Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation

0
Sign in to get full access
Overview
- The paper proposes a new approach called "Collaborative Calibration" to improve the confidence calibration and rationalization of large language models (LLMs).
- The key idea is to use a multi-agent deliberation process where multiple LLM agents collaborate to arrive at a more well-calibrated and explainable confidence score.
- The approach aims to address issues with overconfidence and poor calibration in existing LLMs, which can lead to unreliable outputs.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text on a variety of topics. However, these models often struggle with accurately assessing their own confidence in the outputs they produce. They can be overconfident, providing high confidence scores even for incorrect or nonsensical outputs.
The Collaborative Calibration approach aims to address this by having multiple LLM agents work together to arrive at a more reliable confidence score. The agents discuss and deliberate on the input and potential outputs, leveraging their different perspectives to arrive at a final confidence score that is better calibrated to the true uncertainty of the model.
This multi-agent process also helps generate explanations for the model's reasoning, providing transparency into how the confidence score was arrived at. This can be valuable for users who need to understand the basis for an LLM's outputs, rather than just trusting a raw confidence score.
Overall, the Collaborative Calibration approach seeks to make LLMs more reliable and trustworthy by improving their ability to accurately assess their own confidence and explain their reasoning. This could have significant implications for real-world applications of these powerful language models.
Technical Explanation
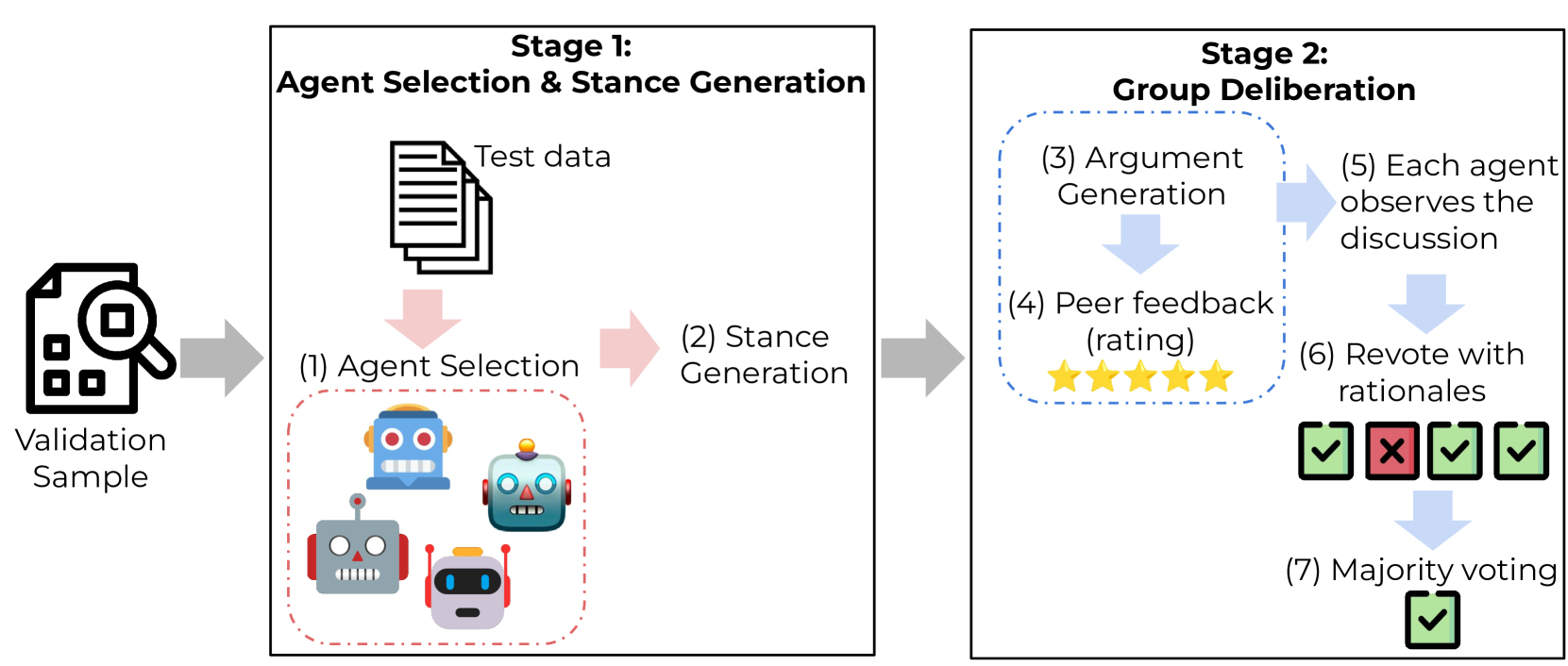
The Collaborative Calibration approach involves a multi-agent system where multiple LLM agents collaborate to arrive at a calibrated confidence score. Each agent generates its own initial confidence score for a given input, and then the agents engage in a deliberation process to reach a consensus.
During the deliberation, the agents share their individual confidence scores and reasoning, and then iteratively adjust their scores based on the input from the other agents. This collaborative process helps to identify and correct overconfident or underconfident assessments, leading to a more well-calibrated final confidence score.
The authors also introduce a rationalization component, where the agents explain the reasoning behind their confidence scores. This provides transparency into the decision-making process and can help users understand the basis for the model's outputs.
The Collaborative Calibration approach is evaluated on a range of natural language tasks, including question answering and text generation. The results demonstrate significant improvements in confidence calibration and rationalization compared to standard LLM approaches.
Critical Analysis
The Collaborative Calibration approach represents an important step forward in addressing the confidence calibration and transparency issues of LLMs. By leveraging a multi-agent deliberation process, the model is able to better assess its own uncertainty and provide more reliable outputs.
However, the authors acknowledge that the approach relies on having multiple LLM agents available, which may not always be the case in real-world deployment scenarios. Additionally, the deliberation process adds computational overhead, which could impact the efficiency and scalability of the system.
There are also open questions around the robustness of the Collaborative Calibration approach, such as how it would perform in the face of adversarial inputs or on more complex or ambiguous tasks. Further research and validation would be needed to fully assess the capabilities and limitations of this approach.
Conclusion
The Collaborative Calibration approach represents an important step forward in improving the reliability and transparency of large language models. By leveraging a multi-agent deliberation process, the model can arrive at better-calibrated confidence scores and provide explanations for its reasoning.
This could have significant implications for real-world applications of LLMs, where accurate and trustworthy outputs are essential. The Collaborative Calibration approach serves as a promising example of how AI systems can be designed to be more reliable and accountable, ultimately enhancing their utility and societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation
Ruixin Yang, Dheeraj Rajagopal, Shirley Anugrah Hayati, Bin Hu, Dongyeop Kang
Uncertainty estimation is a significant issue for current large language models (LLMs) that are generally poorly calibrated and over-confident, especially with reinforcement learning from human feedback (RLHF). Unlike humans, whose decisions and confidences not only stem from intrinsic beliefs but can also be adjusted through daily observations, existing calibration methods for LLMs focus on estimating or eliciting individual confidence without taking full advantage of the Collective Wisdom: the interaction among multiple LLMs that can collectively improve both accuracy and calibration. In this work, we propose Collaborative Calibration, a post-hoc training-free calibration strategy that leverages the collaborative and expressive capabilities of multiple tool-augmented LLM agents in a simulated group deliberation process. We demonstrate the effectiveness of Collaborative Calibration on generative QA tasks across various domains, showing its potential in harnessing the rationalization of collectively calibrated confidence assessments and improving the reliability of model predictions.
Read more5/13/2024

0
Multicalibration for Confidence Scoring in LLMs
Gianluca Detommaso, Martin Bertran, Riccardo Fogliato, Aaron Roth
This paper proposes the use of multicalibration to yield interpretable and reliable confidence scores for outputs generated by large language models (LLMs). Multicalibration asks for calibration not just marginally, but simultaneously across various intersecting groupings of the data. We show how to form groupings for prompt/completion pairs that are correlated with the probability of correctness via two techniques: clustering within an embedding space, and self-annotation - querying the LLM by asking it various yes-or-no questions about the prompt. We also develop novel variants of multicalibration algorithms that offer performance improvements by reducing their tendency to overfit. Through systematic benchmarking across various question answering datasets and LLMs, we show how our techniques can yield confidence scores that provide substantial improvements in fine-grained measures of both calibration and accuracy compared to existing methods.
Read more4/9/2024
🌿
0
Reconfidencing LLMs from the Grouping Loss Perspective
Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gael Varoquaux
Large Language Models (LLMs), including ChatGPT and LLaMA, are susceptible to generating hallucinated answers in a confident tone. While efforts to elicit and calibrate confidence scores have proven useful, recent findings show that controlling uncertainty must go beyond calibration: predicted scores may deviate significantly from the actual posterior probabilities due to the impact of grouping loss. In this work, we construct a new evaluation dataset derived from a knowledge base to assess confidence scores given to answers of Mistral and LLaMA. Experiments show that they tend to be overconfident. Further, we show that they are more overconfident on some answers than others, emph{eg} depending on the nationality of the person in the query. In uncertainty-quantification theory, this is grouping loss. To address this, we propose a solution to reconfidence LLMs, canceling not only calibration but also grouping loss. The LLMs, after the reconfidencing process, indicate improved confidence alignment with the accuracy of their responses.
Read more6/21/2024
🛠️
0
Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
Yang Zhang, Shixin Yang, Chenjia Bai, Fei Wu, Xiu Li, Zhen Wang, Xuelong Li
Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the complexity of the physical world. Especially, LLM planning for multi-agent collaboration requires communication of agents or credit assignment as the feedback to re-adjust the proposed plans and achieve effective coordination. However, existing methods that overly rely on physical verification or self-reflection suffer from excessive and inefficient querying of LLMs. In this paper, we propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans. Specifically, we perform critic regression to learn a sequential advantage function from LLM-planned data, and then treat the LLM planner as an optimizer to generate actions that maximize the advantage function. It endows the LLM with the foresight to discern whether the action contributes to accomplishing the final task. We provide theoretical analysis by extending advantage-weighted regression in reinforcement learning to multi-agent systems. Experiments on Overcooked-AI and a difficult variant of RoCoBench show that ReAd surpasses baselines in success rate, and also significantly decreases the interaction steps of agents and query rounds of LLMs, demonstrating its high efficiency for grounding LLMs. More results are given at https://read-llm.github.io/.
Read more5/28/2024