ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
2406.08164
0
0

Abstract
Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM-only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
Create account to get full access
Overview
- The paper "ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs" explores new ways to evaluate the compositional reasoning abilities of large language models (LLMs) that combine vision and language.
- The authors argue that current evaluation methods for compositional reasoning in vision-language models (VLMs) are limited and propose a new framework called ConMe to better assess these capabilities.
- ConMe involves creating a diverse set of compositional reasoning tasks that go beyond simple visual reasoning and explore more complex interactions between visual and language understanding.
Plain English Explanation
The paper focuses on a key challenge in the field of artificial intelligence (AI): evaluating the ability of large language models (LLMs) to reason about the world in a compositional way. Compositional reasoning involves the ability to understand and combine different concepts or elements to solve complex problems.
The authors note that current methods for assessing compositional reasoning in vision-language models (VLMs), which are LLMs that can process both visual and textual information, are limited. They often test only simple visual reasoning tasks, like identifying objects in an image. The researchers argue that we need more comprehensive ways to evaluate these models' true understanding of the world.
To address this, the authors propose a new framework called ConMe. ConMe involves creating a diverse set of reasoning tasks that go beyond basic visual recognition. These tasks explore how well VLMs can combine visual information with language understanding to tackle more complex problems. For example, a ConMe task might ask a model to reason about the relationship between multiple objects in an image and then answer a question about that relationship.
By developing this richer set of compositional reasoning tests, the researchers hope to gain a deeper understanding of the inner workings of VLMs and identify areas where these models still struggle. This knowledge could then inform the development of more capable and versatile AI systems that can truly comprehend the world around them.
Technical Explanation
The paper introduces a new framework called ConMe (Compositional Reasoning Metric) to rethink the evaluation of compositional reasoning in modern vision-language models (VLMs). The authors argue that existing evaluation methods for compositional reasoning in VLMs are limited, often focusing on simple visual reasoning tasks that do not adequately capture the models' true understanding of the world.
To address this, the ConMe framework involves creating a diverse set of compositional reasoning tasks that go beyond basic visual recognition. These tasks explore how well VLMs can combine visual information with language understanding to tackle more complex problems, such as reasoning about the relationships between multiple objects in an image or answering questions that require integrating visual and textual cues.
The paper outlines the key components of the ConMe framework, including task design principles, dataset creation, and evaluation metrics. The authors describe their process for systematically constructing a comprehensive set of compositional reasoning tasks that cover a wide range of visual and linguistic phenomena.
Through extensive experiments, the researchers evaluate the performance of state-of-the-art VLMs on the ConMe tasks and provide insights into the models' strengths and limitations in compositional reasoning. The results suggest that current VLMs still struggle with certain types of compositional reasoning, particularly when it comes to reasoning about more abstract and relational concepts.
The paper also discusses the potential implications of the ConMe framework for the development of more capable and versatile AI systems, as well as the broader challenges in evaluating the compositional reasoning abilities of large language models.
Critical Analysis
The authors of the paper make a compelling case for the need to rethink the evaluation of compositional reasoning in modern vision-language models (VLMs). They highlight the limitations of current evaluation methods, which often focus on simple visual reasoning tasks and do not fully capture the models' true understanding of the world.
The ConMe framework proposed in the paper is a promising approach to addressing this issue. By creating a diverse set of compositional reasoning tasks that go beyond basic visual recognition, the researchers aim to gain deeper insights into the capabilities and limitations of VLMs. This is an important step forward in the field of AI, as the ability to reason in a compositional way is widely recognized as a key challenge in developing more capable and versatile AI systems.
However, the paper also acknowledges several caveats and areas for further research. For example, the authors note that the ConMe tasks may not fully capture all aspects of compositional reasoning, and that more work is needed to understand the nuances of how VLMs approach these types of problems.
Additionally, the paper does not address the potential biases or limitations of the dataset used to create the ConMe tasks. It would be important to consider how the selection and construction of these tasks might influence the evaluation results and the conclusions drawn about VLM capabilities.
Overall, the ConMe framework presented in this paper represents an important step forward in the quest to better understand and evaluate the compositional reasoning abilities of large language models. The insights gained from this research could have significant implications for the development of more advanced AI systems capable of truly comprehending the world around them.
Conclusion
The paper "ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs" proposes a new framework for assessing the compositional reasoning abilities of large language models that combine vision and language understanding. The authors argue that current evaluation methods are limited and do not fully capture the models' true understanding of the world.
The ConMe framework involves creating a diverse set of compositional reasoning tasks that go beyond simple visual recognition, exploring how well VLMs can integrate visual and linguistic information to tackle more complex problems. By developing this richer set of evaluation tasks, the researchers aim to gain deeper insights into the strengths and limitations of these models and inform the development of more capable and versatile AI systems.
The insights and methodologies presented in this paper could have significant implications for the field of artificial intelligence, as the ability to reason in a compositional way is widely recognized as a key challenge in advancing the state of the art in AI. While the paper acknowledges several caveats and areas for further research, it represents an important step forward in the quest to better understand and evaluate the compositional reasoning abilities of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
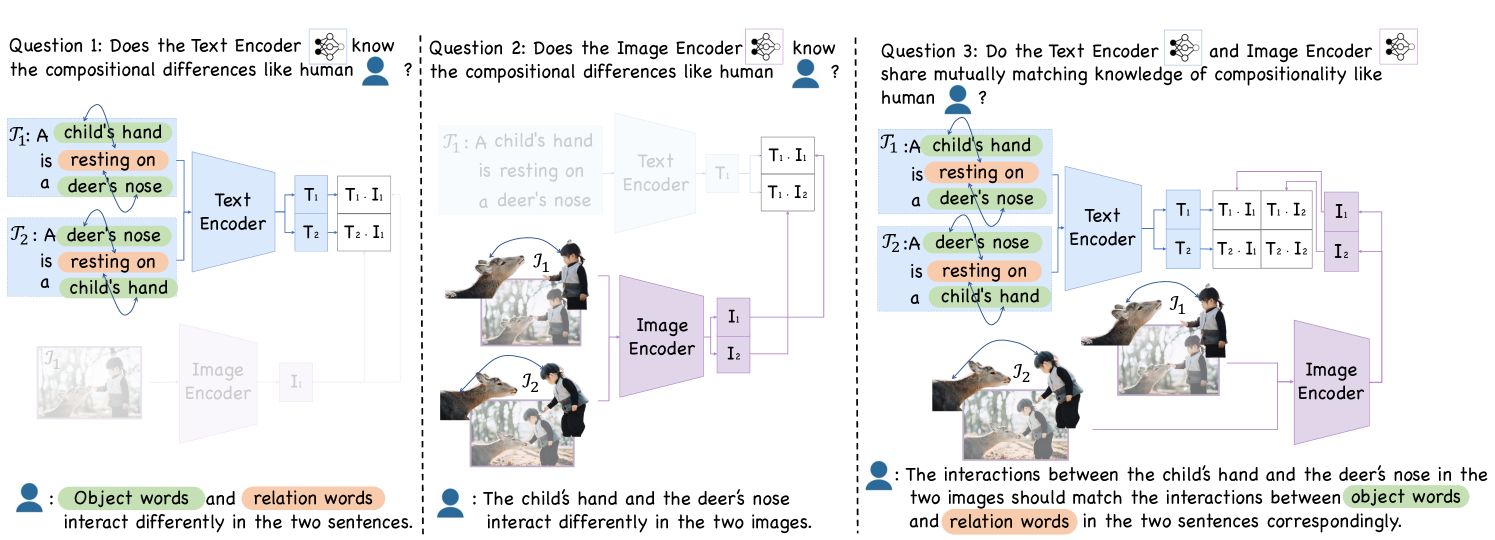
Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
Jin Wang, Shichao Dong, Yapeng Zhu, Kelu Yao, Weidong Zhao, Chao Li, Ping Luo
0
0
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies. The deliverables will be updated at https://vlms-compositionality-gametheory.github.io/.
5/28/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Kaiwen Zhou, Kwonjoon Lee, Teruhisa Misu, Xin Eric Wang
0
0
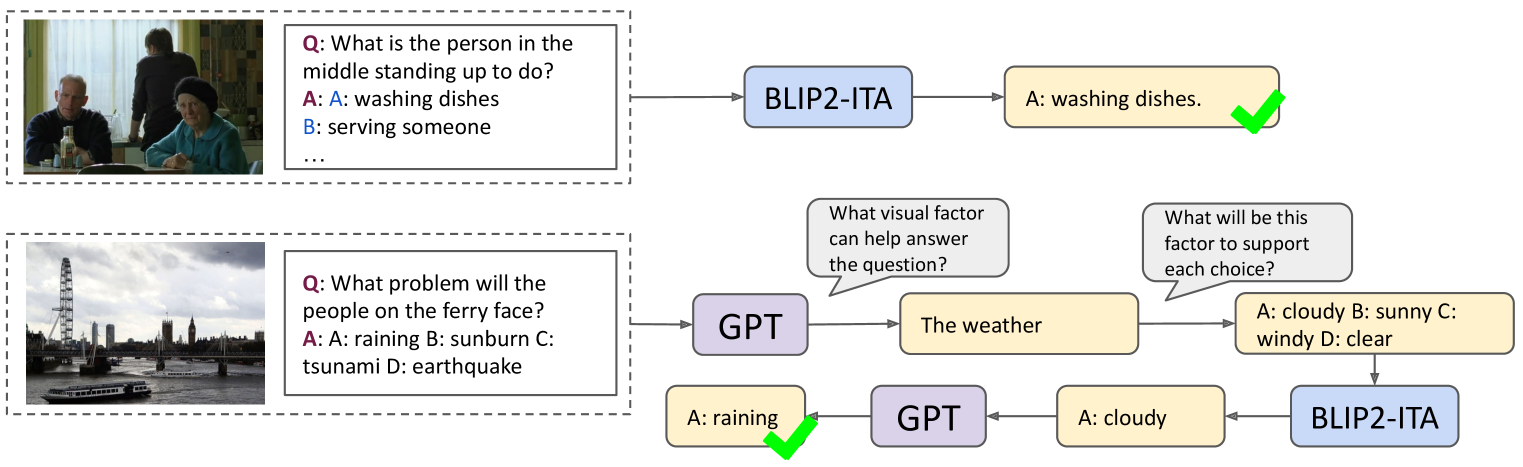
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) on visual commonsense reasoning (VCR) problems. We find that VLMs and LLMs-based decision pipelines are good at different kinds of VCR problems. Pre-trained VLMs exhibit strong performance for problems involving understanding the literal visual content, which we noted as visual commonsense understanding (VCU). For problems where the goal is to infer conclusions beyond image content, which we noted as visual commonsense inference (VCI), VLMs face difficulties, while LLMs, given sufficient visual evidence, can use commonsense to infer the answer well. We empirically validate this by letting LLMs classify VCR problems into these two categories and show the significant difference between VLM and LLM with image caption decision pipelines on two subproblems. Moreover, we identify a challenge with VLMs' passive perception, which may miss crucial context information, leading to incorrect reasoning by LLMs. Based on these, we suggest a collaborative approach, named ViCor, where pre-trained LLMs serve as problem classifiers to analyze the problem category, then either use VLMs to answer the question directly or actively instruct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain fine-tuning.
5/20/2024

Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Aleksandar Stani'c, Sergi Caelles, Michael Tschannen
0
0
Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
5/16/2024