Contextual Bandits for Unbounded Context Distributions

0

Sign in to get full access
Overview
- This paper proposes a new approach to contextual bandits, a type of machine learning problem, that can handle unbounded context distributions.
- The key contributions are:
- A novel algorithm called ConBan that can handle unbounded context distributions.
- Theoretical guarantees on the performance of ConBan.
- Empirical evaluations showing that ConBan outperforms existing methods on real-world datasets.
Plain English Explanation
The paper is about a machine learning problem called contextual bandits. In this problem, an agent (like a recommendation system) needs to choose the best "action" (e.g. which product to recommend) for a given "context" (e.g. user profile). The agent learns from past experience to make better choices over time.
Existing contextual bandit methods assume the context distribution (the range of possible user profiles) is bounded, meaning it has a known maximum and minimum. However, in many real-world scenarios, the context distribution may be unbounded, with no clear limits.
The key contribution of this paper is a new algorithm called ConBan that can handle unbounded context distributions. ConBan works by adaptively adjusting how it explores new contexts versus exploiting what it has learned so far. The paper provides mathematical guarantees that ConBan will perform well, and shows through experiments that it outperforms existing methods on real-world datasets.
Technical Explanation
The paper introduces a contextual bandit problem where the context distribution is unbounded, meaning the range of possible contexts is not limited to a known finite set. This is a more realistic setting than previous work, which assumed bounded contexts.
The authors propose a new algorithm called ConBan that can handle unbounded contexts. ConBan works by maintaining a model of the context distribution and the reward function, and using an adaptive exploration-exploitation strategy to choose actions. Specifically, ConBan keeps track of a set of "active" contexts that it has observed so far, and focuses its exploration on regions of the context space that are close to this set. This allows it to gradually expand its knowledge of the full context distribution over time.
The paper provides theoretical guarantees on the performance of ConBan, showing that its regret (the difference between its cumulative rewards and the optimal strategy) scales logarithmically with the size of the context space, even when the context distribution is unbounded. This is a stronger result than for previous contextual bandit algorithms, which typically have linear or polynomial regret dependence on the context space size.
The authors also evaluate ConBan empirically on several real-world datasets, and show that it outperforms existing contextual bandit methods that assume bounded contexts. This demonstrates the practical benefits of the new algorithm in handling more realistic scenarios with unbounded context distributions.
Critical Analysis
The paper makes a valuable contribution by addressing the more realistic scenario of unbounded context distributions in contextual bandits. The ConBan algorithm and its theoretical analysis are technically sound, and the empirical evaluation helps validate the approach.
One potential limitation is that the paper assumes the context distribution has certain smoothness properties, such as Lipschitz continuity. While this is a reasonable assumption in many practical settings, it may not hold in all cases. It would be interesting to see if the approach can be extended to handle more general context distributions.
Additionally, the paper focuses on the cumulative regret performance of ConBan. While this is an important metric, it may not capture all the practical concerns in real-world applications. For example, the computational efficiency and memory usage of the algorithm could also be relevant considerations.
Overall, the paper represents a significant advance in the field of contextual bandits, and the ConBan algorithm provides a useful tool for handling unbounded context distributions. Further research could explore extensions and refinements to make the approach even more widely applicable.
Conclusion
This paper introduces a new contextual bandit algorithm called ConBan that can handle unbounded context distributions, which are more realistic than the bounded distributions assumed in previous work. ConBan uses an adaptive exploration-exploitation strategy to gradually expand its knowledge of the context space, and the paper provides strong theoretical guarantees on its performance.
The empirical evaluations demonstrate the practical benefits of ConBan over existing methods, showcasing its ability to perform well in real-world scenarios with unbounded contexts. This work represents an important step forward in the field of contextual bandits, and the insights and techniques developed here could inspire further advancements in this area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contextual Bandits for Unbounded Context Distributions
Puning Zhao, Jiafei Wu, Zhe Liu, Huiwen Wu
Nonparametric contextual bandit is an important model of sequential decision making problems. Under $alpha$-Tsybakov margin condition, existing research has established a regret bound of $tilde{O}left(T^{1-frac{alpha+1}{d+2}}right)$ for bounded supports. However, the optimal regret with unbounded contexts has not been analyzed. The challenge of solving contextual bandit problems with unbounded support is to achieve both exploration-exploitation tradeoff and bias-variance tradeoff simultaneously. In this paper, we solve the nonparametric contextual bandit problem with unbounded contexts. We propose two nearest neighbor methods combined with UCB exploration. The first method uses a fixed $k$. Our analysis shows that this method achieves minimax optimal regret under a weak margin condition and relatively light-tailed context distributions. The second method uses adaptive $k$. By a proper data-driven selection of $k$, this method achieves an expected regret of $tilde{O}left(T^{1-frac{(alpha+1)beta}{alpha+(d+2)beta}}+T^{1-beta}right)$, in which $beta$ is a parameter describing the tail strength. This bound matches the minimax lower bound up to logarithm factors, indicating that the second method is approximately optimal.
Read more8/20/2024
0
Batched Nonparametric Contextual Bandits
Rong Jiang, Cong Ma
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose a novel batch learning algorithm that achieves the optimal regret (up to logarithmic factors). In essence, our procedure dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. Our theoretical results suggest that for nonparametric contextual bandits, a nearly constant number of policy updates can attain optimal regret in the fully online setting.
Read more6/12/2024
↗️
0
Contextual Bandits with Packing and Covering Constraints: A Modular Lagrangian Approach via Regression
Aleksandrs Slivkins, Xingyu Zhou, Karthik Abinav Sankararaman, Dylan J. Foster
We consider contextual bandits with linear constraints (CBwLC), a variant of contextual bandits in which the algorithm consumes multiple resources subject to linear constraints on total consumption. This problem generalizes contextual bandits with knapsacks (CBwK), allowing for packing and covering constraints, as well as positive and negative resource consumption. We provide the first algorithm for CBwLC (or CBwK) that is based on regression oracles. The algorithm is simple, computationally efficient, and statistically optimal under mild assumptions. Further, we provide the first vanishing-regret guarantees for CBwLC (or CBwK) that extend beyond the stochastic environment. We side-step strong impossibility results from prior work by identifying a weaker (and, arguably, fairer) benchmark to compare against. Our algorithm builds on LagrangeBwK (Immorlica et al., FOCS 2019), a Lagrangian-based technique for CBwK, and SquareCB (Foster and Rakhlin, ICML 2020), a regression-based technique for contextual bandits. Our analysis leverages the inherent modularity of both techniques.
Read more7/2/2024
0
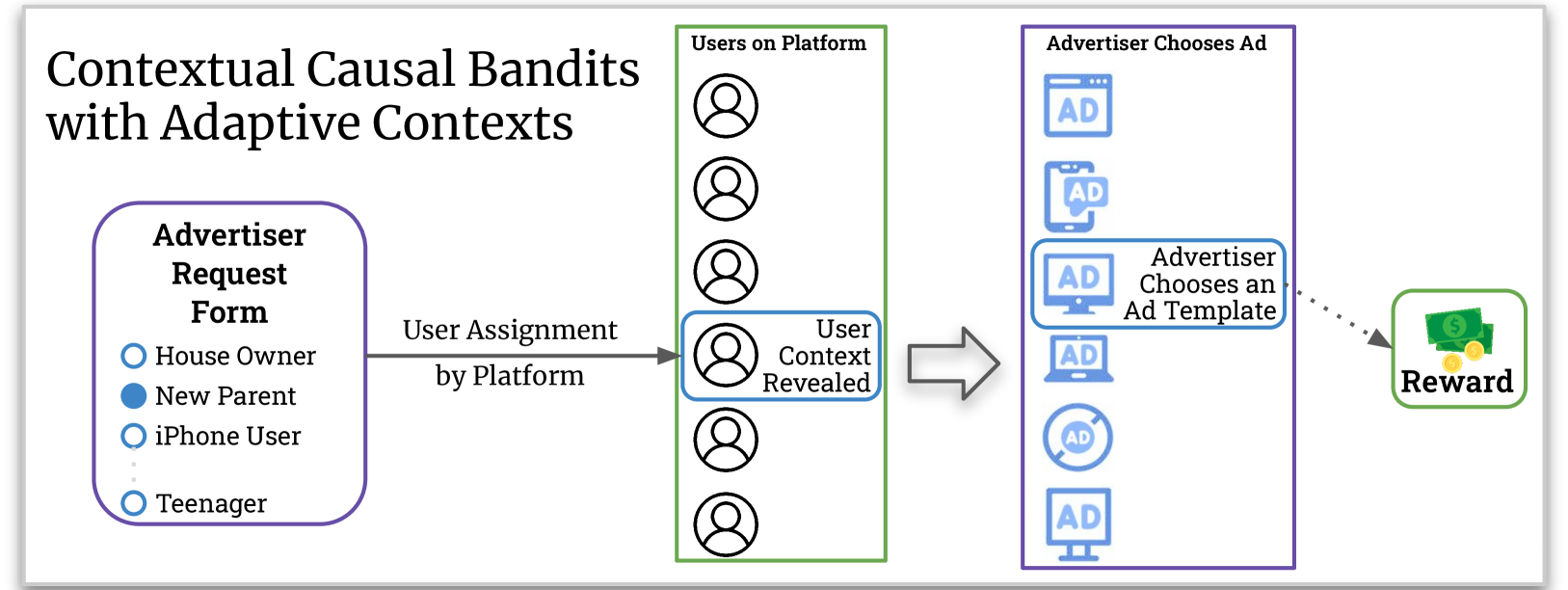
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024