Towards Leveraging AutoML for Sustainable Deep Learning: A Multi-Objective HPO Approach on Deep Shift Neural Networks
2404.01965
0
0

Abstract
Deep Learning (DL) has advanced various fields by extracting complex patterns from large datasets. However, the computational demands of DL models pose environmental and resource challenges. Deep shift neural networks (DSNNs) offer a solution by leveraging shift operations to reduce computational complexity at inference. Following the insights from standard DNNs, we are interested in leveraging the full potential of DSNNs by means of AutoML techniques. We study the impact of hyperparameter optimization (HPO) to maximize DSNN performance while minimizing resource consumption. Since this combines multi-objective (MO) optimization with accuracy and energy consumption as potentially complementary objectives, we propose to combine state-of-the-art multi-fidelity (MF) HPO with multi-objective optimization. Experimental results demonstrate the effectiveness of our approach, resulting in models with over 80% in accuracy and low computational cost. Overall, our method accelerates efficient model development while enabling sustainable AI applications.
Create account to get full access
Overview
- The paper proposes a multi-objective hyperparameter optimization (HPO) approach for training Deep Shift Neural Networks, a type of deep learning model.
- The goal is to make deep learning models more sustainable by optimizing for both accuracy and energy efficiency during the model training process.
- The authors use AutoML techniques to automate the HPO process, which can be complex and time-consuming when done manually.
Plain English Explanation
The researchers are working on making deep learning models more environmentally friendly and efficient to use. Deep learning models, which are a type of artificial intelligence, can be very powerful but also require a lot of computing power and energy to train and run. This can be costly and have a significant environmental impact.
The researchers propose a new approach that tries to optimize deep learning models for both high accuracy and low energy consumption during the training process. Normally, model training involves manually tuning many different hyperparameters, which can be a complex and time-consuming task. The researchers use automated machine learning (AutoML) techniques to automate this hyperparameter optimization (HPO) process.
The specific deep learning model they focus on is called a "Deep Shift Neural Network". This type of model is designed to be more efficient and adaptable than traditional deep learning architectures. By using AutoML to optimize these models for both accuracy and energy efficiency, the researchers hope to develop deep learning systems that are more sustainable and environmentally friendly.
Technical Explanation
The paper focuses on Deep Shift Neural Networks (DSNNs), a novel deep learning architecture that aims to be more efficient and flexible than traditional deep neural networks. The authors propose a multi-objective hyperparameter optimization (HPO) approach to train DSNNs, jointly optimizing for both accuracy and energy efficiency.
The HPO process involves searching over a large space of possible hyperparameter configurations to find the ones that result in the best trade-off between model performance and energy consumption. The authors leverage AutoML techniques to automate this search, as manually tuning all the hyperparameters would be extremely time-consuming.
The multi-objective nature of the optimization means the algorithm tries to find hyperparameter settings that maximize accuracy while minimizing energy usage, rather than just optimizing for one objective. This results in a Pareto front of non-dominated solutions that represent different accuracy-efficiency trade-offs.
The authors conduct experiments on several benchmark datasets and show that their multi-objective HPO approach can produce DSNNs that are more energy efficient than traditional deep neural networks, while maintaining competitive accuracy. This highlights the potential for using AutoML and multi-objective optimization to develop more sustainable deep learning systems.
Critical Analysis
The paper provides a promising approach for improving the energy efficiency of deep learning models without significantly sacrificing accuracy. The use of multi-objective optimization to jointly consider both performance and energy consumption is a key strength, as it avoids the need to make arbitrary trade-offs between these competing objectives.
However, the paper does not provide a detailed analysis of the computational costs and time requirements of the AutoML-based HPO process. While automated hyperparameter tuning can be more efficient than manual search, it may still be computationally intensive, especially for large-scale deep learning models. The authors should further investigate the scalability and practicality of their approach for real-world deployment.
Additionally, the paper focuses solely on improving the energy efficiency of model training, but does not address the energy consumption during model inference (when the model is actually being used for predictions). In many real-world applications, the inference phase can be the dominant source of energy usage, so future work should also optimize for efficient model inference.
Conclusion
Overall, this paper presents a valuable contribution towards developing more sustainable deep learning systems. By leveraging AutoML and multi-objective optimization techniques, the authors demonstrate a promising approach for training energy-efficient deep learning models without compromising accuracy. As deep learning continues to be widely adopted in various applications, finding ways to improve the environmental impact of these models will be crucial for ensuring the long-term sustainability of the technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Combining Multi-Objective Bayesian Optimization with Reinforcement Learning for TinyML
Mark Deutel, Georgios Kontes, Christopher Mutschler, Jurgen Teich
0
0
Deploying Deep Neural Networks (DNNs) on microcontrollers (TinyML) is a common trend to process the increasing amount of sensor data generated at the edge, but in practice, resource and latency constraints make it difficult to find optimal DNN candidates. Neural Architecture Search (NAS) is an excellent approach to automate this search and can easily be combined with DNN compression techniques commonly used in TinyML. However, many NAS techniques are not only computationally expensive, especially hyperparameter optimization (HPO), but also often focus on optimizing only a single objective, e.g., maximizing accuracy, without considering additional objectives such as memory consumption or computational complexity of a DNN, which are key to making deployment at the edge feasible. In this paper, we propose a novel NAS strategy for TinyML based on Multi-Objective Bayesian optimization (MOBOpt) and an ensemble of competing parametric policies trained using Augmented Random Search (ARS) Reinforcement Learning (RL) agents. Our methodology aims at efficiently finding tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
6/7/2024
🛠️
Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
Ibrahim Shaer, Soodeh Nikan, Abdallah Shami
0
0
The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
5/3/2024

Hybrid Preference Optimization: Augmenting Direct Preference Optimization with Auxiliary Objectives
Anirudhan Badrinath, Prabhat Agarwal, Jiajing Xu
0
0
For aligning large language models (LLMs), prior work has leveraged reinforcement learning via human feedback (RLHF) or variations of direct preference optimization (DPO). While DPO offers a simpler framework based on maximum likelihood estimation, it compromises on the ability to tune language models to easily maximize non-differentiable and non-binary objectives according to the LLM designer's preferences (e.g., using simpler language or minimizing specific kinds of harmful content). These may neither align with user preferences nor even be able to be captured tractably by binary preference data. To leverage the simplicity and performance of DPO with the generalizability of RL, we propose a hybrid approach between DPO and RLHF. With a simple augmentation to the implicit reward decomposition of DPO, we allow for tuning LLMs to maximize a set of arbitrary auxiliary rewards using offline RL. The proposed method, Hybrid Preference Optimization (HPO), shows the ability to effectively generalize to both user preferences and auxiliary designer objectives, while preserving alignment performance across a range of challenging benchmarks and model sizes.
5/31/2024
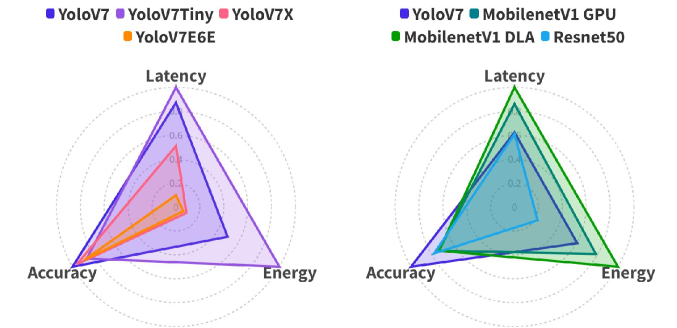
Context-aware Multi-Model Object Detection for Diversely Heterogeneous Compute Systems
Justin Davis, Mehmet E. Belviranli
0
0
In recent years, deep neural networks (DNNs) have gained widespread adoption for continuous mobile object detection (OD) tasks, particularly in autonomous systems. However, a prevalent issue in their deployment is the one-size-fits-all approach, where a single DNN is used, resulting in inefficient utilization of computational resources. This inefficiency is particularly detrimental in energy-constrained systems, as it degrades overall system efficiency. We identify that, the contextual information embedded in the input data stream (e.g. the frames in the camera feed that the OD models are run on) could be exploited to allow a more efficient multi-model-based OD process. In this paper, we propose SHIFT which continuously selects from a variety of DNN-based OD models depending on the dynamically changing contextual information and computational constraints. During this selection, SHIFT uniquely considers multi-accelerator execution to better optimize the energy-efficiency while satisfying the latency constraints. Our proposed methodology results in improvements of up to 7.5x in energy usage and 2.8x in latency compared to state-of-the-art GPU-based single model OD approaches.
4/30/2024