On the Optimal Regret of Locally Private Linear Contextual Bandit
2404.09413
0
0
Abstract
Contextual bandit with linear reward functions is among one of the most extensively studied models in bandit and online learning research. Recently, there has been increasing interest in designing emph{locally private} linear contextual bandit algorithms, where sensitive information contained in contexts and rewards is protected against leakage to the general public. While the classical linear contextual bandit algorithm admits cumulative regret upper bounds of $tilde O(sqrt{T})$ via multiple alternative methods, it has remained open whether such regret bounds are attainable in the presence of local privacy constraints, with the state-of-the-art result being $tilde O(T^{3/4})$. In this paper, we show that it is indeed possible to achieve an $tilde O(sqrt{T})$ regret upper bound for locally private linear contextual bandit. Our solution relies on several new algorithmic and analytical ideas, such as the analysis of mean absolute deviation errors and layered principal component regression in order to achieve small mean absolute deviation errors.
Create account to get full access
Overview
- This paper introduces a new framework for regret-optimal online learning with limited adaptivity in the context of generalized linear models.
- The authors develop several new algorithms that achieve optimal regret bounds while requiring only a small number of model updates per round.
- The paper also includes connections to related work in areas like online continuous hyperparameter optimization and decentralized control.
Plain English Explanation
The paper presents a new approach to a problem in machine learning called "online learning." In online learning, an algorithm has to make a prediction about some data, then learns from the actual outcome before making the next prediction. The goal is to minimize "regret" - the difference between the algorithm's performance and the performance of the best possible predictor.
The authors focus on a specific type of online learning problem called "generalized linear contextual bandits." Here, the algorithm has to predict some outcome based on "context" information about the data. The key innovation is that the authors allow the algorithm to only update its internal model a limited number of times, rather than having to update it after every single prediction.
This limited updating is useful in practical applications where frequent model updates might be costly or infeasible. The authors develop several new algorithms that can achieve optimal regret bounds - meaning their performance is nearly as good as the best possible predictor - while only updating the model a small number of times. They also show connections to other related problems like hyperparameter optimization and decentralized control.
Technical Explanation
The paper studies a generalized linear contextual bandit problem, where the learner aims to minimize regret against the best fixed predictor in hindsight. The key innovation is that the learner is limited in the number of model updates it can perform per round - this models settings where frequent model updates are costly or infeasible.
The authors develop several new algorithms, including Optimal Regret with Limited Adaptivity (ORLA), that can achieve optimal regret bounds while only updating the model a small number of times per round. They also show connections to prior work on online continuous hyperparameter optimization and decentralized control.
Theoretically, the paper establishes nearly tight regret bounds for the proposed algorithms, matching or improving on prior state-of-the-art results. The experiments demonstrate the practical performance of the algorithms on simulated and real-world datasets.
Critical Analysis
The paper tackles an important and practically relevant problem setting in online learning. The limited adaptivity constraint is well-motivated, and the authors develop a strong set of new algorithms and theoretical results.
One potential limitation is that the analysis relies on certain assumptions about the data-generating process, such as bounded feature norms and sub-Gaussian noise. It would be interesting to see how the algorithms perform under more relaxed conditions.
Additionally, while the paper provides connections to related work, it would be helpful to have a more thorough discussion of the similarities and differences between the proposed approach and other relevant frameworks like Tsallis Inf-Generalized Best of Both Worlds and Doubly Optimal No-Regret Online Learning.
Overall, this is a strong technical contribution that pushes the state-of-the-art in online learning with limited adaptivity. The insights and algorithms developed in this paper could have far-reaching implications across a variety of applications.
Conclusion
This paper introduces a new framework for regret-optimal online learning with limited adaptivity in the context of generalized linear models. The authors develop several new algorithms that achieve optimal regret bounds while requiring only a small number of model updates per round.
The key innovation is the limited adaptivity constraint, which models practical scenarios where frequent model updates are costly or infeasible. The theoretical and empirical results demonstrate the effectiveness of the proposed approach, and the connections to related work in areas like hyperparameter optimization and decentralized control further highlight the broader significance of this research.
Overall, this paper represents an important advancement in the field of online learning, with the potential to enable more efficient and practical deployment of machine learning systems in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
Optimal Regret with Limited Adaptivity for Generalized Linear Contextual Bandits
Ayush Sawarni, Nirjhar Das, Siddharth Barman, Gaurav Sinha
0
0
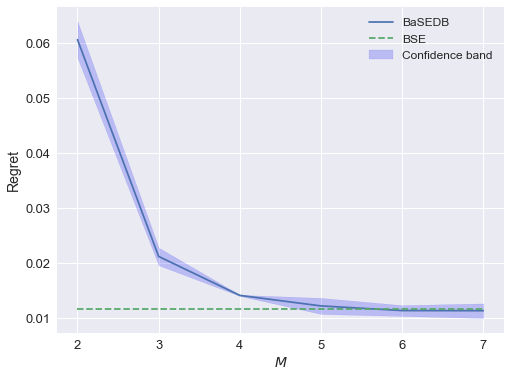
We study the generalized linear contextual bandit problem within the constraints of limited adaptivity. In this paper, we present two algorithms, $texttt{B-GLinCB}$ and $texttt{RS-GLinCB}$, that address, respectively, two prevalent limited adaptivity settings. Given a budget $M$ on the number of policy updates, in the first setting, the algorithm needs to decide upfront $M$ rounds at which it will update its policy, while in the second setting it can adaptively perform $M$ policy updates during its course. For the first setting, we design an algorithm $texttt{B-GLinCB}$, that incurs $tilde{O}(sqrt{T})$ regret when $M = Omegaleft( log{log T} right)$ and the arm feature vectors are generated stochastically. For the second setting, we design an algorithm $texttt{RS-GLinCB}$ that updates its policy $tilde{O}(log^2 T)$ times and achieves a regret of $tilde{O}(sqrt{T})$ even when the arm feature vectors are adversarially generated. Notably, in these bounds, we manage to eliminate the dependence on a key instance dependent parameter $kappa$, that captures non-linearity of the underlying reward model. Our novel approach for removing this dependence for generalized linear contextual bandits might be of independent interest.
6/17/2024
⚙️
Contextual Continuum Bandits: Static Versus Dynamic Regret
Arya Akhavan, Karim Lounici, Massimiliano Pontil, Alexandre B. Tsybakov
0
0
We study the contextual continuum bandits problem, where the learner sequentially receives a side information vector and has to choose an action in a convex set, minimizing a function associated to the context. The goal is to minimize all the underlying functions for the received contexts, leading to a dynamic (contextual) notion of regret, which is stronger than the standard static regret. Assuming that the objective functions are Holder with respect to the contexts, we demonstrate that any algorithm achieving a sub-linear static regret can be extended to achieve a sub-linear dynamic regret. We further study the case of strongly convex and smooth functions when the observations are noisy. Inspired by the interior point method and employing self-concordant barriers, we propose an algorithm achieving a sub-linear dynamic regret. Lastly, we present a minimax lower bound, implying two key facts. First, no algorithm can achieve sub-linear dynamic regret over functions that are not continuous with respect to the context. Second, for strongly convex and smooth functions, the algorithm that we propose achieves, up to a logarithmic factor, the minimax optimal rate of dynamic regret as a function of the number of queries.
6/21/2024
Batched Nonparametric Contextual Bandits
Rong Jiang, Cong Ma
0
0
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose a novel batch learning algorithm that achieves the optimal regret (up to logarithmic factors). In essence, our procedure dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. Our theoretical results suggest that for nonparametric contextual bandits, a nearly constant number of policy updates can attain optimal regret in the fully online setting.
6/12/2024
🛸
Improved Bound for Robust Causal Bandits with Linear Models
Zirui Yan, Arpan Mukherjee, Burak Var{i}c{i}, Ali Tajer
0
0
This paper investigates the robustness of causal bandits (CBs) in the face of temporal model fluctuations. This setting deviates from the existing literature's widely-adopted assumption of constant causal models. The focus is on causal systems with linear structural equation models (SEMs). The SEMs and the time-varying pre- and post-interventional statistical models are all unknown and subject to variations over time. The goal is to design a sequence of interventions that incur the smallest cumulative regret compared to an oracle aware of the entire causal model and its fluctuations. A robust CB algorithm is proposed, and its cumulative regret is analyzed by establishing both upper and lower bounds on the regret. It is shown that in a graph with maximum in-degree $d$, length of the largest causal path $L$, and an aggregate model deviation $C$, the regret is upper bounded by $tilde{mathcal{O}}(d^{L-frac{1}{2}}(sqrt{T} + C))$ and lower bounded by $Omega(d^{frac{L}{2}-2}max{sqrt{T}; ,; d^2C})$. The proposed algorithm achieves nearly optimal $tilde{mathcal{O}}(sqrt{T})$ regret when $C$ is $o(sqrt{T})$, maintaining sub-linear regret for a broad range of $C$.
5/14/2024