Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning

0
Sign in to get full access
Overview
- The paper presents a novel approach for context-aware visual storytelling using visual prefix tuning and contrastive learning.
- It aims to generate more coherent and engaging stories by leveraging contextual information from the input images.
- The proposed method outperforms state-of-the-art visual storytelling models on various evaluation metrics.
Plain English Explanation
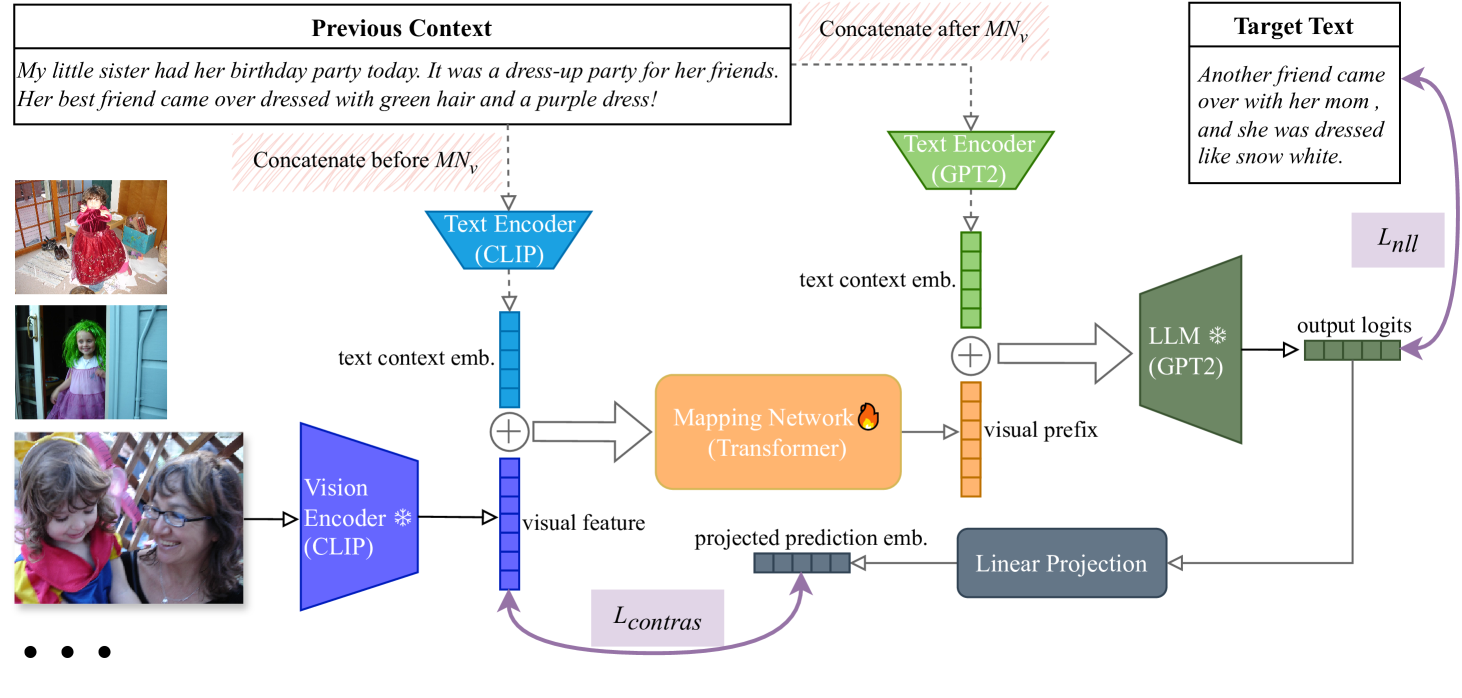
The paper introduces a new way to create stories based on a set of images. Typically, visual storytelling models struggle to incorporate the broader context of the images, leading to disjointed or unnatural narratives. To address this, the researchers developed a technique called "visual prefix tuning" that helps the model better understand the overall context of the images.
Additionally, they use "contrastive learning," a way of training the model to learn meaningful relationships between the images and the corresponding story. This allows the model to generate more coherent and engaging stories that are tailored to the specific context of the input images.
Through experiments, the researchers show that their approach outperforms other state-of-the-art visual storytelling models in terms of various evaluation metrics, such as the coherence and interestingness of the generated stories.
Technical Explanation
The paper proposes a context-aware visual storytelling model that leverages visual prefix tuning and contrastive learning techniques. Visual prefix tuning allows the model to better incorporate the broader context of the input images, while contrastive learning helps the model learn meaningful relationships between the images and the corresponding story.
The model first encodes the input images using a pre-trained vision transformer. It then uses the visual prefix tuning mechanism to capture the contextual information from the image features. The story generation component is a transformer-based language model that is trained using contrastive learning, where it learns to generate stories that are aligned with the visual context.
The researchers evaluate their approach on several visual storytelling datasets and demonstrate that it outperforms state-of-the-art models in terms of story coherence, interest, and other metrics.
Critical Analysis
The paper addresses an important challenge in visual storytelling, which is the need to generate narratives that are coherent and tailored to the specific context of the input images. The proposed approach of leveraging visual prefix tuning and contrastive learning seems promising and the experimental results are encouraging.
However, the paper does not discuss any potential limitations or caveats of the proposed method. For example, it would be helpful to understand how the model performs on more complex or diverse visual scenarios, or how it might handle ambiguous or conflicting contextual information in the input images.
Additionally, the paper does not provide much insight into the specific mechanisms or inner workings of the visual prefix tuning and contrastive learning components. A more detailed technical explanation of these key elements could help the reader better understand the strengths and weaknesses of the approach.
Conclusion
The paper presents a novel context-aware visual storytelling model that leverages visual prefix tuning and contrastive learning to generate more coherent and engaging narratives. The experimental results demonstrate the effectiveness of the proposed approach, which could have important implications for various applications, such as automatic content generation, interactive storytelling, and educational tools.
While the paper shows promising results, further research is needed to explore the limitations and potential improvements of the model, as well as its applicability to a wider range of visual storytelling scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
Yingjin Song, Denis Paperno, Albert Gatt
Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.
Read more8/13/2024
💬
0
Improving Visual Storytelling with Multimodal Large Language Models
Xiaochuan Lin, Xiangyong Chen
Visual storytelling is an emerging field that combines images and narratives to create engaging and contextually rich stories. Despite its potential, generating coherent and emotionally resonant visual stories remains challenging due to the complexity of aligning visual and textual information. This paper presents a novel approach leveraging large language models (LLMs) and large vision-language models (LVLMs) combined with instruction tuning to address these challenges. We introduce a new dataset comprising diverse visual stories, annotated with detailed captions and multimodal elements. Our method employs a combination of supervised and reinforcement learning to fine-tune the model, enhancing its narrative generation capabilities. Quantitative evaluations using GPT-4 and qualitative human assessments demonstrate that our approach significantly outperforms existing models, achieving higher scores in narrative coherence, relevance, emotional depth, and overall quality. The results underscore the effectiveness of instruction tuning and the potential of LLMs/LVLMs in advancing visual storytelling.
Read more7/4/2024
📶
0
ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
Rohan Wadhawan, Hritik Bansal, Kai-Wei Chang, Nanyun Peng
Many real-world tasks require an agent to reason jointly over text and visual objects, (e.g., navigating in public spaces), which we refer to as context-sensitive text-rich visual reasoning. Specifically, these tasks require an understanding of the context in which the text interacts with visual elements within an image. However, there is a lack of existing datasets to benchmark the state-of-the-art multimodal models' capability on context-sensitive text-rich visual reasoning. In this paper, we introduce ConTextual, a novel dataset featuring human-crafted instructions that require context-sensitive reasoning for text-rich images. We conduct experiments to assess the performance of 14 foundation models (GPT-4V, Gemini-Pro-Vision, LLaVA-Next) and establish a human performance baseline. Further, we perform human evaluations of the model responses and observe a significant performance gap of 30.8% between GPT-4V (the current best-performing Large Multimodal Model) and human performance. Our fine-grained analysis reveals that GPT-4V encounters difficulties interpreting time-related data and infographics. However, it demonstrates proficiency in comprehending abstract visual contexts such as memes and quotes. Finally, our qualitative analysis uncovers various factors contributing to poor performance including lack of precise visual perception and hallucinations. Our dataset, code, and leaderboard can be found on the project page https://con-textual.github.io/
Read more7/17/2024

0
Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
Read more4/26/2024