In-Context Learning with Reinforcement Learning for Incomplete Utterance Rewriting

0

Sign in to get full access
Overview
- Presents a reinforcement learning approach for incomplete utterance rewriting
- Aims to improve language models' ability to infer missing information and rewrite incomplete sentences
- Introduces an in-context learning framework that leverages reinforcement learning techniques
Plain English Explanation
The provided paper explores a reinforcement learning-based approach to help language models rewrite incomplete sentences. The core idea is to enable language models to infer and add missing information to incomplete utterances, improving their ability to generate coherent and contextually relevant text.
The researchers introduce an in-context learning framework that uses reinforcement learning techniques. This allows the model to learn how to rewrite incomplete sentences by receiving feedback and rewards based on the quality of its generated outputs.
The key benefit of this approach is that it can help language models better understand the contextual cues and semantic relationships needed to accurately complete partial sentences. This is an important capability for applications like dialogue systems, content generation, and language understanding.
Technical Explanation
The paper presents an in-context learning framework that leverages reinforcement learning to train language models for the task of incomplete utterance rewriting.
The proposed model takes an incomplete sentence as input and generates a rewritten version that adds the missing information. During training, the model receives a reward signal based on the quality of its output, which it uses to improve its rewriting capabilities through reinforcement learning.
The researchers experiment with different reward functions, including ones based on language model perplexity and human evaluations. They also explore the use of context learning techniques to incorporate additional contextual information that can aid the rewriting process.
The results demonstrate that the proposed approach can outperform baseline methods on the incomplete utterance rewriting task, highlighting the potential of reinforcement learning and in-context learning for improving language model capabilities in this area.
Critical Analysis
The paper presents a novel and promising approach to the problem of incomplete utterance rewriting, which is an important capability for many language-based applications. The use of reinforcement learning allows the model to learn how to effectively infer and add missing information, going beyond traditional language modeling approaches.
However, the paper does not fully address the potential limitations and challenges of this approach. For example, the reliance on human evaluations for reward signals could be problematic, as human judgments can be subjective and inconsistent. Additionally, the paper does not explore the model's performance on more complex or diverse types of incomplete utterances, which could reveal the approach's limitations or the need for further refinements.
Further research could investigate the scalability of the proposed framework, its robustness to different types of incomplete utterances, and the potential for incorporating additional contextual information beyond what is presented in the current work. Exploring the model's performance on real-world applications and gathering more extensive user feedback could also provide valuable insights.
Conclusion
The paper presents an innovative reinforcement learning-based approach to the problem of incomplete utterance rewriting, which is a crucial capability for language models in various applications. The in-context learning framework and the use of rewards based on language model perplexity and human evaluation demonstrate the potential of this approach to improve language models' ability to infer and add missing information.
While the paper shows promising results, further research is needed to address the potential limitations and explore the broader applicability of the proposed method. Investigating scalability, robustness, and the incorporation of additional contextual information could lead to continued advancements in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Learning with Reinforcement Learning for Incomplete Utterance Rewriting
Haowei Du, Dongyan Zhao
In-context learning (ICL) of large language models (LLMs) has attracted increasing attention in the community where LLMs make predictions only based on instructions augmented with a few examples. Existing example selection methods for ICL utilize sparse or dense retrievers and derive effective performance. However, these methods do not utilize direct feedback of LLM to train the retriever and the examples selected can not necessarily improve the analogy ability of LLM. To tackle this, we propose our policy-based reinforcement learning framework for example selection (RLS), which consists of a language model (LM) selector and an LLM generator. The LM selector encodes the candidate examples into dense representations and selects the top-k examples into the demonstration for LLM. The outputs of LLM are adopted to compute the reward and policy gradient to optimize the LM selector. We conduct experiments on different datasets and significantly outperform existing example selection methods. Moreover, our approach shows advantages over supervised finetuning (SFT) models in few shot setting. Further experiments show the balance of abundance and the similarity with the test case of examples is important for ICL performance of LLM.
Read more8/26/2024

0
Large Language Models Know What Makes Exemplary Contexts
Quanyu Long, Jianda Chen, Wenya Wang, Sinno Jialin Pan
In-context learning (ICL) has proven to be a significant capability with the advancement of Large Language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without needing to update millions of parameters. This paper presents a unified framework for LLMs that allows them to self-select influential in-context examples to compose their contexts; self-rank candidates with different demonstration compositions; self-optimize the demonstration selection and ordering through reinforcement learning. Specifically, our method designs a parameter-efficient retrieval head that generates the optimized demonstration after training with rewards from LLM's own preference. Experimental results validate the proposed method's effectiveness in enhancing ICL performance. Additionally, our approach effectively identifies and selects the most representative examples for the current task, and includes more diversity in retrieval.
Read more8/21/2024
📶
0
RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning
Alexander Scarlatos, Andrew Lan
Recent developments in large pre-trained language models have enabled unprecedented performance on a variety of downstream tasks. Achieving best performance with these models often leverages in-context learning, where a model performs a (possibly new) task given one or more examples. However, recent work has shown that the choice of examples can have a large impact on task performance and that finding an optimal set of examples is non-trivial. While there are many existing methods for selecting in-context examples, they generally score examples independently, ignoring the dependency between them and the order in which they are provided to the model. In this work, we propose Retrieval for In-Context Learning (RetICL), a learnable method for modeling and optimally selecting examples sequentially for in-context learning. We frame the problem of sequential example selection as a Markov decision process and train an example retriever using reinforcement learning. We evaluate RetICL on math word problem solving and scientific question answering tasks and show that it consistently outperforms or matches heuristic and learnable baselines. We also use case studies to show that RetICL implicitly learns representations of problem solving strategies.
Read more4/17/2024
0
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
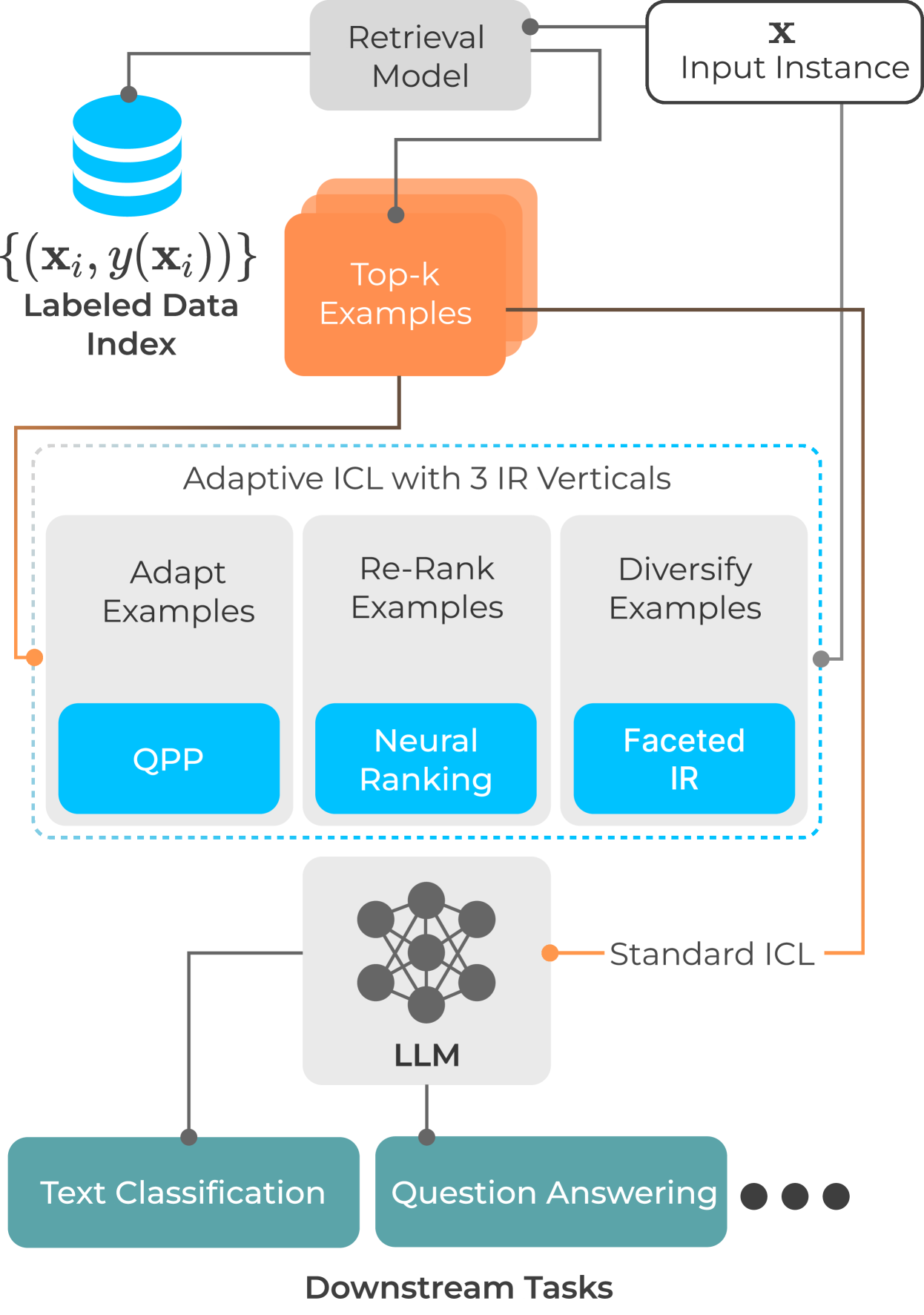
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
Read more5/3/2024