ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models

0
📶
Sign in to get full access
Overview
- This paper introduces a new dataset called ConTextual that was created to evaluate the capabilities of state-of-the-art multimodal models on context-sensitive text-rich visual reasoning tasks.
- The authors conduct experiments to assess the performance of 14 foundation models, including GPT-4V, Gemini-Pro-Vision, and LLaVA-Next, and establish a human performance baseline.
- The results reveal a significant performance gap of 30.8% between the best-performing large multimodal model (GPT-4V) and human performance, with the models struggling on tasks involving time-related data and infographics.
Plain English Explanation
Many real-world tasks, such as navigating public spaces, require an agent to understand how text and visual elements interact within a specific context. This is known as context-sensitive text-rich visual reasoning. However, there has been a lack of datasets to measure how well current multimodal models can perform on these types of tasks.
To address this, the researchers created a new dataset called ConTextual, which features human-crafted instructions that require context-sensitive reasoning for text-rich images. They then tested 14 different foundation models, including some of the latest and most advanced large multimodal models, to see how well they could perform on the tasks in the dataset.
The results showed a significant gap between the best-performing model (GPT-4V) and human performance, with the models struggling particularly on tasks involving time-related information and infographics. However, the models did demonstrate some proficiency in understanding abstract visual contexts, such as memes and quotes.
The researchers also conducted a more detailed analysis to uncover the factors contributing to the models' poor performance, such as a lack of precise visual perception and a tendency to hallucinate or generate incorrect information.
Technical Explanation
The researchers first identified the need for a dataset to evaluate the context-sensitive text-rich visual reasoning capabilities of state-of-the-art multimodal models. They created the ConTextual dataset, which features human-crafted instructions that require understanding the interplay between text and visual elements within an image.
To assess the performance of leading models on this task, the researchers conducted experiments with 14 foundation models, including GPT-4V, Gemini-Pro-Vision, and LLaVA-Next. They also established a human performance baseline for comparison.
The results showed that GPT-4V, the current best-performing large multimodal model, had a 30.8% performance gap compared to human performance. Further analysis revealed that the models struggled with tasks involving time-related data and infographics, but demonstrated proficiency in comprehending abstract visual contexts like memes and quotes.
The researchers performed a qualitative analysis to uncover the factors contributing to the models' poor performance, such as a lack of precise visual perception and a tendency to hallucinate or generate incorrect information. This provides valuable insights into the current limitations of these models and areas for future improvement.
Critical Analysis
The researchers have done a commendable job in creating the ConTextual dataset to address the lack of existing datasets for evaluating context-sensitive text-rich visual reasoning. This is an important step in pushing the boundaries of multimodal AI systems and understanding their current capabilities and limitations.
However, the paper does not delve into the potential reasons why the models struggled with tasks involving time-related data and infographics. It would be helpful to understand if this is a fundamental limitation of the models or a result of biases in the training data or model architecture.
Additionally, the paper could have explored the performance of the models on different types of abstract visual contexts, such as political cartoons or artistic images, to gain a more nuanced understanding of their strengths and weaknesses. Probing the Conceptual Understanding of Large Visual-Language Models and CODIS: Benchmarking Context-Dependent Visual Comprehension in Multimodal provide relevant insights that could inform future research in this area.
Furthermore, the paper could have discussed the implications of the performance gap between the models and human performance, particularly in the context of real-world applications where context-sensitive text-rich visual reasoning is crucial, such as Detecting Multimodal Situations with Insufficient Context: Abstaining from Prediction and Dual Modalities: Text and Visual Textual Generative Pre-training.
Overall, the ConTextual dataset and the insights gained from this research are valuable contributions to the field of multimodal AI, but there is still room for further exploration and refinement.
Conclusion
This paper introduces a novel dataset called ConTextual that was created to evaluate the context-sensitive text-rich visual reasoning capabilities of state-of-the-art multimodal models. The researchers conducted experiments with 14 foundation models and found a significant performance gap of 30.8% between the best-performing model (GPT-4V) and human performance.
The analysis revealed that the models struggled with tasks involving time-related data and infographics, but demonstrated proficiency in understanding abstract visual contexts like memes and quotes. The researchers also identified factors such as a lack of precise visual perception and a tendency to hallucinate as contributors to the models' poor performance.
The ConTextual dataset and the insights from this research represent an important step forward in the field of multimodal AI, as they highlight the current limitations of these models and provide a benchmark for future improvements. As multimodal AI systems continue to advance, the ability to reason effectively across text and visual elements within a specific context will become increasingly crucial for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
Rohan Wadhawan, Hritik Bansal, Kai-Wei Chang, Nanyun Peng
Many real-world tasks require an agent to reason jointly over text and visual objects, (e.g., navigating in public spaces), which we refer to as context-sensitive text-rich visual reasoning. Specifically, these tasks require an understanding of the context in which the text interacts with visual elements within an image. However, there is a lack of existing datasets to benchmark the state-of-the-art multimodal models' capability on context-sensitive text-rich visual reasoning. In this paper, we introduce ConTextual, a novel dataset featuring human-crafted instructions that require context-sensitive reasoning for text-rich images. We conduct experiments to assess the performance of 14 foundation models (GPT-4V, Gemini-Pro-Vision, LLaVA-Next) and establish a human performance baseline. Further, we perform human evaluations of the model responses and observe a significant performance gap of 30.8% between GPT-4V (the current best-performing Large Multimodal Model) and human performance. Our fine-grained analysis reveals that GPT-4V encounters difficulties interpreting time-related data and infographics. However, it demonstrates proficiency in comprehending abstract visual contexts such as memes and quotes. Finally, our qualitative analysis uncovers various factors contributing to poor performance including lack of precise visual perception and hallucinations. Our dataset, code, and leaderboard can be found on the project page https://con-textual.github.io/
Read more7/17/2024
💬
0
Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions
Junzhang Liu, Zhecan Wang, Hammad Ayyubi, Haoxuan You, Chris Thomas, Rui Sun, Shih-Fu Chang, Kai-Wei Chang
Despite the widespread adoption of Vision-Language Understanding (VLU) benchmarks such as VQA v2, OKVQA, A-OKVQA, GQA, VCR, SWAG, and VisualCOMET, our analysis reveals a pervasive issue affecting their integrity: these benchmarks contain samples where answers rely on assumptions unsupported by the provided context. Training models on such data foster biased learning and hallucinations as models tend to make similar unwarranted assumptions. To address this issue, we collect contextual data for each sample whenever available and train a context selection module to facilitate evidence-based model predictions. Strong improvements across multiple benchmarks demonstrate the effectiveness of our approach. Further, we develop a general-purpose Context-AwaRe Abstention (CARA) detector to identify samples lacking sufficient context and enhance model accuracy by abstaining from responding if the required context is absent. CARA exhibits generalization to new benchmarks it wasn't trained on, underscoring its utility for future VLU benchmarks in detecting or cleaning samples with inadequate context. Finally, we curate a Context Ambiguity and Sufficiency Evaluation (CASE) set to benchmark the performance of insufficient context detectors. Overall, our work represents a significant advancement in ensuring that vision-language models generate trustworthy and evidence-based outputs in complex real-world scenarios.
Read more5/28/2024
0
Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
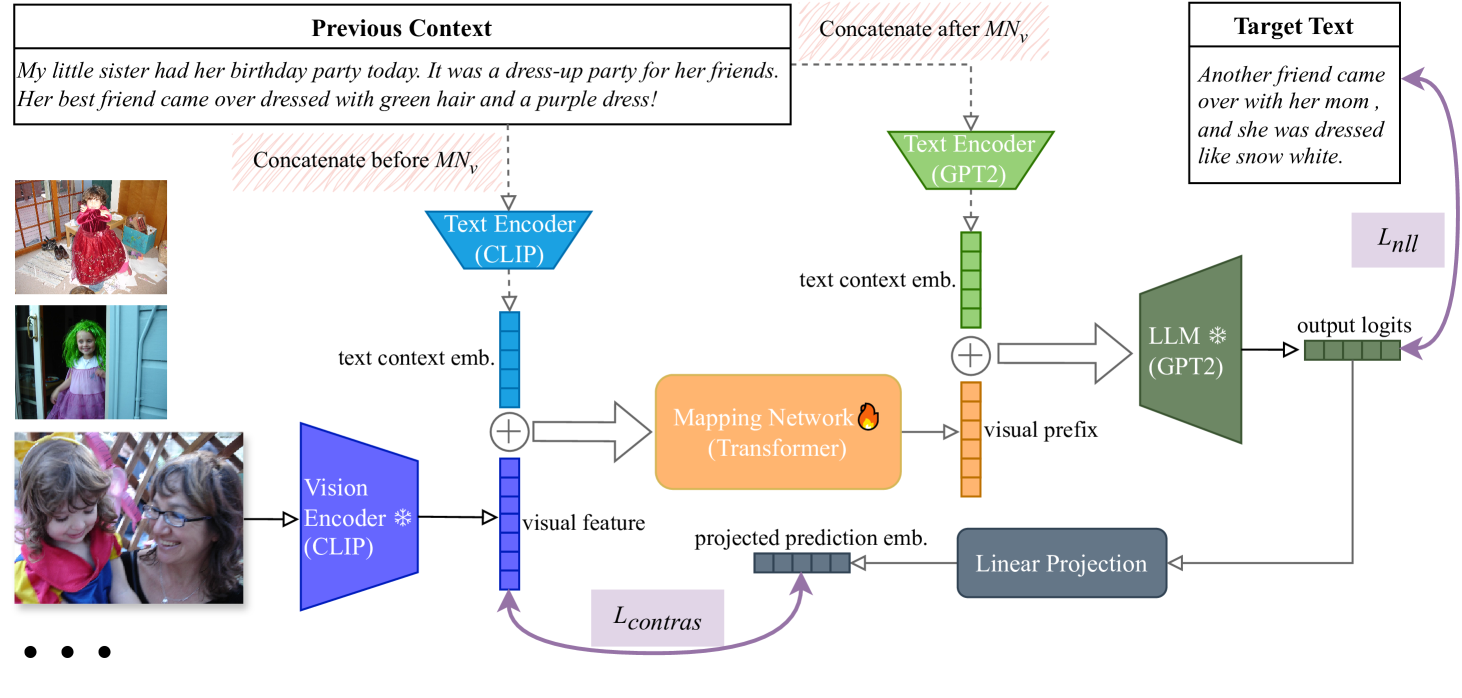
Yingjin Song, Denis Paperno, Albert Gatt
Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.
Read more8/13/2024
🤔
0
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
Read more4/29/2024