTAL is a novel approach that leverages large language models to generate fine-grained scoring distributions from aggregate text labels. Rather than simply predicting a single score or label, FRACTAL outputs a probability distribution over a range of possible scores.
The core of the FRACTAL method is a neural network architecture that takes in text data and outputs a parameterized scoring distribution. This distribution can then be used to make more nuanced assessments than traditional binary or ordinal labels.
The authors evaluate FRACTAL on a diverse set of text-based tasks, including text classification, confidence scoring, and text regression. In each case, FRACTAL demonstrates improved performance over baseline approaches that rely on coarse-grained labels.
The authors also show that FRACTAL can be applied to spoken language understanding tasks and few-shot learning scenarios, highlighting its versatility.
Critical Analysis
The FRACTAL approach represents an important advance in extracting more granular information from text data. By moving beyond simple binary or ordinal labels, the method enables a richer understanding of the underlying attributes being assessed.
However, the authors acknowledge that FRACTAL requires access to large language models, which can be computationally expensive and may not be available in all settings. Additionally, the method relies on the quality and coverage of the training data, which could introduce biases or limit its applicability to certain domains.
Further research could explore ways to make FRACTAL more efficient and accessible, as well as investigate its robustness to noisy or incomplete data. Evaluating FRACTAL's performance on real-world applications with high-stakes decision-making would also be valuable to understand its practical implications.
Conclusion
FRACTAL is a promising new technique that allows us to extract much more detailed information from text data. By leveraging large language models, it can produce fine-grained scoring distributions instead of coarse labels, enabling more nuanced assessments across a variety of text-based tasks.
While FRACTAL has some limitations in terms of computational requirements and data quality, it represents an important step forward in natural language processing. As large language models continue to advance, techniques like FRACTAL may become increasingly valuable for applications that require a deeper understanding of textual content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
0
0
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
5/2/2024

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
💬
Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
Huiming Wang, Zhaodonghui Li, Liying Cheng, Soh De Wen, Lidong Bing
0
0
Recently, large language models (LLMs) have emerged as a groundbreaking technology and their unparalleled text generation capabilities have sparked interest in their application to the fundamental sentence representation learning task. Existing methods have explored utilizing LLMs as data annotators to generate synthesized data for training contrastive learning based sentence embedding models such as SimCSE. However, since contrastive learning models are sensitive to the quality of sentence pairs, the effectiveness of these methods is largely influenced by the content generated from LLMs, highlighting the need for more refined generation in the context of sentence representation learning. Building upon this premise, we propose MultiCSR, a multi-level contrastive sentence representation learning framework that decomposes the process of prompting LLMs to generate a corpus for training base sentence embedding models into three stages (i.e., sentence generation, sentence pair construction, in-batch training) and refines the generated content at these three distinct stages, ensuring only high-quality sentence pairs are utilized to train a base contrastive learning model. Our extensive experiments reveal that MultiCSR enables a less advanced LLM to surpass the performance of ChatGPT, while applying it to ChatGPT achieves better state-of-the-art results. Comprehensive analyses further underscore the potential of our framework in various application scenarios and achieving better sentence representation learning with LLMs.
5/20/2024
🖼️
Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels
Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, Michael Bendersky
0
0
Zero-shot text rankers powered by recent LLMs achieve remarkable ranking performance by simply prompting. Existing prompts for pointwise LLM rankers mostly ask the model to choose from binary relevance labels like Yes and No. However, the lack of intermediate relevance label options may cause the LLM to provide noisy or biased answers for documents that are partially relevant to the query. We propose to incorporate fine-grained relevance labels into the prompt for LLM rankers, enabling them to better differentiate among documents with different levels of relevance to the query and thus derive a more accurate ranking. We study two variants of the prompt template, coupled with different numbers of relevance levels. Our experiments on 8 BEIR data sets show that adding fine-grained relevance labels significantly improves the performance of LLM rankers.
4/3/2024