Context-Aware Assistant Selection for Improved Inference Acceleration with Large Language Models

0

Sign in to get full access
Overview
- This paper proposes a context-aware assistant selection approach to improve inference acceleration with large language models.
- The key idea is to dynamically select the most appropriate assistant based on the input context, which can lead to faster and more efficient inference.
- The authors present a novel architecture and experimental evaluation to demonstrate the effectiveness of their approach.
Plain English Explanation
The paper focuses on how to get large language models to work more efficiently. These models are powerful, but running them can be slow and resource-intensive. The researchers developed a new way to speed things up by dynamically selecting the most appropriate "assistant" for the task at hand.
The basic concept is that different input contexts may require different types of language model assistance. By choosing the right assistant based on the context, the system can run more quickly and use fewer computing resources. This is kind of like having a team of experts, each with their own specialty, and picking the right one for the job instead of always using the same generic person.
The paper describes the architecture of this context-aware assistant selection system and shows through experiments that it can significantly improve the speed and efficiency of large language model inference. This could be very useful in real-world applications where fast, resource-efficient language processing is important.
Technical Explanation
The key idea behind the context-aware assistant selection approach is to dynamically choose the most appropriate "assistant" model to use for a given input, rather than always relying on a single generic language model.
The assistant selection mechanism takes into account features of the input context, such as the task, domain, and other relevant factors, to determine the most suitable assistant. This allows the system to leverage the specialized capabilities of different assistants to optimize for speed and efficiency.
The proposed architecture includes components for feature extraction, assistant selection, and inference acceleration. The authors evaluate their approach on several benchmarks and demonstrate significant improvements in inference latency and resource usage compared to using a single monolithic language model.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed context-aware assistant selection approach. However, the authors acknowledge some limitations, such as the need for careful design of the assistant selection mechanism and potential challenges in scaling the approach to very large numbers of assistants.
Additionally, the paper does not delve deeply into the potential biases or fairness implications of this approach, which could be an important area for further research. As the field of large language models continues to evolve, exploring the ethical and societal impacts of such optimizations will be crucial.
Conclusion
This paper introduces an innovative approach to improving the efficiency of large language model inference by dynamically selecting the most appropriate assistant based on the input context. The experimental results demonstrate significant performance gains, which could have important implications for real-world applications that require fast and resource-efficient language processing.
While the authors acknowledge some limitations, the core concept of context-aware assistant selection represents a promising direction for further research and development in the field of efficient large language model inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Context-Aware Assistant Selection for Improved Inference Acceleration with Large Language Models
Jerry Huang, Prasanna Parthasarathi, Mehdi Rezagholizadeh, Sarath Chandar
Despite their widespread adoption, large language models (LLMs) remain prohibitive to use under resource constraints, with their ever growing sizes only increasing the barrier for use. One noted issue is the high latency associated with auto-regressive generation, rendering large LLMs use dependent on advanced computing infrastructure. Assisted decoding, where a smaller draft model guides a larger target model's generation, has helped alleviate this, but remains dependent on alignment between the two models. Thus if the draft model is insufficiently capable on some domain relative to the target model, performance can degrade. Alternatively, one can leverage multiple draft models to better cover the expertise of the target, but when multiple black-box draft models are available, selecting an assistant without details about its construction can be difficult. To better understand this decision making problem, we observe it as a contextual bandit, where a policy must choose a draft model based on a context. We show that even without prior knowledge of the draft models, creating an offline dataset from only outputs of independent draft/target models and training a policy over the alignment of these outputs can accelerate performance on multiple domains provided the candidates are effective. Further results show this to hold on various settings with multiple assisted decoding candidates, highlighting its flexibility and the advantageous role that such decision making can play.
Read more8/19/2024

0
Adaptive Draft-Verification for Efficient Large Language Model Decoding
Xukun Liu, Bowen Lei, Ruqi Zhang, Dongkuan Xu
Large language model (LLM) decoding involves generating a sequence of tokens based on a given context, where each token is predicted one at a time using the model's learned probabilities. The typical autoregressive decoding method requires a separate forward pass through the model for each token generated, which is computationally inefficient and poses challenges for deploying LLMs in latency-sensitive scenarios. The main limitations of current decoding methods stem from their inefficiencies and resource demands. Existing approaches either necessitate fine-tuning smaller models, which is resource-intensive, or rely on fixed retrieval schemes to construct drafts for the next tokens, which lack adaptability and fail to generalize across different models and contexts. To address these issues, we introduce a novel methodology called ADED, which accelerates LLM decoding without requiring fine-tuning. Our approach involves an adaptive draft-verification process that evolves over time to improve efficiency. We utilize a tri-gram matrix-based LLM representation to dynamically approximate the output distribution of the LLM, allowing the model to adjust to changing token probabilities during the decoding process. Additionally, we implement a draft construction mechanism that effectively balances exploration and exploitation, ensuring that the drafts generated are both diverse and close to the true output distribution of the LLM. The importance of this design lies in its ability to optimize the draft distribution adaptively, leading to faster and more accurate decoding. Through extensive experiments on various benchmark datasets and LLM architectures, we demonstrate that ADED significantly accelerates the decoding process while maintaining high accuracy, making it suitable for deployment in a wide range of practical applications.
Read more8/20/2024
0
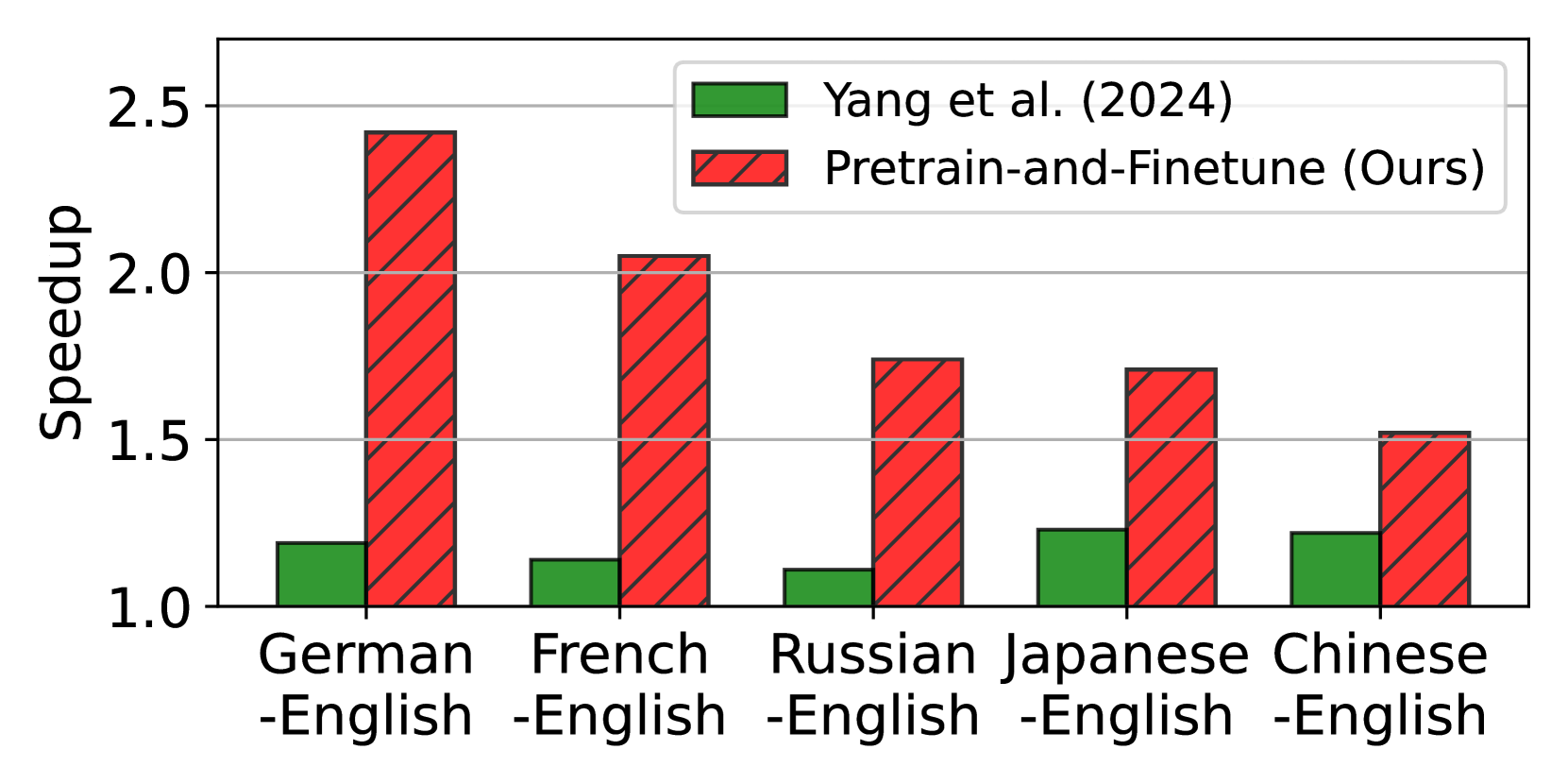
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, Se-Young Yun
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Read more6/26/2024
0
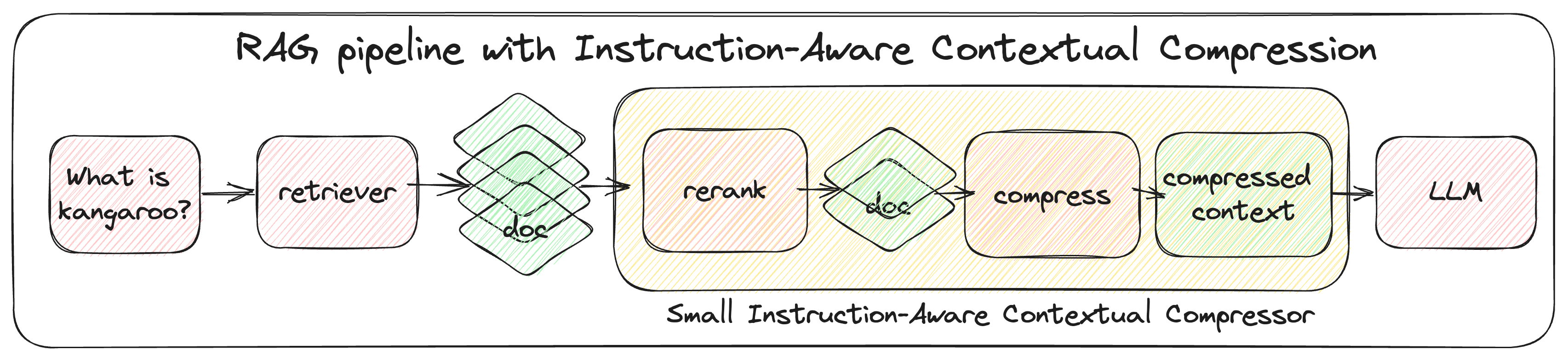
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.
Read more8/29/2024