Context-aware Multi-Model Object Detection for Diversely Heterogeneous Compute Systems
2402.07415
0
0
Abstract
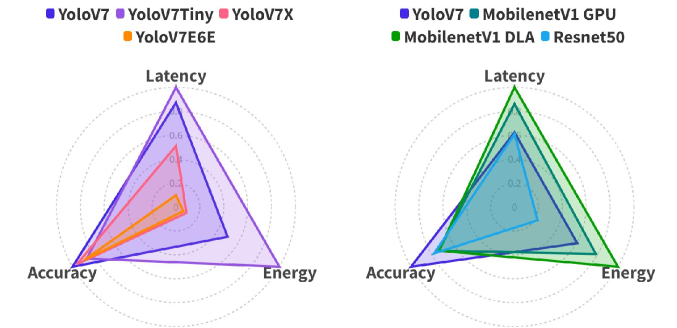
In recent years, deep neural networks (DNNs) have gained widespread adoption for continuous mobile object detection (OD) tasks, particularly in autonomous systems. However, a prevalent issue in their deployment is the one-size-fits-all approach, where a single DNN is used, resulting in inefficient utilization of computational resources. This inefficiency is particularly detrimental in energy-constrained systems, as it degrades overall system efficiency. We identify that, the contextual information embedded in the input data stream (e.g. the frames in the camera feed that the OD models are run on) could be exploited to allow a more efficient multi-model-based OD process. In this paper, we propose SHIFT which continuously selects from a variety of DNN-based OD models depending on the dynamically changing contextual information and computational constraints. During this selection, SHIFT uniquely considers multi-accelerator execution to better optimize the energy-efficiency while satisfying the latency constraints. Our proposed methodology results in improvements of up to 7.5x in energy usage and 2.8x in latency compared to state-of-the-art GPU-based single model OD approaches.
Create account to get full access
Overview
- This paper presents a context-aware multi-model object detection system for heterogeneous compute systems.
- The system leverages different object detection models optimized for various hardware accelerators like GPUs and CPUs to improve performance and efficiency.
- The context-aware component selects the appropriate model based on the input data and the available computing resources, ensuring optimal detection results.
Plain English Explanation
In this paper, the researchers have developed a smart object detection system that can adapt to different computing hardware. Object detection is a computer vision task where the goal is to identify and locate objects in an image or video. Traditionally, a single object detection model is used, but this may not be the best fit for all types of hardware.
The researchers' system uses multiple object detection models, each optimized for a specific type of hardware like graphics processing units (GPUs) or central processing units (CPUs). When an image or video is analyzed, the system automatically selects the most appropriate model based on the input data and the available computing resources. This "context-aware" approach ensures that the object detection is performed efficiently and accurately, regardless of the underlying hardware.
For example, if the input is a high-resolution image and a powerful GPU is available, the system might choose a more complex and accurate model to take full advantage of the GPU's capabilities. On the other hand, if the input is a low-resolution video and only a CPU is available, the system might select a simpler and faster model to maintain real-time performance.
By adapting to the context, this system can provide optimal object detection results on a wide range of computing devices, from powerful servers to resource-constrained embedded systems. This flexibility is particularly important in autonomous systems, where object detection is a critical task for tasks like navigation and decision-making.
Technical Explanation
The proposed system, ContextualFusion, is a context-aware multi-model object detection framework designed for heterogeneous computing environments. The key components of the system are:
-
Multi-Model Object Detectors: The system integrates multiple object detection models, each optimized for a specific hardware accelerator (e.g., GPU, CPU). This allows the system to leverage the strengths of different models and hardware configurations.
-
Context-Aware Model Selection: The system dynamically selects the most appropriate object detection model based on the input data (e.g., image resolution, frame rate) and the available computing resources (e.g., GPU, CPU). This context-aware model selection ensures optimal performance and efficiency.
-
Hardware-Aware Model Optimization: The object detection models are optimized for specific hardware configurations, taking into account factors such as memory footprint, computational complexity, and latency. This allows the models to fully utilize the capabilities of the underlying hardware.
The researchers evaluate their system on a diverse set of hardware platforms, including high-performance servers, mobile devices, and embedded systems. The results show that the context-aware multi-model approach outperforms traditional single-model object detection systems in terms of both accuracy and efficiency.
Critical Analysis
The researchers have made a compelling case for the benefits of a context-aware multi-model object detection system in heterogeneous computing environments. By dynamically selecting the most appropriate model based on the input data and available hardware, the system can provide optimal performance and efficiency across a wide range of computing devices.
However, the paper does not address the potential challenges of model management and deployment in real-world scenarios. Maintaining and updating multiple object detection models, each optimized for a specific hardware configuration, could be a complex and resource-intensive task. Additionally, the researchers do not discuss the implications of model selection errors or the impact of changes in the computing environment on the system's performance.
Further research is needed to explore the practical deployment and maintenance of such a context-aware multi-model object detection system, as well as the potential trade-offs between model complexity, accuracy, and efficiency. Additionally, the system's ability to adapt to evolving hardware and software constraints over time should be investigated.
Conclusion
The ContextualFusion system presented in this paper demonstrates a promising approach to object detection in heterogeneous computing environments. By leveraging multiple object detection models and dynamically selecting the most appropriate one based on the input data and available hardware, the system can deliver optimal performance and efficiency.
This context-aware, multi-model approach has significant implications for a wide range of applications, particularly in autonomous systems and edge computing, where object detection is a critical task. The ability to adapt to diverse computing hardware and changing environmental conditions can enhance the reliability, robustness, and versatility of these systems.
As the field of computer vision and edge computing continues to evolve, the principles and techniques explored in this paper may serve as a foundation for future research and development in context-aware, hardware-accelerated object detection and other computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Leveraging AutoML for Sustainable Deep Learning: A Multi-Objective HPO Approach on Deep Shift Neural Networks
Leona Hennig, Tanja Tornede, Marius Lindauer
0
0
Deep Learning (DL) has advanced various fields by extracting complex patterns from large datasets. However, the computational demands of DL models pose environmental and resource challenges. Deep shift neural networks (DSNNs) offer a solution by leveraging shift operations to reduce computational complexity at inference. Following the insights from standard DNNs, we are interested in leveraging the full potential of DSNNs by means of AutoML techniques. We study the impact of hyperparameter optimization (HPO) to maximize DSNN performance while minimizing resource consumption. Since this combines multi-objective (MO) optimization with accuracy and energy consumption as potentially complementary objectives, we propose to combine state-of-the-art multi-fidelity (MF) HPO with multi-objective optimization. Experimental results demonstrate the effectiveness of our approach, resulting in models with over 80% in accuracy and low computational cost. Overall, our method accelerates efficient model development while enabling sustainable AI applications.
4/5/2024
📶
Leveraging Systematic Knowledge of 2D Transformations
Jiachen Kang, Wenjing Jia, Xiangjian He
0
0
The existing deep learning models suffer from out-of-distribution (o.o.d.) performance drop in computer vision tasks. In comparison, humans have a remarkable ability to interpret images, even if the scenes in the images are rare, thanks to the systematicity of acquired knowledge. This work focuses on 1) the acquisition of systematic knowledge of 2D transformations, and 2) architectural components that can leverage the learned knowledge in image classification tasks in an o.o.d. setting. With a new training methodology based on synthetic datasets that are constructed under the causal framework, the deep neural networks acquire knowledge from semantically different domains (e.g. even from noise), and exhibit certain level of systematicity in parameter estimation experiments. Based on this, a novel architecture is devised consisting of a classifier, an estimator and an identifier (abbreviated as CED). By emulating the hypothesis-verification process in human visual perception, CED improves the classification accuracy significantly on test sets under covariate shift.
4/24/2024
🔎
Active Object Detection with Knowledge Aggregation and Distillation from Large Models
Dejie Yang, Yang Liu
0
0
Accurately detecting active objects undergoing state changes is essential for comprehending human interactions and facilitating decision-making. The existing methods for active object detection (AOD) primarily rely on visual appearance of the objects within input, such as changes in size, shape and relationship with hands. However, these visual changes can be subtle, posing challenges, particularly in scenarios with multiple distracting no-change instances of the same category. We observe that the state changes are often the result of an interaction being performed upon the object, thus propose to use informed priors about object related plausible interactions (including semantics and visual appearance) to provide more reliable cues for AOD. Specifically, we propose a knowledge aggregation procedure to integrate the aforementioned informed priors into oracle queries within the teacher decoder, offering more object affordance commonsense to locate the active object. To streamline the inference process and reduce extra knowledge inputs, we propose a knowledge distillation approach that encourages the student decoder to mimic the detection capabilities of the teacher decoder using the oracle query by replicating its predictions and attention. Our proposed framework achieves state-of-the-art performance on four datasets, namely Ego4D, Epic-Kitchens, MECCANO, and 100DOH, which demonstrates the effectiveness of our approach in improving AOD.
5/22/2024
👁️
Investigating Robustness of Open-Vocabulary Foundation Object Detectors under Distribution Shifts
Prakash Chandra Chhipa, Kanjar De, Meenakshi Subhash Chippa, Rajkumar Saini, Marcus Liwicki
0
0
The challenge of Out-Of-Distribution (OOD) robustness remains a critical hurdle towards deploying deep vision models. Open-vocabulary object detection extends the capabilities of traditional object detection frameworks to recognize and classify objects beyond predefined categories. Investigating OOD robustness in open-vocabulary object detection is essential to increase the trustworthiness of these models. This study presents a comprehensive robustness evaluation of zero-shot capabilities of three recent open-vocabulary foundation object detection models, namely OWL-ViT, YOLO World, and Grounding DINO. Experiments carried out on the COCO-O and COCO-C benchmarks encompassing distribution shifts highlight the challenges of the models' robustness. Source code shall be made available to the research community on GitHub.
6/4/2024