Contrastive Mean-Shift Learning for Generalized Category Discovery

0

Sign in to get full access
Overview
- This paper introduces a new approach called Contrastive Mean-Shift Learning (CMSL) for Generalized Category Discovery (GCD).
- GCD is the task of identifying new, previously unknown categories of objects in an unsupervised manner, going beyond just recognizing known categories.
- The CMSL method leverages contrastive learning to discover new categories by learning a feature representation that can effectively cluster both known and unknown categories.
Plain English Explanation
The paper presents a new technique called Contrastive Mean-Shift Learning (CMSL) for a problem known as Generalized Category Discovery (GCD). GCD is about automatically finding new types of objects in a dataset, beyond just recognizing the types that were already known.
The key idea behind CMSL is to use a technique called contrastive learning to learn a good way of representing the data. This representation should be able to effectively group together both the known types of objects as well as any new, previously unseen types. By learning this robust representation, the method can then discover the new categories in an unsupervised way.
The paper demonstrates that CMSL is an effective approach for this GCD task, outperforming previous methods. The new technique provides a way to go beyond just recognizing a fixed set of known categories, and can uncover new and interesting categories that may be present in the data.
Technical Explanation
The paper introduces a new method called Contrastive Mean-Shift Learning (CMSL) for the task of Generalized Category Discovery (GCD). GCD aims to identify new, previously unknown categories of objects in an unsupervised manner, going beyond simply recognizing a fixed set of known categories.
The core idea behind CMSL is to leverage contrastive learning to learn a feature representation that can effectively cluster both known and unknown categories. Specifically, the method uses a contrastive loss to push together samples from the same category, while pushing apart samples from different categories. This encourages the learned representation to capture the underlying structure of the data, including both the known categories and any new, previously unseen categories.
The paper demonstrates the effectiveness of CMSL through extensive experiments on several real-world datasets. The results show that CMSL outperforms previous state-of-the-art methods for GCD, highlighting its ability to discover new categories while maintaining strong performance on known categories.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CMSL method. The authors carefully compare against strong baselines and ablate key components of their approach to understand its contributions.
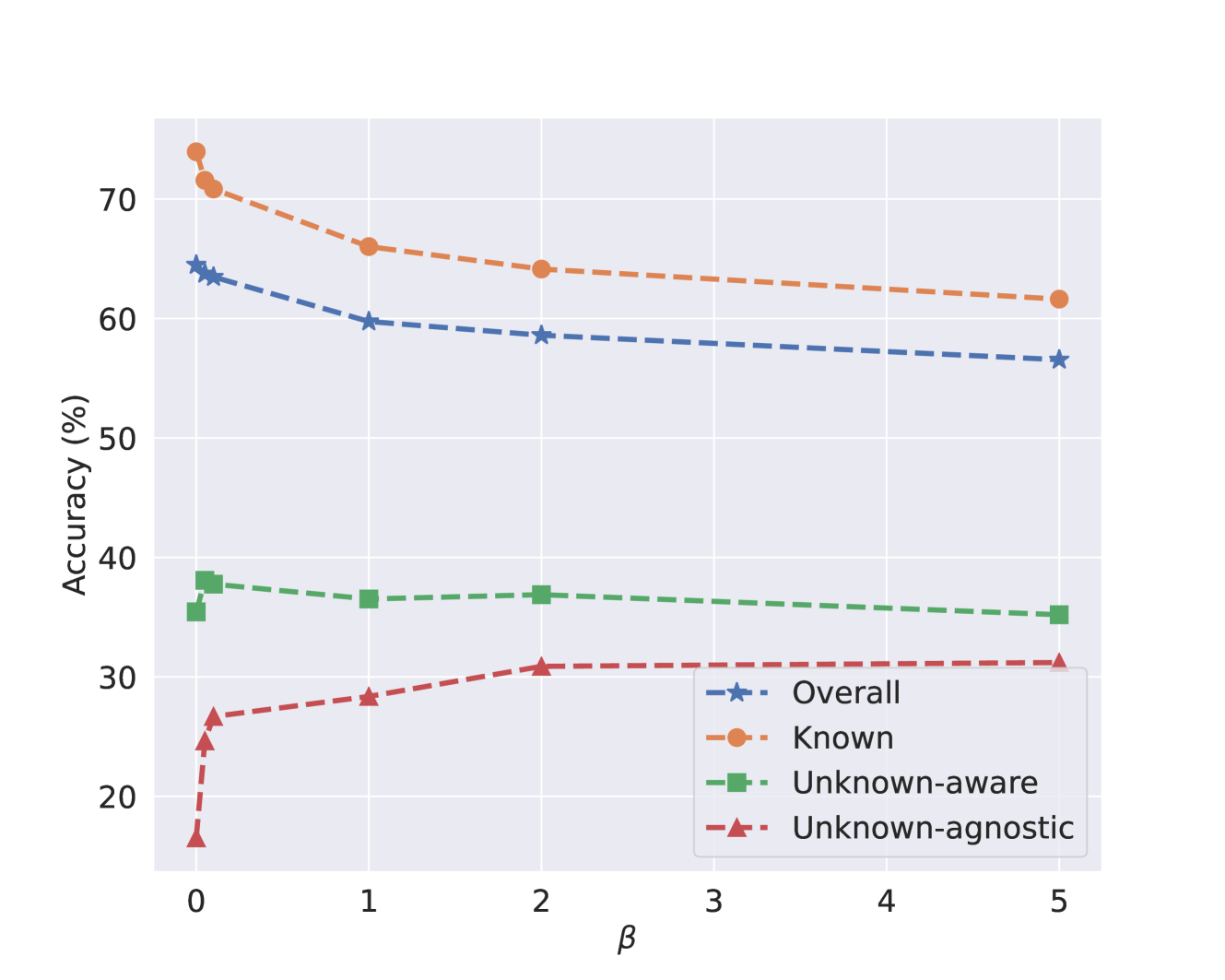
One potential limitation is that the experiments are conducted on relatively small-scale datasets. It would be valuable to see how CMSL scales to larger, more complex data distributions. Additionally, the paper does not provide much insight into the types of new categories that CMSL is able to discover. Further analysis of the discovered categories and their properties could yield additional interesting insights.
Another area for potential improvement is the interpretability of the learned representations. While the contrastive learning approach leads to strong performance, the resulting representations may be difficult to interpret. Techniques to enhance the interpretability of the discovered categories, perhaps through visual explanations or taxonomic structures, could make the method more accessible and impactful.
Overall, the CMSL method represents an important advance in the field of Generalized Category Discovery and the paper makes a valuable contribution. The authors have demonstrated the effectiveness of their approach and provided a solid foundation for future work in this area.
Conclusion
This paper introduces a novel Contrastive Mean-Shift Learning (CMSL) approach for the task of Generalized Category Discovery (GCD). GCD aims to go beyond just recognizing a fixed set of known categories, and instead discover new, previously unknown categories in an unsupervised manner.
The key innovation of CMSL is the use of contrastive learning to learn a robust feature representation that can effectively cluster both known and unknown categories. This allows the method to uncover new and interesting categories that may be present in the data, while maintaining strong performance on the known categories.
The paper demonstrates the effectiveness of CMSL through extensive experiments, showing that it outperforms previous state-of-the-art methods for GCD. This work represents an important advancement in the field and lays the groundwork for further research into more powerful and interpretable techniques for discovering new categories in complex data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contrastive Mean-Shift Learning for Generalized Category Discovery
Sua Choi, Dahyun Kang, Minsu Cho
We address the problem of generalized category discovery (GCD) that aims to partition a partially labeled collection of images; only a small part of the collection is labeled and the total number of target classes is unknown. To address this generalized image clustering problem, we revisit the mean-shift algorithm, i.e., a classic, powerful technique for mode seeking, and incorporate it into a contrastive learning framework. The proposed method, dubbed Contrastive Mean-Shift (CMS) learning, trains an image encoder to produce representations with better clustering properties by an iterative process of mean shift and contrastive update. Experiments demonstrate that our method, both in settings with and without the total number of clusters being known, achieves state-of-the-art performance on six public GCD benchmarks without bells and whistles.
Read more4/16/2024
0
Generalized Categories Discovery for Long-tailed Recognition
Ziyun Li, Christoph Meinel, Haojin Yang
Generalized Class Discovery (GCD) plays a pivotal role in discerning both known and unknown categories from unlabeled datasets by harnessing the insights derived from a labeled set comprising recognized classes. A significant limitation in prevailing GCD methods is their presumption of an equitably distributed category occurrence in unlabeled data. Contrary to this assumption, visual classes in natural environments typically exhibit a long-tailed distribution, with known or prevalent categories surfacing more frequently than their rarer counterparts. Our research endeavors to bridge this disconnect by focusing on the long-tailed Generalized Category Discovery (Long-tailed GCD) paradigm, which echoes the innate imbalances of real-world unlabeled datasets. In response to the unique challenges posed by Long-tailed GCD, we present a robust methodology anchored in two strategic regularizations: (i) a reweighting mechanism that bolsters the prominence of less-represented, tail-end categories, and (ii) a class prior constraint that aligns with the anticipated class distribution. Comprehensive experiments reveal that our proposed method surpasses previous state-of-the-art GCD methods by achieving an improvement of approximately 6 - 9% on ImageNet100 and competitive performance on CIFAR100.
Read more8/27/2024
0
Contextuality Helps Representation Learning for Generalized Category Discovery
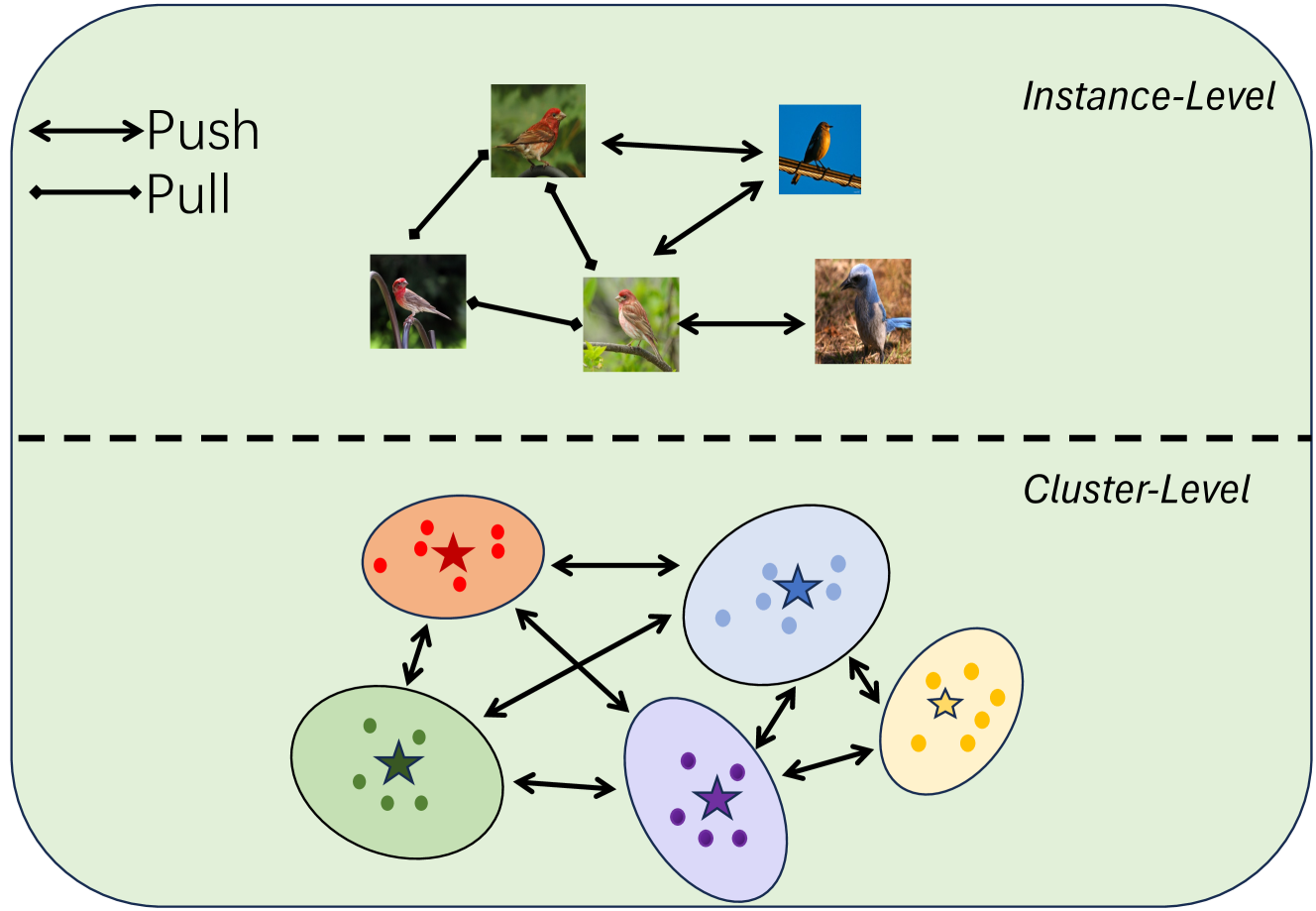
Tingzhang Luo, Mingxuan Du, Jiatao Shi, Xinxiang Chen, Bingchen Zhao, Shaoguang Huang
This paper introduces a novel approach to Generalized Category Discovery (GCD) by leveraging the concept of contextuality to enhance the identification and classification of categories in unlabeled datasets. Drawing inspiration from human cognition's ability to recognize objects within their context, we propose a dual-context based method. Our model integrates two levels of contextuality: instance-level, where nearest-neighbor contexts are utilized for contrastive learning, and cluster-level, employing prototypical contrastive learning based on category prototypes. The integration of the contextual information effectively improves the feature learning and thereby the classification accuracy of all categories, which better deals with the real-world datasets. Different from the traditional semi-supervised and novel category discovery techniques, our model focuses on a more realistic and challenging scenario where both known and novel categories are present in the unlabeled data. Extensive experimental results on several benchmark data sets demonstrate that the proposed model outperforms the state-of-the-art. Code is available at: https://github.com/Clarence-CV/Contexuality-GCD
Read more7/30/2024
🏷️
0
Category Adaptation Meets Projected Distillation in Generalized Continual Category Discovery
Grzegorz Rype's'c, Daniel Marczak, Sebastian Cygert, Tomasz Trzci'nski, Bart{l}omiej Twardowski
Generalized Continual Category Discovery (GCCD) tackles learning from sequentially arriving, partially labeled datasets while uncovering new categories. Traditional methods depend on feature distillation to prevent forgetting the old knowledge. However, this strategy restricts the model's ability to adapt and effectively distinguish new categories. To address this, we introduce a novel technique integrating a learnable projector with feature distillation, thus enhancing model adaptability without sacrificing past knowledge. The resulting distribution shift of the previously learned categories is mitigated with the auxiliary category adaptation network. We demonstrate that while each component offers modest benefits individually, their combination - dubbed CAMP (Category Adaptation Meets Projected distillation) - significantly improves the balance between learning new information and retaining old. CAMP exhibits superior performance across several GCCD and Class Incremental Learning scenarios. The code is available at https://github.com/grypesc/CAMP.
Read more7/26/2024