Context-Driven Index Trimming: A Data Quality Perspective to Enhancing Precision of RALMs

0

Sign in to get full access
Overview
- This paper explores a technique called "Context-Driven Index Trimming" to enhance the precision of Retrieval Augmented Language Models (RALMs).
- The researchers aim to address data quality issues in large-scale language model training by selectively trimming the index used for retrieval.
- The proposed method leverages the context of the input to identify relevant subsets of the retrieval index, improving the model's ability to retrieve the most pertinent information.
Plain English Explanation
The paper focuses on a method to make Retrieval Augmented Language Models (RALMs) more accurate. RALMs are a type of AI model that combines language understanding with the ability to retrieve relevant information from a database.
The key idea is that the information in a large database isn't always equally useful - some of it may be irrelevant or even misleading for a given task. The researchers developed a way to automatically identify the most relevant subset of the database based on the context of the input. This "context-driven index trimming" helps the RALM focus on the most helpful information, improving its overall performance.
Imagine you're trying to answer a question about the history of a specific city. A large database with information on many different cities would contain a lot of irrelevant data that could confuse the language model. But if the model could zero in on just the most pertinent information about that one city, it would be better equipped to provide an accurate answer. That's the key insight behind this work.
Technical Explanation
The paper proposes a technique called "Context-Driven Index Trimming" to enhance the performance of Retrieval Augmented Language Models (RALMs). RALMs combine language understanding with the ability to retrieve relevant information from a large index or database to aid in tasks like question answering.
The core idea is that the retrieval index used by the RALM may contain a significant amount of irrelevant or low-quality information that can negatively impact the model's precision. To address this, the researchers develop a method to selectively trim the retrieval index based on the context of the input.
Specifically, they train a neural network to predict a relevance score for each element in the retrieval index given the input context. They then use these relevance scores to filter out the least relevant index entries, effectively trimming the index to only the most pertinent information. This context-driven index trimming is designed to improve the RALM's ability to retrieve the most helpful information, leading to enhanced overall performance.
The paper evaluates this approach on several language understanding benchmarks, demonstrating improvements in accuracy and other metrics compared to baseline RALM models. The results suggest that carefully managing the quality and relevance of the retrieval index can be an important consideration for developing high-performing RALMs.
Critical Analysis
The paper presents a promising approach to enhancing the precision of Retrieval Augmented Language Models by selectively trimming the retrieval index. A key strength is the intuitive idea of leveraging the input context to identify the most relevant subset of the database, rather than blindly using the full index.
However, the paper does not provide a thorough analysis of the limitations or potential drawbacks of the technique. For example, it's unclear how the method would scale to extremely large retrieval indexes, or how sensitive the performance is to the quality of the relevance scoring model. Additionally, the paper does not explore the trade-offs between index trimming and other potential strategies for improving RALM performance, such as further model architectural changes or data quality enhancements.
Another area for further investigation is the generalizability of the approach. The experiments are primarily focused on language understanding benchmarks, but it would be valuable to understand how well the context-driven index trimming generalizes to other RALM use cases, such as open-ended question answering or dialogue systems.
Overall, the paper presents a compelling idea that merits further exploration. Careful consideration of the method's limitations and comparisons to alternative approaches could help strengthen the research and provide a more comprehensive understanding of the technique's capabilities and applicability.
Conclusion
This paper introduces a novel "Context-Driven Index Trimming" technique to enhance the precision of Retrieval Augmented Language Models (RALMs). The key insight is that the large retrieval indexes used by RALMs can contain significant amounts of irrelevant information, which can degrade the model's overall performance.
By training a relevance scoring model to selectively trim the retrieval index based on the input context, the researchers demonstrate improvements in accuracy and other metrics on language understanding benchmarks. This work highlights the importance of data quality management in large-scale language models and suggests that contextual information can be effectively leveraged to improve the precision of retrieval-augmented AI systems.
While the paper presents a promising approach, further research is needed to fully understand the limitations, trade-offs, and generalizability of the context-driven index trimming technique. Exploring its application to a broader range of RALM use cases and comparing it to alternative strategies could provide valuable insights for developing high-performing, data-efficient language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Context-Driven Index Trimming: A Data Quality Perspective to Enhancing Precision of RALMs
Kexin Ma, Ruochun Jin, Xi Wang, Huan Chen, Jing Ren, Yuhua Tang
Retrieval-Augmented Large Language Models (RALMs) have made significant strides in enhancing the accuracy of generated responses.However, existing research often overlooks the data quality issues within retrieval results, often caused by inaccurate existing vector-distance-based retrieval methods.We propose to boost the precision of RALMs' answers from a data quality perspective through the Context-Driven Index Trimming (CDIT) framework, where Context Matching Dependencies (CMDs) are employed as logical data quality rules to capture and regulate the consistency between retrieved contexts.Based on the semantic comprehension capabilities of Large Language Models (LLMs), CDIT can effectively identify and discard retrieval results that are inconsistent with the query context and further modify indexes in the database, thereby improving answer quality.Experiments demonstrate on challenging question-answering tasks.Also, the flexibility of CDIT is verified through its compatibility with various language models and indexing methods, which offers a promising approach to bolster RALMs' data quality and retrieval precision jointly.
Read more8/13/2024
🏷️
0
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, Scott Yih
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Read more5/7/2024

0
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, S'ebastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Read more6/21/2024
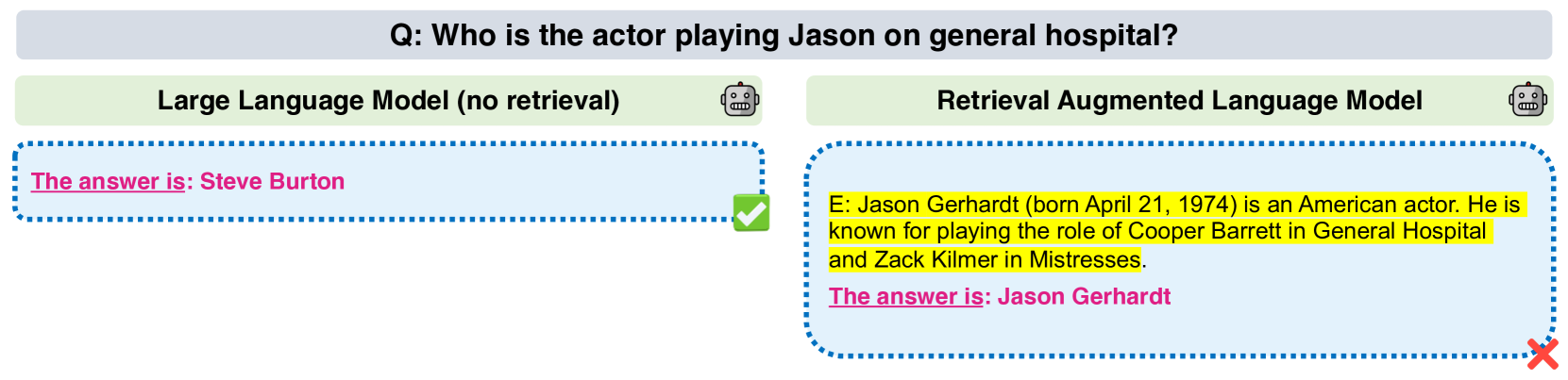
0
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Read more5/7/2024