Adaptive Draft-Verification for Efficient Large Language Model Decoding

0

Sign in to get full access
Overview
- Introduces an "Adaptive Draft-Verification" method for more efficient decoding of large language models (LLMs)
- Builds on prior work on "speculative decoding" and "fast multilingual LLM inference"
- Aims to reduce computational costs and latency for LLM inference, enabling more practical deployment
Plain English Explanation
The paper presents a new technique called "Adaptive Draft-Verification" to make the process of generating text from large language models (LLMs) more efficient. LLMs are powerful AI systems that can produce human-like text, but running them requires a lot of computational power and can be slow.
The key idea is to first generate a draft output quickly using a smaller, less accurate model. This draft is then verified and refined by the full LLM to produce the final output. The paper shows that by adaptively adjusting the balance between the draft and verification steps, they can achieve significant speedups in LLM inference without sacrificing quality.
This builds on prior work exploring "speculative decoding" approaches, where multiple potential outputs are generated in parallel to improve efficiency. The new "Adaptive Draft-Verification" method takes this even further by dynamically optimizing the draft and verification stages.
The authors demonstrate the benefits of their approach on several language modeling benchmarks, showing it can achieve up to 2.5x speedups in inference time compared to standard LLM decoding, while maintaining similar output quality. This could enable more practical and widespread deployment of powerful LLMs in real-world applications.
Technical Explanation
The paper introduces an "Adaptive Draft-Verification" method for efficient decoding of large language models (LLMs). The core idea is to first generate a "draft" output using a smaller, less accurate model, and then have the full LLM "verify" and refine this draft to produce the final output.
The key technical components are:
-
Draft Model: A lightweight model that can produce a fast, rough draft output. This is typically a smaller, less capable version of the full LLM.
-
Verification Model: The full, high-performance LLM that is used to refine and improve the draft output.
-
Adaptive Scheduler: A module that dynamically adjusts the balance between the draft and verification stages to optimize for speed and quality. This includes deciding how much of the draft to keep, how much verification to perform, etc.
The paper explores different techniques for training the draft model, including "direct alignment" and "speculative decoding". They also study how the adaptive scheduler can be optimized for different metrics like latency, throughput, or a combination.
Experiments on language modeling benchmarks show the "Adaptive Draft-Verification" approach can achieve up to 2.5x speedups in inference time compared to standard LLM decoding, while maintaining similar output quality. This could enable more practical and widespread deployment of LLMs in real-world applications that require fast, efficient inference, such as multimodal LLMs or comprehensive LLM systems.
Critical Analysis
The paper presents a compelling approach to improving the efficiency of LLM decoding, building on prior work in this area. The key strengths are the adaptive, dynamically optimized nature of the draft-verification process, and the demonstrated speedups without significant quality degradation.
However, the paper acknowledges several limitations and areas for future work:
- The draft model may still require significant training and tuning to achieve the desired performance, which could limit the practical benefits.
- The adaptive scheduler introduces additional complexity and potential failure modes that would need to be carefully managed.
- The evaluation is focused on language modeling tasks, and the approach may not generalize equally well to other LLM applications like dialogue, summarization, or code generation.
- There are open questions around the generalizability of the draft-verification approach to different LLM architectures and training regimes.
Additionally, one could raise concerns about the potential for the draft-verification approach to introduce new biases or safety issues if not implemented carefully. Ensuring the integrity and reliability of the final LLM outputs would be crucial for real-world deployment.
Overall, the "Adaptive Draft-Verification" method represents an interesting and promising direction for improving LLM efficiency, but further research and validation would be needed to fully assess its merits and limitations.
Conclusion
This paper presents a novel "Adaptive Draft-Verification" approach to improve the efficiency of large language model (LLM) decoding. By dynamically balancing a fast, low-quality draft output with a more comprehensive verification step using the full LLM, the method can achieve significant speedups in inference time without sacrificing output quality.
The key insights build on prior work in areas like "speculative decoding" and "fast multilingual LLM inference", further advancing the state of the art in efficient LLM deployment.
If successful, this approach could enable more practical and widespread use of powerful LLMs in real-world applications that require fast, low-latency inference, such as multimodal LLMs or comprehensive LLM systems. However, further research is needed to address the limitations and potential pitfalls highlighted in the critical analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Draft-Verification for Efficient Large Language Model Decoding
Xukun Liu, Bowen Lei, Ruqi Zhang, Dongkuan Xu
Large language model (LLM) decoding involves generating a sequence of tokens based on a given context, where each token is predicted one at a time using the model's learned probabilities. The typical autoregressive decoding method requires a separate forward pass through the model for each token generated, which is computationally inefficient and poses challenges for deploying LLMs in latency-sensitive scenarios. The main limitations of current decoding methods stem from their inefficiencies and resource demands. Existing approaches either necessitate fine-tuning smaller models, which is resource-intensive, or rely on fixed retrieval schemes to construct drafts for the next tokens, which lack adaptability and fail to generalize across different models and contexts. To address these issues, we introduce a novel methodology called ADED, which accelerates LLM decoding without requiring fine-tuning. Our approach involves an adaptive draft-verification process that evolves over time to improve efficiency. We utilize a tri-gram matrix-based LLM representation to dynamically approximate the output distribution of the LLM, allowing the model to adjust to changing token probabilities during the decoding process. Additionally, we implement a draft construction mechanism that effectively balances exploration and exploitation, ensuring that the drafts generated are both diverse and close to the true output distribution of the LLM. The importance of this design lies in its ability to optimize the draft distribution adaptively, leading to faster and more accurate decoding. Through extensive experiments on various benchmark datasets and LLM architectures, we demonstrate that ADED significantly accelerates the decoding process while maintaining high accuracy, making it suitable for deployment in a wide range of practical applications.
Read more8/20/2024
💬
0
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra
We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting. Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM. Moreover, the proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its variants demonstrated a speedup up to 1.99$times$.
Read more5/21/2024
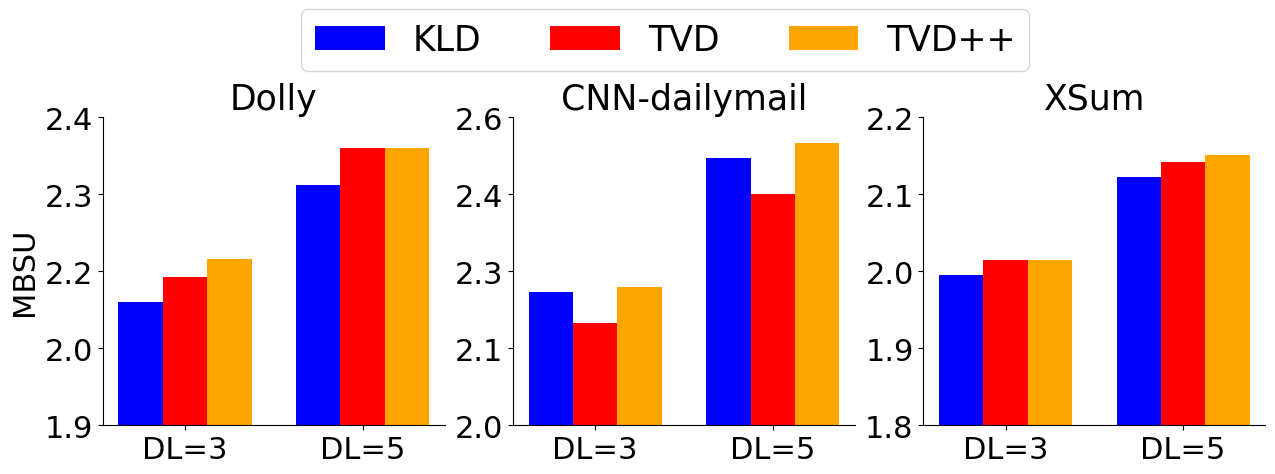
0
Direct Alignment of Draft Model for Speculative Decoding with Chat-Fine-Tuned LLMs
Raghavv Goel, Mukul Gagrani, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Text generation with Large Language Models (LLMs) is known to be memory bound due to the combination of their auto-regressive nature, huge parameter counts, and limited memory bandwidths, often resulting in low token rates. Speculative decoding has been proposed as a solution for LLM inference acceleration. However, since draft models are often unavailable in the modern open-source LLM families, e.g., for Llama 2 7B, training a high-quality draft model is required to enable inference acceleration via speculative decoding. In this paper, we propose a simple draft model training framework for direct alignment to chat-capable target models. With the proposed framework, we train Llama 2 Chat Drafter 115M, a draft model for Llama 2 Chat 7B or larger, with only 1.64% of the original size. Our training framework only consists of pretraining, distillation dataset generation, and finetuning with knowledge distillation, with no additional alignment procedure. For the finetuning step, we use instruction-response pairs generated by target model for distillation in plausible data distribution, and propose a new Total Variation Distance++ (TVD++) loss that incorporates variance reduction techniques inspired from the policy gradient method in reinforcement learning. Our empirical results show that Llama 2 Chat Drafter 115M with speculative decoding achieves up to 2.3 block efficiency and 2.4$times$ speed-up relative to autoregressive decoding on various tasks with no further task-specific fine-tuning.
Read more5/15/2024

0
Context-Aware Assistant Selection for Improved Inference Acceleration with Large Language Models
Jerry Huang, Prasanna Parthasarathi, Mehdi Rezagholizadeh, Sarath Chandar
Despite their widespread adoption, large language models (LLMs) remain prohibitive to use under resource constraints, with their ever growing sizes only increasing the barrier for use. One noted issue is the high latency associated with auto-regressive generation, rendering large LLMs use dependent on advanced computing infrastructure. Assisted decoding, where a smaller draft model guides a larger target model's generation, has helped alleviate this, but remains dependent on alignment between the two models. Thus if the draft model is insufficiently capable on some domain relative to the target model, performance can degrade. Alternatively, one can leverage multiple draft models to better cover the expertise of the target, but when multiple black-box draft models are available, selecting an assistant without details about its construction can be difficult. To better understand this decision making problem, we observe it as a contextual bandit, where a policy must choose a draft model based on a context. We show that even without prior knowledge of the draft models, creating an offline dataset from only outputs of independent draft/target models and training a policy over the alignment of these outputs can accelerate performance on multiple domains provided the candidates are effective. Further results show this to hold on various settings with multiple assisted decoding candidates, highlighting its flexibility and the advantageous role that such decision making can play.
Read more8/19/2024