Contextualized Diffusion Models for Text-Guided Image and Video Generation
2402.16627
0
0

Abstract
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
Create account to get full access
Overview
- This paper presents a novel approach to text-guided visual generation and editing using cross-modal contextualized diffusion models.
- The proposed models leverage language models to provide rich contextual information, which is then used to guide the diffusion process for generating and editing images.
- The authors demonstrate the effectiveness of their approach on various tasks, including text-to-image generation, image-to-image translation, and text-guided image editing.
Plain English Explanation
The researchers in this paper have developed a new way to create and edit images using text as a guide. They have built a system that combines language models (which are good at understanding and generating text) with diffusion models (which are good at generating and manipulating images).
The key idea is to use the language model to provide rich contextual information that can then be used to guide the diffusion model during the image generation or editing process. This allows the system to generate images that are closely tied to the given text prompts, or to edit existing images in ways that are consistent with the text instructions.
For example, the system could generate an image of a "a happy dog playing in a field of flowers," where the language model provides information about the scene and the emotional state of the dog, and the diffusion model uses this to create the final image. Or the system could take an existing image and edit it to "make the dog look more playful and the flowers more vibrant," based on the text instructions.
By combining the strengths of language models and diffusion models, the researchers have created a powerful tool for text-guided visual generation and editing. This could have applications in areas like digital art creation, photo editing, and design, where being able to easily translate text ideas into visual outputs could be very useful.
Technical Explanation
The key technical innovation in this paper is the development of cross-modal contextualized diffusion models. The authors start with a standard diffusion model for image generation, but they augment it with a language model that provides rich contextual information.
Specifically, the language model is used to generate a "context vector" that encodes the semantic and syntactic features of the text prompt. This context vector is then incorporated into the diffusion model at various stages of the generation process, allowing the model to condition the image synthesis on the provided text.
The authors experiment with different ways of integrating the language model, including concatenating the context vector with the image features, and using it to modulate the diffusion process. They also explore the use of cross-attention mechanisms to further strengthen the coupling between the text and image representations.
Through extensive experiments on a range of text-guided visual tasks, the authors demonstrate the effectiveness of their cross-modal contextualized diffusion models. They show significant improvements over previous approaches, both in terms of the quality of the generated images and their alignment with the given text prompts.
Critical Analysis
One limitation of the proposed approach is that it still relies on the availability of high-quality text-image paired data for training the models. While the authors attempt to mitigate this by using data augmentation techniques, there may be room for further research into more sample-efficient training methods that can work with smaller datasets.
Additionally, the authors do not provide a detailed analysis of the failure modes of their system, or the types of text prompts that it may struggle with. It would be valuable to understand the limitations and potential biases of the models, and to explore strategies for improving their robustness and generalization.
That said, the core idea of leveraging language models to guide the diffusion process is a promising direction for text-guided visual generation and editing. By combining the strengths of different AI models, the authors have demonstrated the potential for powerful and flexible visual synthesis capabilities.
Conclusion
The cross-modal contextualized diffusion models presented in this paper represent a significant advancement in the field of text-guided visual generation and editing. By integrating language models with diffusion-based image synthesis, the authors have created a versatile system that can generate high-quality images aligned with text prompts, as well as edit existing images in semantically meaningful ways.
This work has important implications for a wide range of applications, from digital art and design to augmented reality and computer-assisted creativity. As the field of AI-powered visual synthesis continues to evolve, approaches like the one presented in this paper will likely play an increasingly important role in bridging the gap between human language and visual expression.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
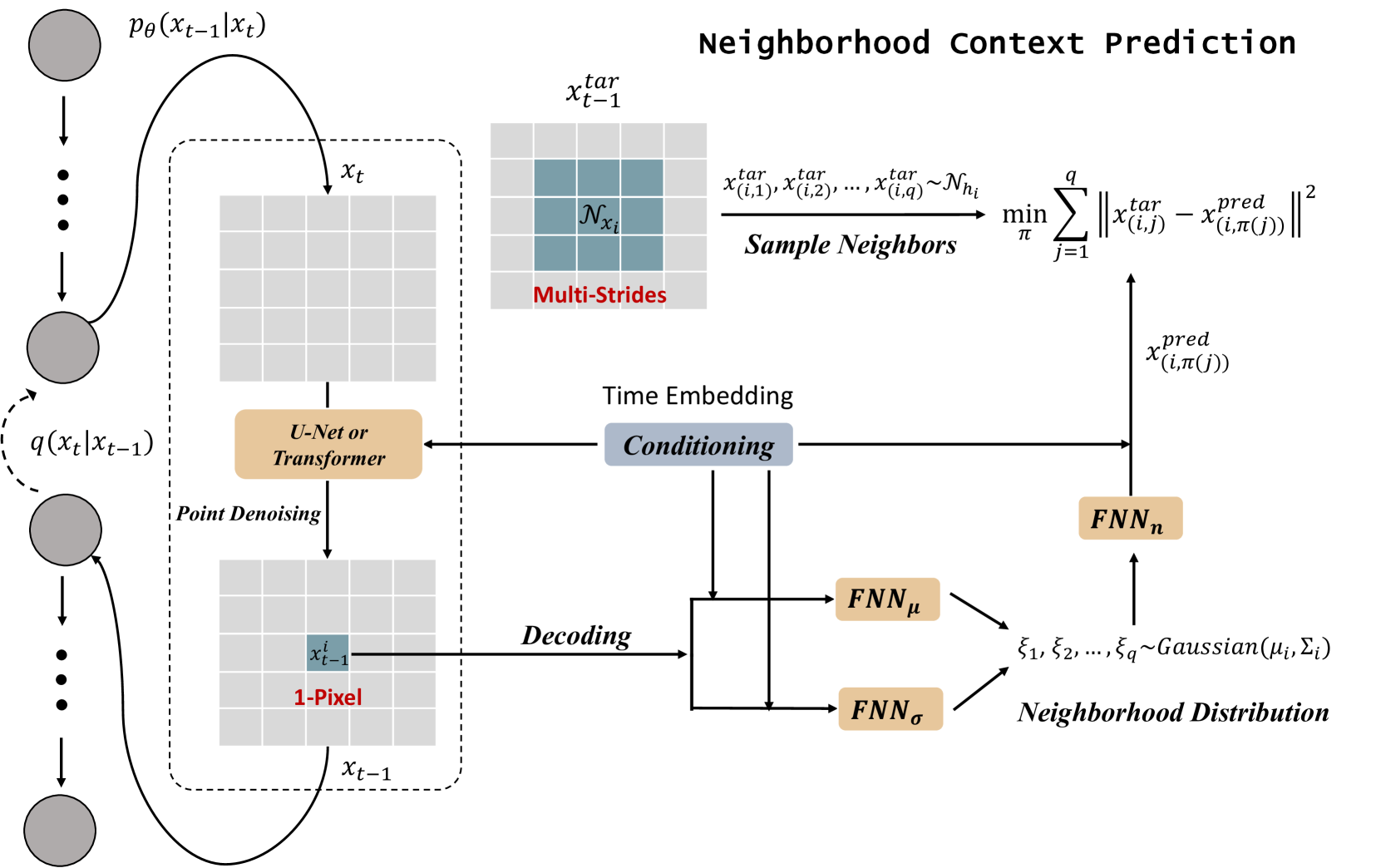
Improving Diffusion-Based Image Synthesis with Context Prediction
Ling Yang, Jingwei Liu, Shenda Hong, Zhilong Zhang, Zhilin Huang, Zheming Cai, Wentao Zhang, Bin Cui
0
0
Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
6/5/2024
🤖
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
0
0
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
5/7/2024

AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
0
0
Text-guided video prediction (TVP) involves predicting the motion of future frames from the initial frame according to an instruction, which has wide applications in virtual reality, robotics, and content creation. Previous TVP methods make significant breakthroughs by adapting Stable Diffusion for this task. However, they struggle with frame consistency and temporal stability primarily due to the limited scale of video datasets. We observe that pretrained Image2Video diffusion models possess good priors for video dynamics but they lack textual control. Hence, transferring Image2Video models to leverage their video dynamic priors while injecting instruction control to generate controllable videos is both a meaningful and challenging task. To achieve this, we introduce the Multi-Modal Large Language Model (MLLM) to predict future video states based on initial frames and text instructions. More specifically, we design a dual query transformer (DQFormer) architecture, which integrates the instructions and frames into the conditional embeddings for future frame prediction. Additionally, we develop Long-Short Term Temporal Adapters and Spatial Adapters that can quickly transfer general video diffusion models to specific scenarios with minimal training costs. Experimental results show that our method significantly outperforms state-of-the-art techniques on four datasets: Something Something V2, Epic Kitchen-100, Bridge Data, and UCF-101. Notably, AID achieves 91.2% and 55.5% FVD improvements on Bridge and SSv2 respectively, demonstrating its effectiveness in various domains. More examples can be found at our website https://chenhsing.github.io/AID.
6/11/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024