ContextBLIP: Doubly Contextual Alignment for Contrastive Image Retrieval from Linguistically Complex Descriptions

0

Sign in to get full access
Overview
- This paper presents ContextBLIP, a novel approach for contrastive image retrieval from linguistically complex descriptions.
- The key idea is to align image features with language features in a doubly contextual manner, considering both the broader context of the description and the specific context around each word.
- ContextBLIP outperforms existing state-of-the-art methods on several challenging image-text retrieval benchmarks.
Plain English Explanation
ContextBLIP is a new technique for finding the right image based on a detailed text description. Many existing methods struggle with complex, nuanced language, but ContextBLIP handles this better by considering the overall context of the description as well as the specific context around each word.
Imagine you're searching for an image of a dog playing fetch in a park on a sunny day. A typical system might just try to match keywords like "dog," "fetch," and "park." But ContextBLIP also understands the broader meaning and setting implied by the full description. It can better grasp that the description is about a cheerful, outdoor scene involving a dog and a game, not just a collection of isolated objects.
By capturing this deeper contextual understanding, ContextBLIP is able to more accurately retrieve the most relevant images for complex, detailed text queries. This makes it a powerful tool for applications like visual search engines, where users want to find specific images based on rich, natural language descriptions.
Technical Explanation
ContextBLIP uses a doubly contextual alignment approach to match image and language features. First, it encodes the overall context of the full text description using a transformer-based language model. Then, it aligns this global context with local, word-level context extracted from the description.
This doubly contextual alignment allows ContextBLIP to better handle linguistically complex queries compared to prior image-text matching methods. The authors show ContextBLIP outperforming state-of-the-art approaches on several challenging image-text retrieval benchmarks.
Critical Analysis
The paper provides a thorough evaluation of ContextBLIP, demonstrating its advantages over existing methods. However, the authors acknowledge that their approach still has limitations in handling extremely long and complex descriptions.
Additionally, the training process for ContextBLIP requires significant computational resources, which may limit its practical applicability, especially for resource-constrained real-world deployments. Further research is needed to improve the efficiency and scalability of the model.
It would also be valuable to explore how ContextBLIP's contextual understanding capabilities could be leveraged beyond just image retrieval, such as for generating diverse and relevant image captions or [learning more interpretable visual-linguistic representations.
Conclusion
The ContextBLIP model represents an important advancement in contrastive image retrieval from linguistically complex descriptions. By capturing both global and local contextual information, it significantly outperforms prior state-of-the-art methods. While the approach has some limitations, the insights and techniques developed in this work could have far-reaching implications for improving the interpretability and robustness of vision-language systems, with applications in areas like visual search, image captioning, and visual context learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ContextBLIP: Doubly Contextual Alignment for Contrastive Image Retrieval from Linguistically Complex Descriptions
Honglin Lin, Siyu Li, Guoshun Nan, Chaoyue Tang, Xueting Wang, Jingxin Xu, Rong Yankai, Zhili Zhou, Yutong Gao, Qimei Cui, Xiaofeng Tao
Image retrieval from contextual descriptions (IRCD) aims to identify an image within a set of minimally contrastive candidates based on linguistically complex text. Despite the success of VLMs, they still significantly lag behind human performance in IRCD. The main challenges lie in aligning key contextual cues in two modalities, where these subtle cues are concealed in tiny areas of multiple contrastive images and within the complex linguistics of textual descriptions. This motivates us to propose ContextBLIP, a simple yet effective method that relies on a doubly contextual alignment scheme for challenging IRCD. Specifically, 1) our model comprises a multi-scale adapter, a matching loss, and a text-guided masking loss. The adapter learns to capture fine-grained visual cues. The two losses enable iterative supervision for the adapter, gradually highlighting the focal patches of a single image to the key textual cues. We term such a way as intra-contextual alignment. 2) Then, ContextBLIP further employs an inter-context encoder to learn dependencies among candidates, facilitating alignment between the text to multiple images. We term this step as inter-contextual alignment. Consequently, the nuanced cues concealed in each modality can be effectively aligned. Experiments on two benchmarks show the superiority of our method. We observe that ContextBLIP can yield comparable results with GPT-4V, despite involving about 7,500 times fewer parameters.
Read more5/30/2024
0
Multimodal Contrastive In-Context Learning
Yosuke Miyanishi, Minh Le Nguyen
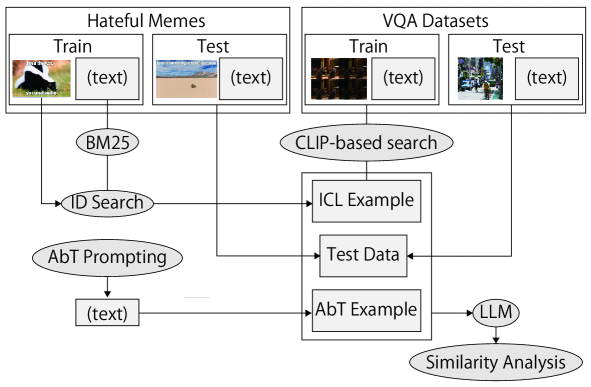
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Read more8/26/2024
👀
0
Towards Multimodal In-Context Learning for Vision & Language Models
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky
State-of-the-art Vision-Language Models (VLMs) ground the vision and the language modality primarily via projecting the vision tokens from the encoder to language-like tokens, which are directly fed to the Large Language Model (LLM) decoder. While these models have shown unprecedented performance in many downstream zero-shot tasks (eg image captioning, question answers, etc), still little emphasis has been put on transferring one of the core LLM capability of In-Context Learning (ICL). ICL is the ability of a model to reason about a downstream task with a few examples demonstrations embedded in the prompt. In this work, through extensive evaluations, we find that the state-of-the-art VLMs somewhat lack the ability to follow ICL instructions. In particular, we discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot demonstrations (in an ICL way), likely due to their lack of direct ICL instruction tuning. To enhance the ICL abilities of the present VLM, we propose a simple yet surprisingly effective multi-turn curriculum-based learning methodology with effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. Furthermore, we also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Read more7/18/2024

0
Context-Aware Image Descriptions for Web Accessibility
Ananya Gubbi Mohanbabu, Amy Pavel
Blind and low vision (BLV) internet users access images on the web via text descriptions. New vision-to-language models such as GPT-V, Gemini, and LLaVa can now provide detailed image descriptions on-demand. While prior research and guidelines state that BLV audiences' information preferences depend on the context of the image, existing tools for accessing vision-to-language models provide only context-free image descriptions by generating descriptions for the image alone without considering the surrounding webpage context. To explore how to integrate image context into image descriptions, we designed a Chrome Extension that automatically extracts webpage context to inform GPT-4V-generated image descriptions. We gained feedback from 12 BLV participants in a user study comparing typical context-free image descriptions to context-aware image descriptions. We then further evaluated our context-informed image descriptions with a technical evaluation. Our user evaluation demonstrated that BLV participants frequently prefer context-aware descriptions to context-free descriptions. BLV participants also rated context-aware descriptions significantly higher in quality, imaginability, relevance, and plausibility. All participants shared that they wanted to use context-aware descriptions in the future and highlighted the potential for use in online shopping, social media, news, and personal interest blogs.
Read more9/6/2024