In-Context Former: Lightning-fast Compressing Context for Large Language Model

0

Sign in to get full access
Overview
- Proposes a novel method called "In-Context Former" to efficiently compress and expand the context for large language models
- Aims to address the challenge of limited context window size in transformer models
- Introduces a lightweight compression module that can be integrated with any transformer-based language model
Plain English Explanation
The In-Context Former paper presents a new technique to help large language models, like GPT-3, better handle and process longer context.
One of the limitations of transformer-based models is that they have a fixed "context window" - the amount of previous text they can consider when generating new text. This context window is typically quite small, which can make it difficult for the model to understand and generate text that requires a broader understanding of the context.
The "In-Context Former" approach addresses this by introducing a lightweight module that can compress the context into a more compact representation. This allows the language model to effectively "remember" and utilize a much larger amount of previous text when generating new output. The compressed context can then be efficiently expanded back to its original form when needed.
By enabling language models to leverage more context, the In-Context Former can lead to improvements in tasks like question answering, text summarization, and coherent dialogue generation, where having a broader understanding of the context is crucial.
The key innovation of this work is the compression and expansion mechanism, which the authors show is very efficient and can be easily integrated into existing transformer-based language models.
Technical Explanation
The In-Context Former paper proposes a novel context compression and expansion module that can be seamlessly integrated into transformer-based language models.
The core idea is to learn a lightweight "compression" model that can take the full context (e.g., the entire history of previous tokens) and compress it into a much smaller representation. This compressed context can then be efficiently stored and used by the language model during inference.
When the language model needs to generate new output, the compressed context is "expanded" back to its original form using a companion "decompression" model. This allows the language model to effectively leverage a much larger context than would be possible with a fixed-size context window.
The authors demonstrate that their In-Context Former approach can achieve significant perplexity improvements on language modeling benchmarks, while adding only a small computational overhead to the base language model. They also show that the compressed context representation is highly compact, allowing for efficient storage and retrieval.
The key technical innovations include:
- A neural network architecture for the compression and decompression modules, which the authors show can be trained end-to-end with the language model
- Efficient attention-based mechanisms for compressing and expanding the context
- Strategies for integrating the In-Context Former with different transformer-based language models
Overall, the In-Context Former provides a promising approach for enhancing the context-awareness of large language models, with potential applications in a wide range of natural language processing tasks.
Critical Analysis
The In-Context Former paper presents a compelling solution to the challenge of limited context window size in transformer-based language models. The authors demonstrate the effectiveness of their approach through extensive experiments and comparisons to relevant baselines.
One potential limitation of the work is that the compression and decompression modules add additional computational overhead to the language model, which could impact inference speed and memory usage, especially for very large language models. The authors acknowledge this tradeoff and suggest that further optimization of the compression mechanism could help mitigate these concerns.
Additionally, the paper does not explore the potential impact of the In-Context Former on broader language understanding and generation tasks, beyond perplexity on language modeling benchmarks. It would be interesting to see how the enhanced context-awareness enabled by this approach translates to improvements in downstream applications, such as question answering, text summarization, or dialogue generation.
Another area for further research could be the robustness and generalization of the In-Context Former approach. The authors focus on evaluating their method on standard language modeling datasets, but it would be valuable to understand how well it performs in more diverse or challenging contexts, such as long-range dependencies or out-of-distribution examples.
Overall, the In-Context Former represents an important contribution to the field of large language model development, and its ideas could inspire further research and innovation in enhancing the context-awareness of transformer-based models.
Conclusion
The In-Context Former paper introduces a novel method for efficiently compressing and expanding the context used by large language models. By enabling these models to effectively leverage a much broader context, the In-Context Former approach has the potential to lead to significant improvements in a wide range of natural language processing tasks, from question answering to dialogue generation.
The key technical innovations, including the compression and decompression modules and the integration with transformer-based language models, represent an important step forward in enhancing the context-awareness of these powerful models. While the approach does introduce some additional computational overhead, the authors demonstrate that the benefits in terms of performance improvements can outweigh these costs.
As the field of large language models continues to evolve, the ideas and techniques presented in the In-Context Former paper will likely inspire further research and development, pushing the boundaries of what is possible in natural language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Former: Lightning-fast Compressing Context for Large Language Model
Xiangfeng Wang, Zaiyi Chen, Zheyong Xie, Tong Xu, Yongyi He, Enhong Chen
With the rising popularity of Transformer-based large language models (LLMs), reducing their high inference costs has become a significant research focus. One effective approach is to compress the long input contexts. Existing methods typically leverage the self-attention mechanism of the LLM itself for context compression. While these methods have achieved notable results, the compression process still involves quadratic time complexity, which limits their applicability. To mitigate this limitation, we propose the In-Context Former (IC-Former). Unlike previous methods, IC-Former does not depend on the target LLMs. Instead, it leverages the cross-attention mechanism and a small number of learnable digest tokens to directly condense information from the contextual word embeddings. This approach significantly reduces inference time, which achieves linear growth in time complexity within the compression range. Experimental results indicate that our method requires only 1/32 of the floating-point operations of the baseline during compression and improves processing speed by 68 to 112 times while achieving over 90% of the baseline performance on evaluation metrics. Overall, our model effectively reduces compression costs and makes real-time compression scenarios feasible.
Read more6/21/2024
0
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu
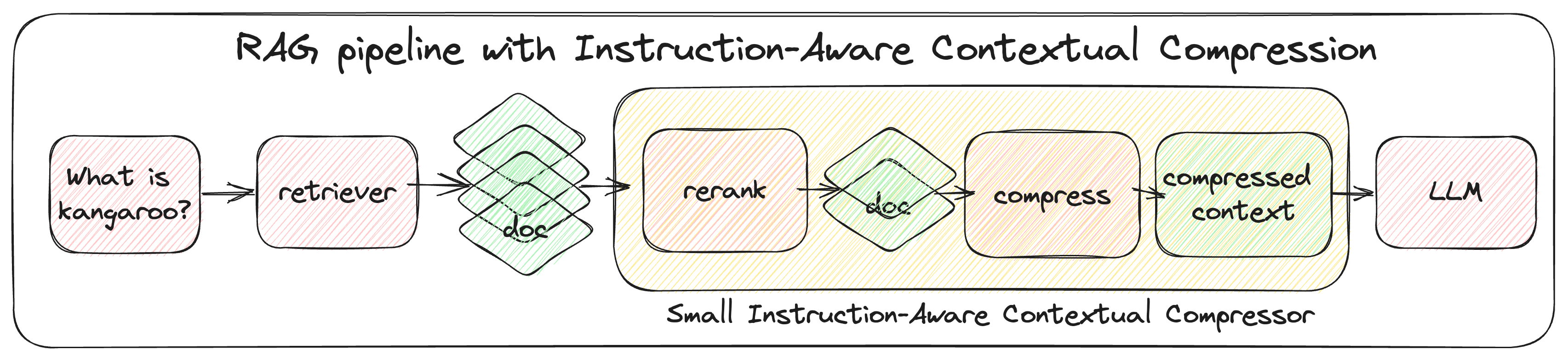
Large Language Models (LLMs) have garnered widespread attention due to their remarkable performance across various tasks. However, to mitigate the issue of hallucinations, LLMs often incorporate retrieval-augmented pipeline to provide them with rich external knowledge and context. Nevertheless, challenges stem from inaccurate and coarse-grained context retrieved from the retriever. Supplying irrelevant context to the LLMs can result in poorer responses, increased inference latency, and higher costs. This paper introduces a method called Instruction-Aware Contextual Compression, which filters out less informative content, thereby accelerating and enhancing the use of LLMs. The experimental results demonstrate that Instruction-Aware Contextual Compression notably reduces memory consumption and minimizes generation latency while maintaining performance levels comparable to those achieved with the use of the full context. Specifically, we achieved a 50% reduction in context-related costs, resulting in a 5% reduction in inference memory usage and a 2.2-fold increase in inference speed, with only a minor drop of 0.047 in Rouge-1. These findings suggest that our method strikes an effective balance between efficiency and performance.
Read more8/29/2024
27
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
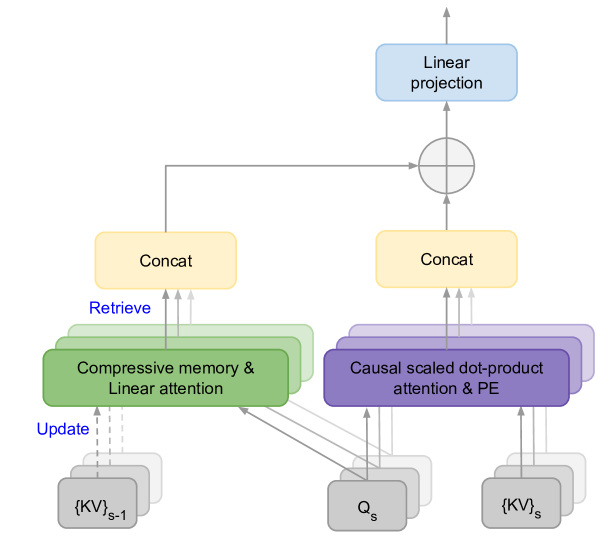
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024
0
Recurrent Context Compression: Efficiently Expanding the Context Window of LLM
Chensen Huang, Guibo Zhu, Xuepeng Wang, Yifei Luo, Guojing Ge, Haoran Chen, Dong Yi, Jinqiao Wang
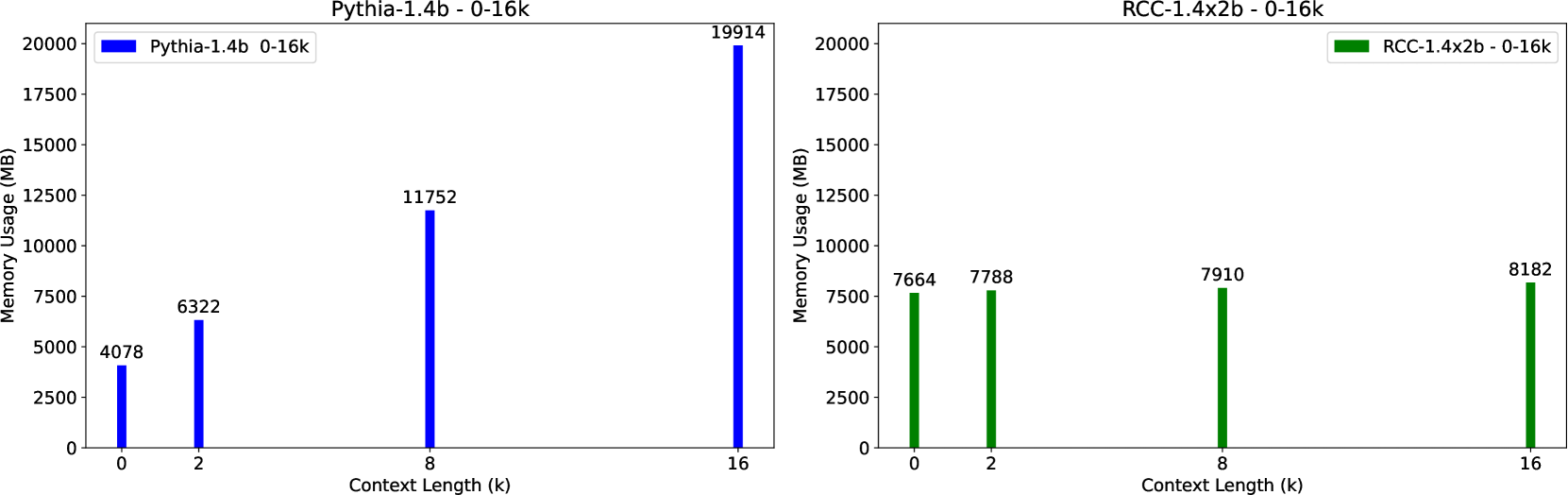
To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer
Read more6/11/2024