Multicalibration for Confidence Scoring in LLMs
2404.04689
0
0

Abstract
This paper proposes the use of multicalibration to yield interpretable and reliable confidence scores for outputs generated by large language models (LLMs). Multicalibration asks for calibration not just marginally, but simultaneously across various intersecting groupings of the data. We show how to form groupings for prompt/completion pairs that are correlated with the probability of correctness via two techniques: clustering within an embedding space, and self-annotation - querying the LLM by asking it various yes-or-no questions about the prompt. We also develop novel variants of multicalibration algorithms that offer performance improvements by reducing their tendency to overfit. Through systematic benchmarking across various question answering datasets and LLMs, we show how our techniques can yield confidence scores that provide substantial improvements in fine-grained measures of both calibration and accuracy compared to existing methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new approach called "multicalibration" to improve the confidence scoring of large language models (LLMs).
- Multicalibration aims to ensure that an LLM's confidence scores accurately reflect the true likelihood of the model's predictions being correct.
- The authors propose techniques to train LLMs to be multicalibrated, and demonstrate their methods on several benchmark tasks.
Plain English Explanation
The paper discusses a technique called "multicalibration" to help make large language models (LLMs) more reliable and trustworthy. LLMs are AI systems that can generate human-like text, but they don't always know how confident they should be in their own outputs.
Multicalibration is a way to train LLMs to provide accurate confidence scores that match the true likelihood of their predictions being correct. For example, if an LLM says it's 90% confident about something, that should mean it's right 90% of the time.
The authors propose new methods to train LLMs to be multicalibrated, and they test these techniques on various benchmarks to show they work. This is important because it can help us trust and rely on LLM outputs more, especially in critical applications.
Technical Explanation
The paper introduces a new approach called "multicalibration" to improve the confidence scoring of large language models (LLMs). Multicalibration aims to ensure that an LLM's confidence scores accurately reflect the true likelihood of the model's predictions being correct.
The authors propose techniques to train LLMs to be multicalibrated, including a novel loss function and algorithmic approaches. They demonstrate the effectiveness of their methods on several benchmark tasks, showing that multicalibrated LLMs provide more reliable and trustworthy confidence scores.
Critical Analysis
The paper introduces an important and practical approach to improving the reliability of LLMs through multicalibration. The authors provide a strong technical foundation and comprehensive experimental evaluation of their methods.
However, the paper does not address potential limitations or caveats of the multicalibration approach. For example, it's unclear how the techniques would scale to extremely large LLMs or how they would perform on more open-ended and diverse datasets beyond the benchmarks used.
Additionally, the paper does not discuss potential societal impacts or ethical considerations around deploying more reliable and trustworthy LLMs. Further research is needed to understand how multicalibration could be applied responsibly and equitably.
Conclusion
This paper presents a novel approach called "multicalibration" to improve the confidence scoring of large language models (LLMs). By training LLMs to provide accurate and well-calibrated confidence scores, the authors demonstrate a path towards more reliable and trustworthy LLM outputs.
The multicalibration techniques introduced in this work have the potential to significantly enhance the practical applications of LLMs, particularly in high-stakes domains where model confidence is critical. As LLMs continue to advance and become more widely deployed, further research and development in this area will be an important priority.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
0
0
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
4/16/2024
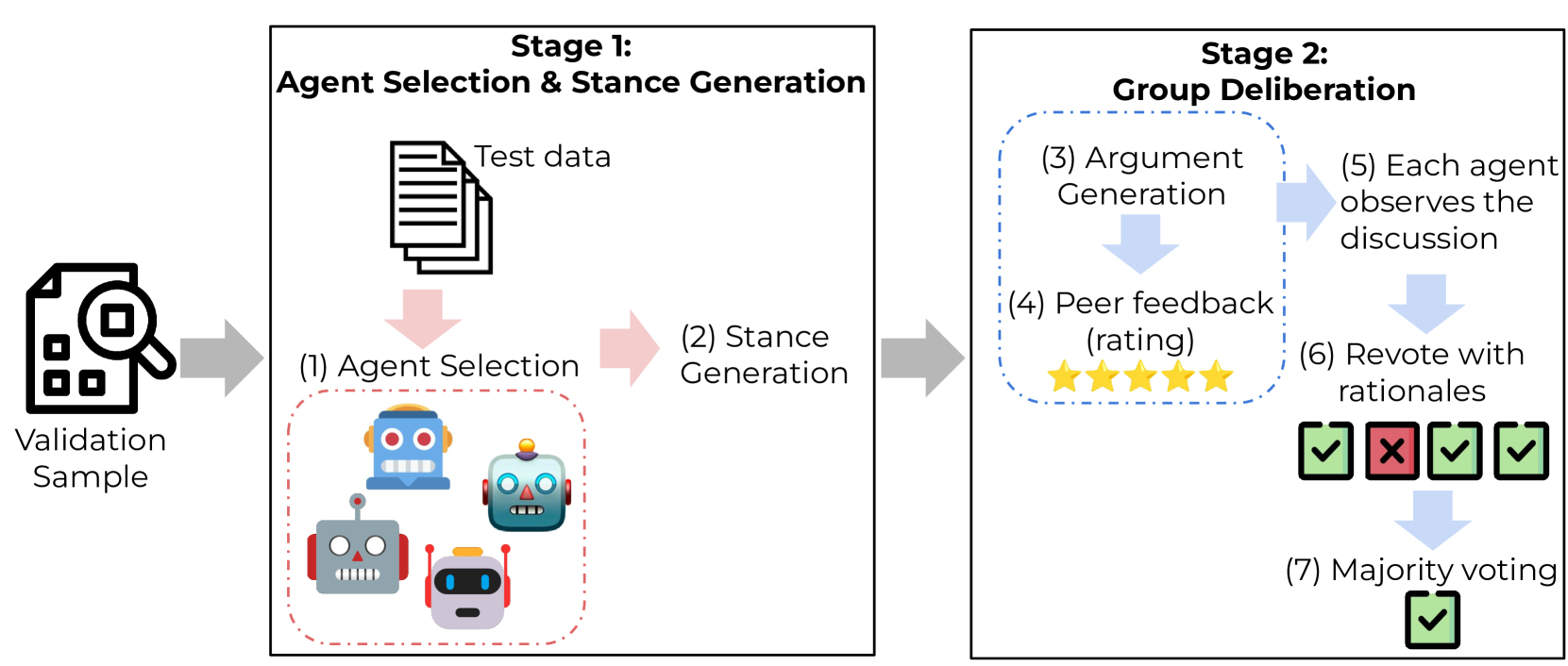
Confidence Calibration and Rationalization for LLMs via Multi-Agent Deliberation
Ruixin Yang, Dheeraj Rajagopal, Shirley Anugrah Hayati, Bin Hu, Dongyeop Kang
0
0
Uncertainty estimation is a significant issue for current large language models (LLMs) that are generally poorly calibrated and over-confident, especially with reinforcement learning from human feedback (RLHF). Unlike humans, whose decisions and confidences not only stem from intrinsic beliefs but can also be adjusted through daily observations, existing calibration methods for LLMs focus on estimating or eliciting individual confidence without taking full advantage of the Collective Wisdom: the interaction among multiple LLMs that can collectively improve both accuracy and calibration. In this work, we propose Collaborative Calibration, a post-hoc training-free calibration strategy that leverages the collaborative and expressive capabilities of multiple tool-augmented LLM agents in a simulated group deliberation process. We demonstrate the effectiveness of Collaborative Calibration on generative QA tasks across various domains, showing its potential in harnessing the rationalization of collectively calibrated confidence assessments and improving the reliability of model predictions.
5/13/2024
🔮
Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores
Yuvraj Virk, Premkumar Devanbu, Toufique Ahmed
0
0
A good summary can often be very useful during program comprehension. While a brief, fluent, and relevant summary can be helpful, it does require significant human effort to produce. Often, good summaries are unavailable in software projects, thus making maintenance more difficult. There has been a considerable body of research into automated AI-based methods, using Large Language models (LLMs), to generate summaries of code; there also has been quite a bit work on ways to measure the performance of such summarization methods, with special attention paid to how closely these AI-generated summaries resemble a summary a human might have produced. Measures such as BERTScore and BLEU have been suggested and evaluated with human-subject studies. However, LLMs often err and generate something quite unlike what a human might say. Given an LLM-produced code summary, is there a way to gauge whether it's likely to be sufficiently similar to a human produced summary, or not? In this paper, we study this question, as a calibration problem: given a summary from an LLM, can we compute a confidence measure, which is a good indication of whether the summary is sufficiently similar to what a human would have produced in this situation? We examine this question using several LLMs, for several languages, and in several different settings. We suggest an approach which provides well-calibrated predictions of likelihood of similarity to human summaries.
5/1/2024
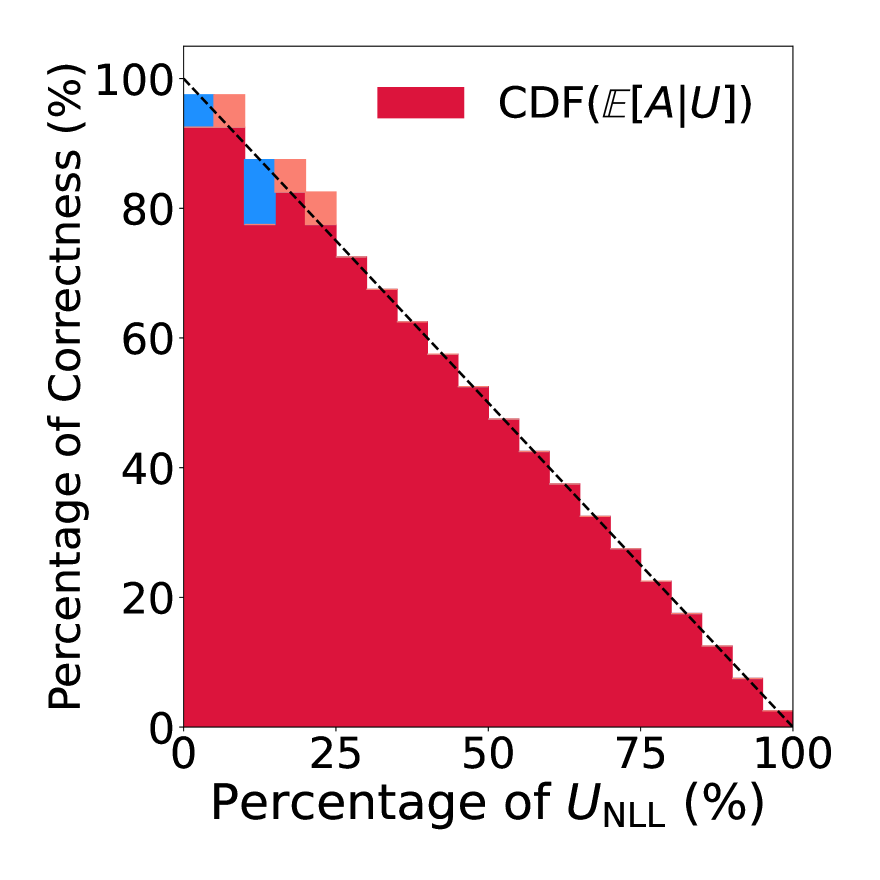
Uncertainty in Language Models: Assessment through Rank-Calibration
Xinmeng Huang, Shuo Li, Mengxin Yu, Matteo Sesia, Hamed Hassani, Insup Lee, Osbert Bastani, Edgar Dobriban
0
0
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.
4/5/2024