Contextual Continuum Bandits: Static Versus Dynamic Regret

0
⚙️
Sign in to get full access
Overview
- This paper examines the differences between static regret and dynamic regret in the context of contextual continuum bandits.
- Static regret compares the algorithm's performance to the best fixed policy, while dynamic regret measures the algorithm's performance against the best time-varying policy.
- The paper provides theoretical and empirical analysis to understand the relationship between these two regret measures and their implications for algorithm design.
Plain English Explanation
In the world of machine learning and decision-making, there are different ways to measure how well an algorithm is performing. One common measure is called "regret," which essentially compares the algorithm's decisions to the best decisions that could have been made in hindsight.
<a href="https://aimodels.fyi/papers/arxiv/equivalence-between-static-dynamic-regret-minimization">Static regret</a> looks at how the algorithm performs compared to the single best fixed decision that could have been made throughout the entire time period. This is like saying, "If I had known the best decision from the beginning, how much better could I have done?"
<a href="https://aimodels.fyi/papers/arxiv/no-regret-is-not-enough-bandits-general">Dynamic regret</a>, on the other hand, looks at how the algorithm performs compared to the best time-varying decisions that could have been made. This is a more challenging standard, as the best decisions may change over time, and the algorithm has to adapt accordingly.
This paper explores the differences between these two regret measures in the context of a specific machine learning problem called "contextual continuum bandits." The authors provide both theoretical analysis and empirical experiments to understand the relationship between static and dynamic regret, and how this impacts the design of effective algorithms.
Technical Explanation
The paper focuses on the contextual continuum bandit problem, where an agent must choose an action from a continuous set of options at each time step, based on some contextual information about the current state of the environment. The agent's goal is to minimize their regret, which measures how much they could have improved their cumulative rewards by making better decisions.
The authors analyze two different regret measures: <a href="https://aimodels.fyi/papers/arxiv/equivalence-between-static-dynamic-regret-minimization">static regret</a> and <a href="https://aimodels.fyi/papers/arxiv/no-regret-is-not-enough-bandits-general">dynamic regret</a>. Static regret compares the agent's performance to the best fixed policy, while dynamic regret measures the agent's performance against the best time-varying policy.
Through theoretical analysis, the authors show that in the contextual continuum bandit setting, achieving vanishing static regret is equivalent to achieving vanishing dynamic regret, under certain assumptions. However, they also demonstrate that the algorithms required to achieve these two types of regret can be quite different.
The authors then propose a novel algorithm called <a href="https://aimodels.fyi/papers/arxiv/causal-contextual-bandits-adaptive-context">Causal Contextual Bandits with Adaptive Context</a> (CCBAC), which can achieve near-optimal dynamic regret in the contextual continuum bandit problem. They provide a theoretical analysis of the algorithm's performance and validate their findings through empirical experiments.
Critical Analysis
The paper provides a thorough analysis of the relationship between static and dynamic regret in the context of contextual continuum bandits. The theoretical results and the proposed CCBAC algorithm contribute to the understanding of regret minimization in this setting.
One potential limitation of the research is the reliance on certain assumptions, such as the Lipschitz continuity of the reward function and the boundedness of the context space. These assumptions may not always hold in practical applications, and it would be interesting to see how the results extend to more relaxed settings.
Additionally, the paper focuses on the contextual continuum bandit problem, which is a specific instance of the broader contextual bandit framework. It would be valuable to explore the generalization of these insights to other contextual bandit settings, such as <a href="https://aimodels.fyi/papers/arxiv/optimal-regret-locally-private-linear-contextual-bandit">linear contextual bandits</a> or <a href="https://aimodels.fyi/papers/arxiv/optimal-regret-limited-adaptivity-generalized-linear-contextual">generalized linear contextual bandits</a>.
Conclusion
This paper provides a detailed analysis of the relationship between static and dynamic regret in the context of contextual continuum bandits. The authors show that achieving vanishing static regret is equivalent to achieving vanishing dynamic regret under certain assumptions, but the algorithms required to achieve these two types of regret can be quite different.
The proposed CCBAC algorithm demonstrates the ability to achieve near-optimal dynamic regret in this setting, which has important implications for the design of effective decision-making systems. The insights from this research can contribute to the broader understanding of regret minimization in various contextual bandit problems and inspire further developments in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Contextual Continuum Bandits: Static Versus Dynamic Regret
Arya Akhavan, Karim Lounici, Massimiliano Pontil, Alexandre B. Tsybakov
We study the contextual continuum bandits problem, where the learner sequentially receives a side information vector and has to choose an action in a convex set, minimizing a function associated to the context. The goal is to minimize all the underlying functions for the received contexts, leading to a dynamic (contextual) notion of regret, which is stronger than the standard static regret. Assuming that the objective functions are Holder with respect to the contexts, we demonstrate that any algorithm achieving a sub-linear static regret can be extended to achieve a sub-linear dynamic regret. We further study the case of strongly convex and smooth functions when the observations are noisy. Inspired by the interior point method and employing self-concordant barriers, we propose an algorithm achieving a sub-linear dynamic regret. Lastly, we present a minimax lower bound, implying two key facts. First, no algorithm can achieve sub-linear dynamic regret over functions that are not continuous with respect to the context. Second, for strongly convex and smooth functions, the algorithm that we propose achieves, up to a logarithmic factor, the minimax optimal rate of dynamic regret as a function of the number of queries.
Read more6/21/2024
0
On the Optimal Regret of Locally Private Linear Contextual Bandit
Jiachun Li, David Simchi-Levi, Yining Wang
Contextual bandit with linear reward functions is among one of the most extensively studied models in bandit and online learning research. Recently, there has been increasing interest in designing emph{locally private} linear contextual bandit algorithms, where sensitive information contained in contexts and rewards is protected against leakage to the general public. While the classical linear contextual bandit algorithm admits cumulative regret upper bounds of $tilde O(sqrt{T})$ via multiple alternative methods, it has remained open whether such regret bounds are attainable in the presence of local privacy constraints, with the state-of-the-art result being $tilde O(T^{3/4})$. In this paper, we show that it is indeed possible to achieve an $tilde O(sqrt{T})$ regret upper bound for locally private linear contextual bandit. Our solution relies on several new algorithmic and analytical ideas, such as the analysis of mean absolute deviation errors and layered principal component regression in order to achieve small mean absolute deviation errors.
Read more4/16/2024
✨
0
An Equivalence Between Static and Dynamic Regret Minimization
Andrew Jacobsen, Francesco Orabona
We study the problem of dynamic regret minimization in online convex optimization, in which the objective is to minimize the difference between the cumulative loss of an algorithm and that of an arbitrary sequence of comparators. While the literature on this topic is very rich, a unifying framework for the analysis and design of these algorithms is still missing. In this paper, emph{we show that dynamic regret minimization is equivalent to static regret minimization in an extended decision space}. Using this simple observation, we show that there is a frontier of lower bounds trading off penalties due to the variance of the losses and penalties due to variability of the comparator sequence, and provide a framework for achieving any of the guarantees along this frontier. As a result, we prove for the first time that adapting to the squared path-length of an arbitrary sequence of comparators to achieve regret $R_{T}(u_{1},dots,u_{T})le O(sqrt{Tsum_{t} |u_{t}-u_{t+1}|^{2}})$ is impossible. However, we prove that it is possible to adapt to a new notion of variability based on the locally-smoothed squared path-length of the comparator sequence, and provide an algorithm guaranteeing dynamic regret of the form $R_{T}(u_{1},dots,u_{T})le tilde O(sqrt{Tsum_{i}|bar u_{i}-bar u_{i+1}|^{2}})$. Up to polylogarithmic terms, the new notion of variability is never worse than the classic one involving the path-length.
Read more6/4/2024
0
Batched Nonparametric Contextual Bandits
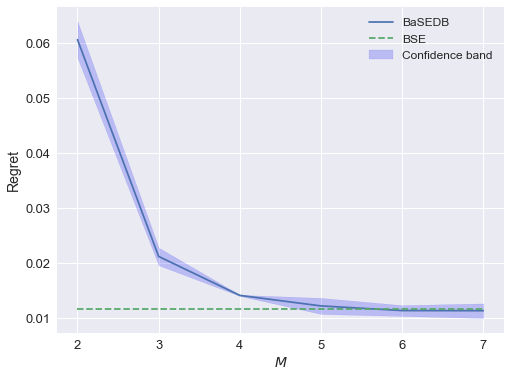
Rong Jiang, Cong Ma
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose a novel batch learning algorithm that achieves the optimal regret (up to logarithmic factors). In essence, our procedure dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. Our theoretical results suggest that for nonparametric contextual bandits, a nearly constant number of policy updates can attain optimal regret in the fully online setting.
Read more6/12/2024