On Computing Optimal Tree Ensembles

0
🐍
Sign in to get full access
Overview
- Random forests and decision tree ensembles are widely used for classification and regression tasks.
- Recent advances have enabled the computation of optimal decision trees for various measures like size or depth.
- However, similar research for tree ensembles is lacking, which this paper aims to address.
- The paper presents two novel algorithms and corresponding lower bounds for computing optimal tree ensembles.
Plain English Explanation
Random forests and decision tree ensembles are machine learning models that combine multiple individual decision trees to make more accurate predictions. These models are commonly used for classification and regression tasks.
Recent breakthroughs have made it possible to compute decision trees that are optimal in terms of their size or depth. However, similar advancements for tree ensembles have been lacking. This paper aims to fill that gap by introducing two new algorithms and lower bounds for computing optimal tree ensembles.
The first algorithm can, given a dataset and a size constraint, find a tree ensemble that correctly classifies the data and is no larger than the specified size. This algorithm runs efficiently, taking time that scales with the size of the ensemble, the largest feature domain size, and the maximum number of features that differ between any two examples.
The second algorithm uses dynamic programming to find an optimal tree ensemble, with a runtime that scales with the number of trees in the ensemble. This suggests that dynamic programming may be a viable approach for computing optimal tree ensembles, similar to how it has been successfully applied to decision trees.
Finally, the paper compares the number of "cuts" (decision boundaries) needed to classify a dataset using decision trees versus tree ensembles. It finds that ensembles may require exponentially fewer cuts as the number of trees increases, indicating a potential advantage of using tree ensembles over individual decision trees.
Technical Explanation
The paper presents two novel algorithms for computing optimal tree ensembles:
-
Bounded-size Ensemble Algorithm: This algorithm takes a training dataset and a size bound $S$, and computes a tree ensemble of size at most $S$ that correctly classifies the data. The runtime of this algorithm is $(4\delta D S)^S \cdot \text{poly}$, where $D$ is the largest feature domain size, $\delta$ is the maximum number of features in which two examples differ, $n$ is the number of training examples, and $\text{poly}$ is a polynomial in the input size. For decision trees (ensembles of size 1), the runtime is $({\delta D s})^s \cdot \text{poly}$, where $s$ is the size of the tree.
-
Dynamic Programming Algorithm: The paper shows that dynamic programming, which has been successful for computing optimal decision trees, can also be applied to tree ensembles. This algorithm runs in $\ell^n \cdot \text{poly}$ time, where $\ell$ is the number of trees in the ensemble.
To obtain these algorithms, the paper introduces the "witness-tree" technique, which seems promising for practical implementations.
Additionally, the paper compares the number of cuts (decision boundaries) needed to classify a dataset using decision trees versus tree ensembles. It is shown that tree ensembles may require exponentially fewer cuts as the number of trees increases, suggesting a potential advantage of using tree ensembles over individual decision trees.
Critical Analysis
The paper presents novel algorithms and insights for computing optimal tree ensembles, which is an important and underexplored area of research. The main strengths of the work are:
- The bounded-size ensemble algorithm provides an efficient way to find tree ensembles that are provably optimal in terms of their size.
- The dynamic programming approach suggests that this powerful technique may be extended from decision trees to tree ensembles, opening up new avenues for research.
- The comparison of decision trees and tree ensembles in terms of the number of cuts needed to classify data provides an interesting theoretical perspective on the potential advantages of ensembles.
However, the paper also has some limitations:
- The algorithms and analysis are primarily theoretical, and their practical performance and applicability are not evaluated.
- The paper does not consider other optimality criteria beyond size, such as ensemble accuracy or interpretability, which may be important in real-world applications.
- The comparison of decision trees and ensembles is limited to the number of cuts, and does not explore other relevant metrics like prediction accuracy or model complexity.
Future research could aim to:
- Implement and evaluate the proposed algorithms on real-world datasets to assess their practical utility.
- Extend the algorithms and analysis to consider other optimality criteria for tree ensembles, such as accuracy or interpretability.
- Conduct a more comprehensive empirical comparison of decision trees and tree ensembles, examining a broader range of performance metrics and use cases.
Overall, this paper makes valuable theoretical contributions to the field of optimal tree ensemble computation, but further work is needed to bridge the gap between theory and practice.
Conclusion
This paper presents two novel algorithms for computing optimal tree ensembles, along with corresponding lower bounds. The first algorithm can efficiently find tree ensembles that are bounded in size and correctly classify a given dataset, while the second algorithm uses dynamic programming to find optimal ensembles.
Additionally, the paper compares decision trees and tree ensembles in terms of the number of cuts needed to classify data, finding that ensembles may require exponentially fewer cuts as the number of trees increases. This suggests a potential advantage of using tree ensembles over individual decision trees.
Overall, the paper makes important theoretical advancements in the area of optimal tree ensemble computation, which is a critical yet underexplored field. While the algorithms and insights are primarily theoretical in nature, they lay the groundwork for further research and practical applications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
On Computing Optimal Tree Ensembles
Christian Komusiewicz, Pascal Kunz, Frank Sommer, Manuel Sorge
Random forests and, more generally, (decisionnobreakdash-)tree ensembles are widely used methods for classification and regression. Recent algorithmic advances allow to compute decision trees that are optimal for various measures such as their size or depth. We are not aware of such research for tree ensembles and aim to contribute to this area. Mainly, we provide two novel algorithms and corresponding lower bounds. First, we are able to carry over and substantially improve on tractability results for decision trees: We obtain an algorithm that, given a training-data set and an size bound $S in mathbb{R}$, computes a tree ensemble of size at most $S$ that classifies the data correctly. The algorithm runs in $(4delta D S)^S cdot poly$-time, where $D$ the largest domain size, $delta$ is the largest number of features in which two examples differ, $n$ the number of input examples, and $poly$ a polynomial of the input size. For decision trees, that is, ensembles of size 1, we obtain a running time of $(delta D s)^s cdot poly$, where $s$ is the size of the tree. To obtain these algorithms, we introduce the witness-tree technique, which seems promising for practical implementations. Secondly, we show that dynamic programming, which has been applied successfully to computing decision trees, may also be viable for tree ensembles, providing an $ell^n cdot poly$-time algorithm, where $ell$ is the number of trees. Finally, we compare the number of cuts necessary to classify training data sets for decision trees and tree ensembles, showing that ensembles may need exponentially fewer cuts for increasing number of trees.
Read more9/25/2024
↗️
0
Ensembles of Probabilistic Regression Trees
Alexandre Seiller (APTIKAL), 'Eric Gaussier (APTIKAL), Emilie Devijver (APTIKAL), Marianne Clausel (IECL), Sami Alkhoury
Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
Read more6/21/2024

0
Register Your Forests: Decision Tree Ensemble Optimization by Explicit CPU Register Allocation
Daniel Biebert, Christian Hakert, Kuan-Hsun Chen, Jian-Jia Chen
Bringing high-level machine learning models to efficient and well-suited machine implementations often invokes a bunch of tools, e.g.~code generators, compilers, and optimizers. Along such tool chains, abstractions have to be applied. This leads to not optimally used CPU registers. This is a shortcoming, especially in resource constrained embedded setups. In this work, we present a code generation approach for decision tree ensembles, which produces machine assembly code within a single conversion step directly from the high-level model representation. Specifically, we develop various approaches to effectively allocate registers for the inference of decision tree ensembles. Extensive evaluations of the proposed method are conducted in comparison to the basic realization of C code from the high-level machine learning model and succeeding compilation. The results show that the performance of decision tree ensemble inference can be significantly improved (by up to $approx1.6times$), if the methods are applied carefully to the appropriate scenario.
Read more4/11/2024
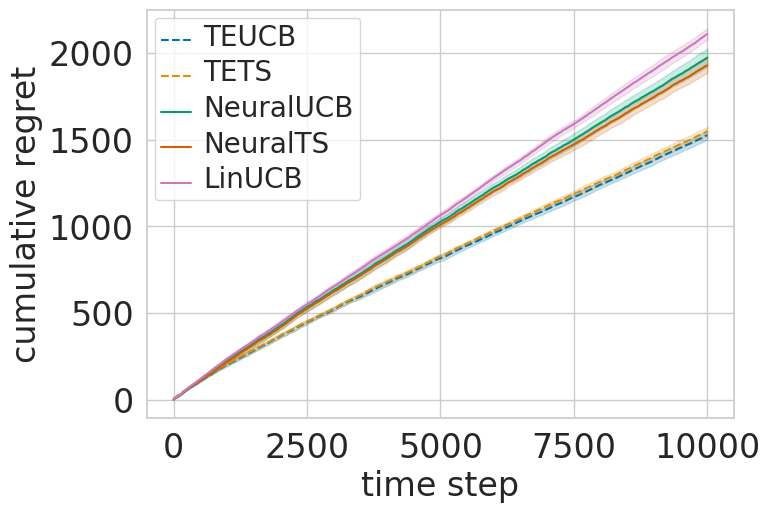
0
Tree Ensembles for Contextual Bandits
Hannes Nilsson, Rikard Johansson, Niklas {AA}kerblom, Morteza Haghir Chehreghani
We propose a novel framework for contextual multi-armed bandits based on tree ensembles. Our framework integrates two widely used bandit methods, Upper Confidence Bound and Thompson Sampling, for both standard and combinatorial settings. We demonstrate the effectiveness of our framework via several experimental studies, employing both XGBoost and random forest, two popular tree ensemble methods. Compared to state-of-the-art methods based on decision trees and neural networks, our methods exhibit superior performance in terms of both regret minimization and computational runtime, when applied to benchmark datasets and the real-world application of navigation over road networks.
Read more7/15/2024