Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
2405.17201
0
0
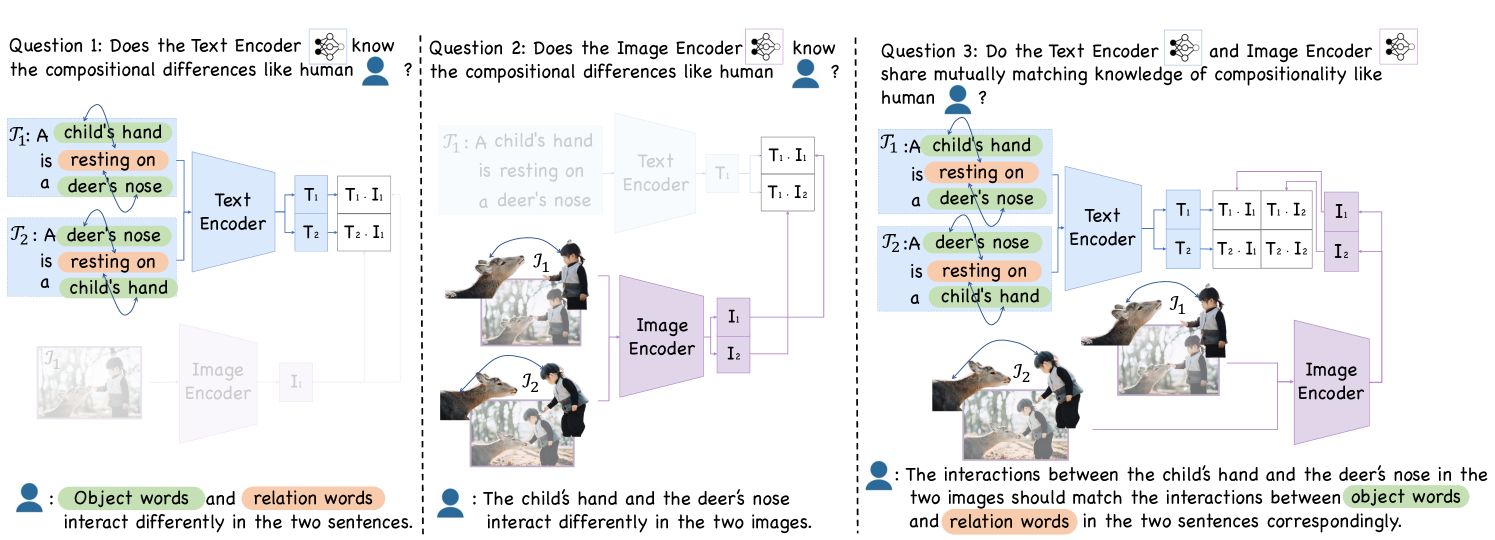
Abstract
Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies. The deliverables will be updated at https://vlms-compositionality-gametheory.github.io/.
Create account to get full access
Overview
- This paper investigates the compositional knowledge of vision language models (VLMs) from a game-theoretic perspective.
- The authors propose a game-theoretic framework to diagnose the compositional understanding of VLMs and examine their ability to reason about complex visual scenes.
- The research aims to provide insights into the inner workings of VLMs and identify potential compositional deficiencies that could limit their performance on challenging tasks.
Plain English Explanation
Vision language models (VLMs) are a type of artificial intelligence that can understand and generate language about images. These models have shown impressive capabilities, but there are still questions about how well they truly understand the underlying concepts and how they can reason about complex visual scenes.
This paper explores a game-theoretic approach to diagnosing the compositional knowledge of VLMs. The authors create a framework that treats the interaction between the model and a human player as a game, where the goal is to test the model's ability to reason about the composition of visual elements. By framing it as a game, the researchers can systematically probe the model's understanding and uncover any potential weaknesses or limitations in its compositional knowledge.
The key idea is to design a game where the human player and the VLM take turns making moves, with the human introducing new visual elements or modifying existing ones, and the VLM needing to interpret and respond to these changes. This back-and-forth interaction allows the researchers to assess how well the VLM can reason about the compositional aspects of the visual scene, such as the relationships between different objects, their relative positions, and how they interact with each other.
By taking this game-theoretic approach, the authors hope to gain deeper insights into the inner workings of VLMs and identify areas where they may have blind spots or weaknesses in their compositional understanding. This knowledge could then inform the development of more robust and capable VLMs that can better handle complex visual reasoning tasks.
Technical Explanation
The authors propose a game-theoretic framework to diagnose the compositional knowledge of vision language models (VLMs). They frame the interaction between the VLM and a human player as a game, where the goal is to test the model's ability to reason about the composition of visual elements.
The game involves a series of turns, where the human player introduces new visual elements or modifies existing ones, and the VLM must interpret and respond to these changes. The researchers design the game to systematically probe the VLM's understanding of the compositional aspects of the visual scene, such as the relationships between objects, their relative positions, and how they interact with each other.
By analyzing the VLM's responses and performance in this game, the authors aim to uncover potential weaknesses or limitations in the model's compositional knowledge. This information could then be used to guide the development of more robust and capable VLMs that can better handle complex visual reasoning tasks.
The authors draw inspiration from related work in the field of vision language modeling, which has explored the compositional understanding of these models (Exploring Compositional Deficiency in Large Language Models, Iterated Learning Improves Compositionality in Large Vision-Language Models, Towards Truly Zero-Shot Compositional Visual Reasoning, Probing the Conceptual Understanding of Large Visual Language Models).
Critical Analysis
The game-theoretic approach proposed in this paper provides a novel and systematic way to diagnose the compositional knowledge of vision language models. By framing the interaction as a game, the researchers can systematically test the VLM's understanding of visual relationships and compositions, potentially uncovering blind spots or limitations that may not be evident from traditional evaluation metrics.
One potential limitation of this approach is that it relies on the design of the game itself and the specific visual elements and compositions used. The researchers acknowledge this and emphasize the need for carefully crafted game scenarios that can effectively probe the VLM's compositional understanding.
Another area for further research could be to explore how the game-theoretic framework could be extended to other types of AI systems beyond VLMs, such as multimodal models that integrate vision, language, and other modalities. Applying this approach to a broader range of AI models could provide valuable insights into the compositional reasoning capabilities of these systems.
Overall, the game-theoretic approach presented in this paper offers a promising new way to investigate the inner workings of vision language models and could lead to the development of more robust and capable models in the future.
Conclusion
This paper introduces a game-theoretic framework for diagnosing the compositional knowledge of vision language models (VLMs). By framing the interaction between the VLM and a human player as a game, the researchers can systematically probe the model's ability to reason about the composition of visual elements, such as the relationships between objects, their relative positions, and how they interact with each other.
The game-theoretic approach provides a novel and promising way to uncover potential weaknesses or limitations in the VLM's compositional understanding, which could then inform the development of more robust and capable models. While the approach relies on the design of the game itself, the insights gained from this research could have significant implications for the field of vision language modeling and the broader pursuit of more advanced and compositionally-aware AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Youngtaek Oh, Pyunghwan Ahn, Jinhyung Kim, Gwangmo Song, Soonyoung Lee, In So Kweon, Junmo Kim
0
0
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
6/14/2024

ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
Irene Huang, Wei Lin, M. Jehanzeb Mirza, Jacob A. Hansen, Sivan Doveh, Victor Ion Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuhene, Trevor Darrel, Chuang Gan, Aude Oliva, Rogerio Feris, Leonid Karlinsky
0
0
Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM-only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
6/13/2024
💬
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
0
0
Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset textsc{MathTrap}footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
5/14/2024
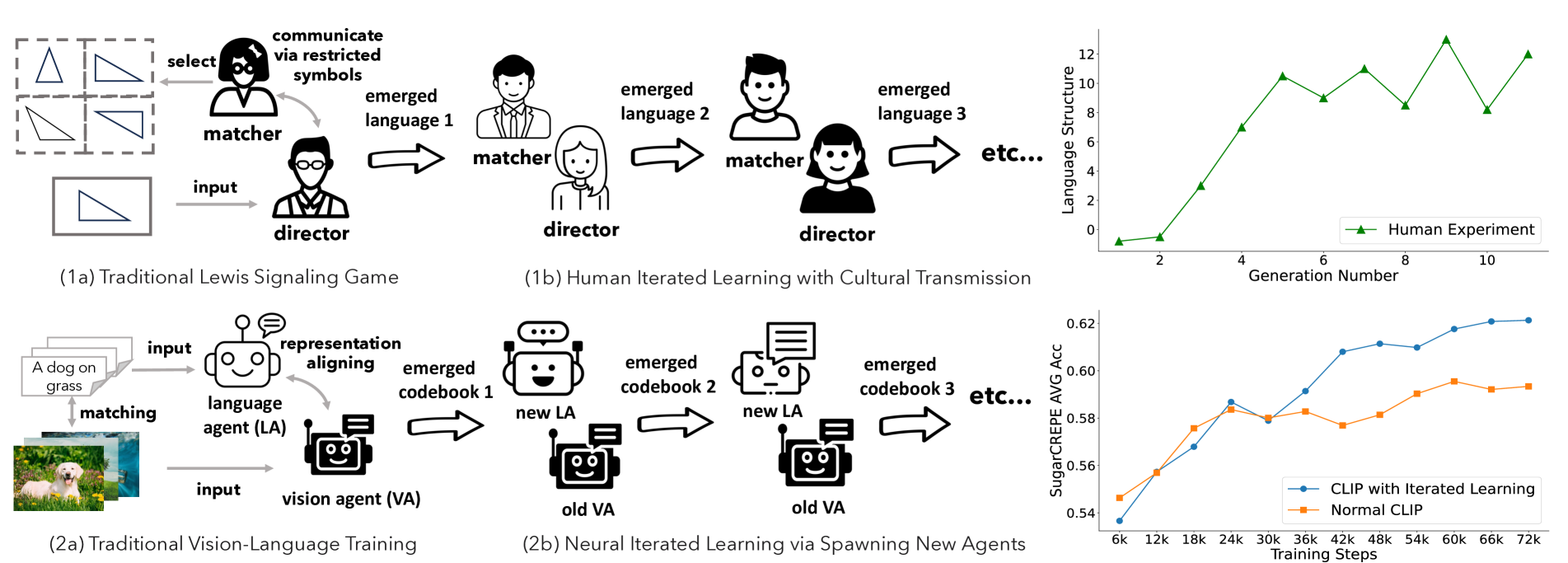
Iterated Learning Improves Compositionality in Large Vision-Language Models
Chenhao Zheng, Jieyu Zhang, Aniruddha Kembhavi, Ranjay Krishna
0
0
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, recent investigations find that most-if not all-our state-of-the-art vision-language models struggle at compositionality. They are unable to distinguish between images of a girl in white facing a man in black and a girl in black facing a man in white. Moreover, prior work suggests that compositionality doesn't arise with scale: larger model sizes or training data don't help. This paper develops a new iterated training algorithm that incentivizes compositionality. We draw on decades of cognitive science research that identifies cultural transmission-the need to teach a new generation-as a necessary inductive prior that incentivizes humans to develop compositional languages. Specifically, we reframe vision-language contrastive learning as the Lewis Signaling Game between a vision agent and a language agent, and operationalize cultural transmission by iteratively resetting one of the agent's weights during training. After every iteration, this training paradigm induces representations that become easier to learn, a property of compositional languages: e.g. our model trained on CC3M and CC12M improves standard CLIP by 4.7%, 4.0% respectfully in the SugarCrepe benchmark.
4/3/2024