Tree Ensembles for Contextual Bandits

0
Sign in to get full access
Overview
- This paper presents a novel approach to solving contextual bandits problems using tree ensembles.
- Contextual bandits are a type of reinforcement learning problem where an agent must choose actions based on the current context (i.e. the state of the environment) to maximize some reward.
- The authors propose using an ensemble of probabilistic regression trees to model the reward function, which allows for efficient exploration and exploitation.
- The approach is evaluated on several standard contextual bandit benchmarks and shown to outperform existing methods.
Plain English Explanation
The paper discusses a new way to tackle a type of machine learning problem called a "contextual bandit". In a contextual bandit problem, an agent (like a robot or computer program) has to choose actions to take based on the current situation or "context" in order to maximize some kind of reward.
The key innovation in this paper is the use of tree ensembles to model the reward function. Tree ensembles are a collection of decision trees that can learn complex patterns in data. By using an ensemble of these trees, the agent can efficiently explore the space of possible actions while also exploiting what it has already learned to get the highest rewards.
The authors evaluate their approach on several standard benchmark tasks for contextual bandits, and show that it outperforms existing methods. This suggests that their tree ensemble approach is a promising new way to tackle these types of reinforcement learning problems, which have applications in areas like online advertising, recommendation systems, and hyperparameter optimization.
Technical Explanation
The paper proposes using an ensemble of probabilistic regression trees to model the reward function in contextual bandit problems. Probabilistic regression trees are a type of decision tree that can output a probability distribution over the possible rewards, rather than just a single predicted value.
By using an ensemble of these trees, the method can learn a more expressive and flexible model of the reward function. This allows the agent to balance exploration (trying new actions to learn about the environment) and exploitation (taking actions that are predicted to give high rewards).
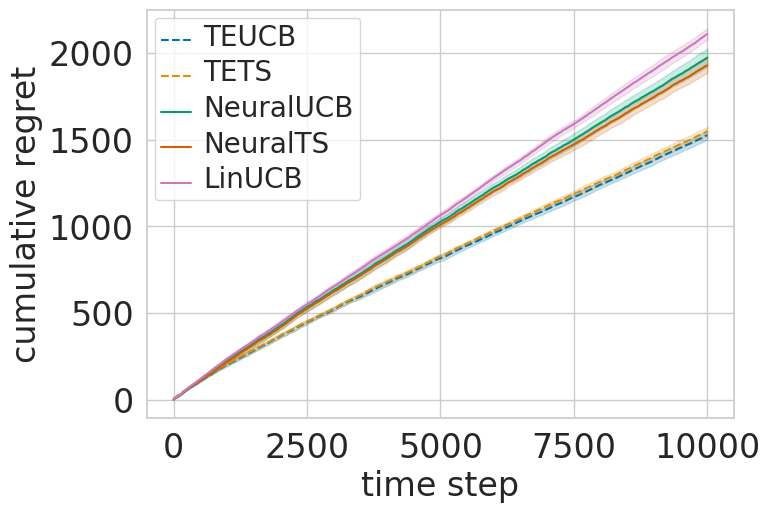
The authors evaluate their approach, called CoBaTree, on several standard contextual bandit benchmark tasks, including linear payoff functions, non-linear payoff functions, and dueling bandits. They show that CoBaTree outperforms existing methods like LinUCB and Thompson Sampling in terms of cumulative reward.
Critical Analysis
The paper provides a thorough evaluation of the CoBaTree method on a variety of contextual bandit benchmarks, which is a strength. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, it's not clear how CoBaTree would scale to very high-dimensional contexts or extremely large action spaces, which are common challenges in real-world applications of contextual bandits. The authors also do not compare CoBaTree to more recent methods like Gaussian Processes for Bandits or Neural Contextual Bandits, which may provide additional insights.
Additionally, the paper does not discuss the computational complexity of CoBaTree or provide any guidance on hyperparameter tuning, which could be important practical considerations.
Conclusion
Overall, this paper presents a novel and promising approach to solving contextual bandit problems using tree ensembles. The empirical results demonstrate the effectiveness of the CoBaTree method compared to existing techniques. However, the authors could have provided a more thorough analysis of the strengths, limitations, and practical considerations of their approach.
The success of CoBaTree suggests that tree-based models may be a fruitful direction for further research in contextual bandits and reinforcement learning more broadly. Future work could explore ways to scale these methods to larger and more complex problem settings, as well as investigate their theoretical properties and robustness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tree Ensembles for Contextual Bandits
Hannes Nilsson, Rikard Johansson, Niklas {AA}kerblom, Morteza Haghir Chehreghani
We propose a novel framework for contextual multi-armed bandits based on tree ensembles. Our framework integrates two widely used bandit methods, Upper Confidence Bound and Thompson Sampling, for both standard and combinatorial settings. We demonstrate the effectiveness of our framework via several experimental studies, employing both XGBoost and random forest, two popular tree ensemble methods. Compared to state-of-the-art methods based on decision trees and neural networks, our methods exhibit superior performance in terms of both regret minimization and computational runtime, when applied to benchmark datasets and the real-world application of navigation over road networks.
Read more7/15/2024

0
Neural Dueling Bandits
Arun Verma, Zhongxiang Dai, Xiaoqiang Lin, Patrick Jaillet, Bryan Kian Hsiang Low
Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
Read more7/25/2024
↗️
0
Ensembles of Probabilistic Regression Trees
Alexandre Seiller (APTIKAL), 'Eric Gaussier (APTIKAL), Emilie Devijver (APTIKAL), Marianne Clausel (IECL), Sami Alkhoury
Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
Read more6/21/2024

0
Meta Clustering of Neural Bandits
Yikun Ban, Yunzhe Qi, Tianxin Wei, Lihui Liu, Jingrui He
The contextual bandit has been identified as a powerful framework to formulate the recommendation process as a sequential decision-making process, where each item is regarded as an arm and the objective is to minimize the regret of $T$ rounds. In this paper, we study a new problem, Clustering of Neural Bandits, by extending previous work to the arbitrary reward function, to strike a balance between user heterogeneity and user correlations in the recommender system. To solve this problem, we propose a novel algorithm called M-CNB, which utilizes a meta-learner to represent and rapidly adapt to dynamic clusters, along with an informative Upper Confidence Bound (UCB)-based exploration strategy. We provide an instance-dependent performance guarantee for the proposed algorithm that withstands the adversarial context, and we further prove the guarantee is at least as good as state-of-the-art (SOTA) approaches under the same assumptions. In extensive experiments conducted in both recommendation and online classification scenarios, M-CNB outperforms SOTA baselines. This shows the effectiveness of the proposed approach in improving online recommendation and online classification performance.
Read more8/13/2024