Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
2405.14314
0
0
🛠️
Abstract
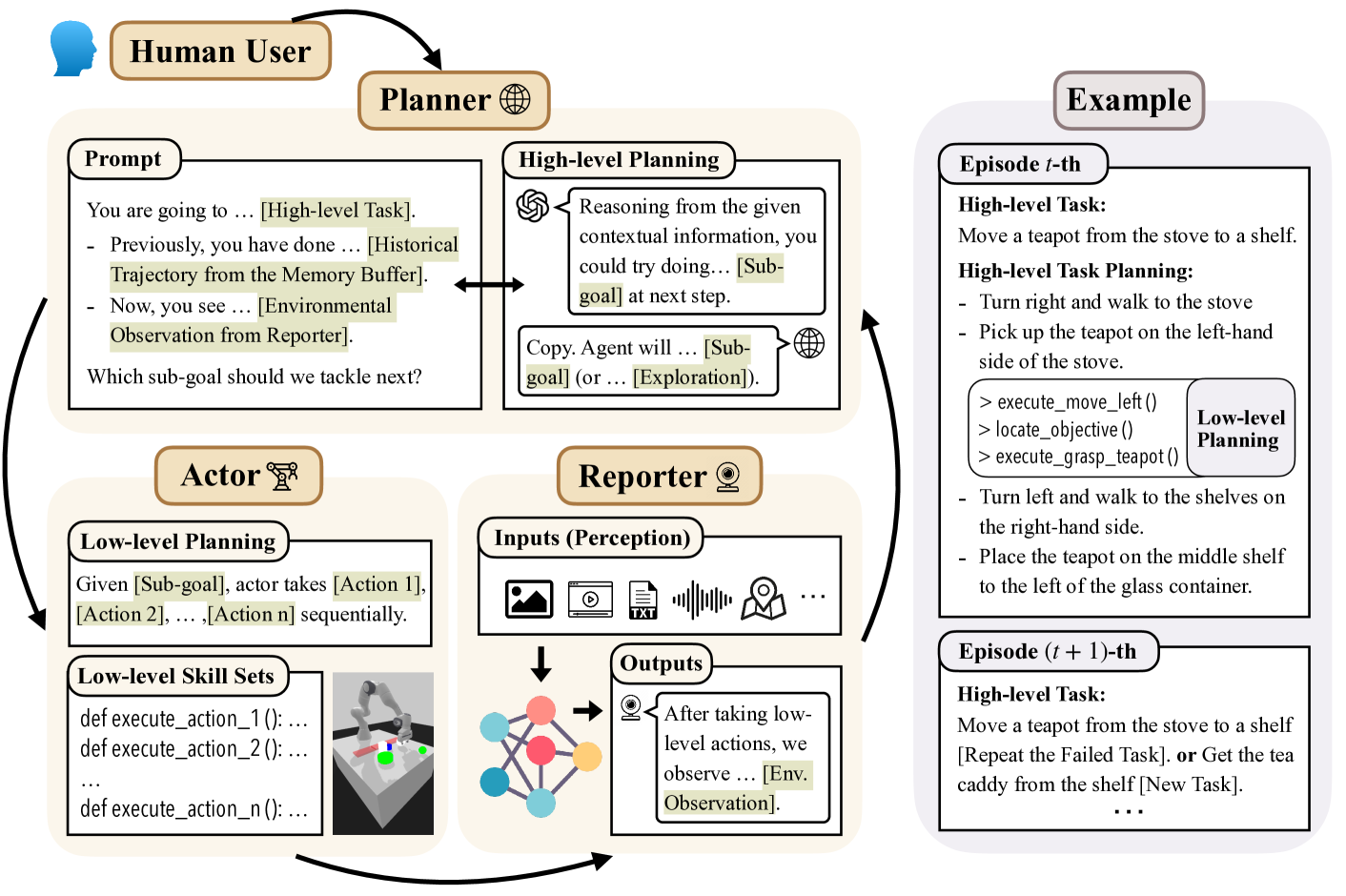
Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the complexity of the physical world. Especially, LLM planning for multi-agent collaboration requires communication of agents or credit assignment as the feedback to re-adjust the proposed plans and achieve effective coordination. However, existing methods that overly rely on physical verification or self-reflection suffer from excessive and inefficient querying of LLMs. In this paper, we propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans. Specifically, we perform critic regression to learn a sequential advantage function from LLM-planned data, and then treat the LLM planner as an optimizer to generate actions that maximize the advantage function. It endows the LLM with the foresight to discern whether the action contributes to accomplishing the final task. We provide theoretical analysis by extending advantage-weighted regression in reinforcement learning to multi-agent systems. Experiments on Overcooked-AI and a difficult variant of RoCoBench show that ReAd surpasses baselines in success rate, and also significantly decreases the interaction steps of agents and query rounds of LLMs, demonstrating its high efficiency for grounding LLMs. More results are given at https://read-llm.github.io/.
Create account to get full access
Overview
- Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the physical world's complexity.
- LLM planning for multi-agent collaboration requires communication or credit assignment to re-adjust proposed plans and achieve effective coordination.
- Existing methods that rely on physical verification or self-reflection suffer from excessive and inefficient querying of LLMs.
Plain English Explanation
Large language models (LLMs) are advanced AI systems that can understand and generate human-like text. However, using these models for real-world, physical tasks can be challenging. This is because the physical world is complex, and LLMs may struggle to reason about the details and logistics of a task.
One area where this is particularly evident is in multi-agent collaboration, where multiple LLMs need to work together to achieve a common goal. To do this effectively, the LLMs need to communicate with each other and adjust their plans based on feedback. However, current methods that rely on physically verifying the plans or having the LLMs reflect on their own performance can be inefficient and require a lot of back-and-forth.
Technical Explanation
In this paper, the researchers propose a novel framework called Reinforced Advantage feedback (ReAd) to address the challenges of grounding LLMs for multi-agent collaboration. The key idea is to use a "critic" model to learn a sequential advantage function from the data generated by the LLM planners. This advantage function can then be used to guide the LLM planners, helping them generate actions that are more likely to contribute to the final task success.
Theoretically, the researchers extend the advantage-weighted regression technique from reinforcement learning to the multi-agent setting, providing a formal analysis of how ReAd can improve the efficiency of LLM planning.
Experimentally, the researchers evaluate ReAd on two challenging tasks: Overcooked-AI and a variant of RoCoBench. The results show that ReAd outperforms baseline methods in terms of success rate and significantly reduces the number of interaction steps between agents and the number of queries to the LLMs, demonstrating its efficiency in grounding LLMs for real-world tasks.
Critical Analysis
The paper presents a thoughtful approach to addressing the challenges of grounding LLMs for embodied, multi-agent tasks. By leveraging a critic model to provide feedback to the LLM planners, the researchers have found a way to improve the efficiency of the planning process without relying on excessive physical verification or self-reflection.
However, the paper does not fully address the limitations of this approach. For example, the researchers acknowledge that the critic model itself may be biased or imperfect, which could lead to suboptimal planning decisions. Additionally, the paper does not explore the scalability of ReAd to larger, more complex multi-agent scenarios.
Further research could investigate ways to make the critic model more robust and reliable, as well as explore how ReAd might perform in more diverse and challenging multi-agent environments. Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the complexity of the physical world, and the ReAd framework represents an important step towards effective large language model adaptation and improved grounding.
Conclusion
This paper presents a novel framework called Reinforced Advantage feedback (ReAd) that aims to improve the efficiency of grounding large language models (LLMs) for multi-agent collaboration tasks. By leveraging a critic model to provide feedback to the LLM planners, ReAd helps the LLMs generate actions that are more likely to contribute to the final task success, reducing the need for excessive physical verification or self-reflection.
The researchers' theoretical analysis and experimental results demonstrate the potential of ReAd to ground language plans and demonstrations through counterfactual perturbations and improve LLM coordination and multi-agent collaboration. While the approach has some limitations, it represents an important step towards better confidence calibration and rationalization of LLMs via multi-agent techniques, which could have far-reaching implications for the field of embodied AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024

Embodied LLM Agents Learn to Cooperate in Organized Teams
Xudong Guo, Kaixuan Huang, Jiale Liu, Wenhui Fan, Natalia V'elez, Qingyun Wu, Huazheng Wang, Thomas L. Griffiths, Mengdi Wang
0
0
Large Language Models (LLMs) have emerged as integral tools for reasoning, planning, and decision-making, drawing upon their extensive world knowledge and proficiency in language-related tasks. LLMs thus hold tremendous potential for natural language interaction within multi-agent systems to foster cooperation. However, LLM agents tend to over-report and comply with any instruction, which may result in information redundancy and confusion in multi-agent cooperation. Inspired by human organizations, this paper introduces a framework that imposes prompt-based organization structures on LLM agents to mitigate these problems. Through a series of experiments with embodied LLM agents and human-agent collaboration, our results highlight the impact of designated leadership on team efficiency, shedding light on the leadership qualities displayed by LLM agents and their spontaneous cooperative behaviors. Further, we harness the potential of LLMs to propose enhanced organizational prompts, via a Criticize-Reflect process, resulting in novel organization structures that reduce communication costs and enhance team efficiency.
5/24/2024
🏅
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
Chuanneng Sun, Songjun Huang, Dario Pompili
0
0
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
5/21/2024
💬
Effective Large Language Model Adaptation for Improved Grounding and Citation Generation
Xi Ye, Ruoxi Sun, Sercan O. Arik, Tomas Pfister
0
0
Large language models (LLMs) have achieved remarkable advancements in natural language understanding and generation. However, one major issue towards their widespread deployment in the real world is that they can generate hallucinated answers that are not factual. Towards this end, this paper focuses on improving LLMs by grounding their responses in retrieved passages and by providing citations. We propose a new framework, AGREE, Adaptation for GRounding EnhancEment, that improves the grounding from a holistic perspective. Our framework tunes LLMs to selfground the claims in their responses and provide accurate citations to retrieved documents. This tuning on top of the pre-trained LLMs requires well-grounded responses (with citations) for paired queries, for which we introduce a method that can automatically construct such data from unlabeled queries. The selfgrounding capability of tuned LLMs further grants them a test-time adaptation (TTA) capability that can actively retrieve passages to support the claims that have not been grounded, which iteratively improves the responses of LLMs. Across five datasets and two LLMs, our results show that the proposed tuningbased AGREE framework generates superior grounded responses with more accurate citations compared to prompting-based approaches and post-hoc citing-based approaches
4/4/2024