Improving Diffusion-Based Image Synthesis with Context Prediction
2401.02015
0
0
Abstract
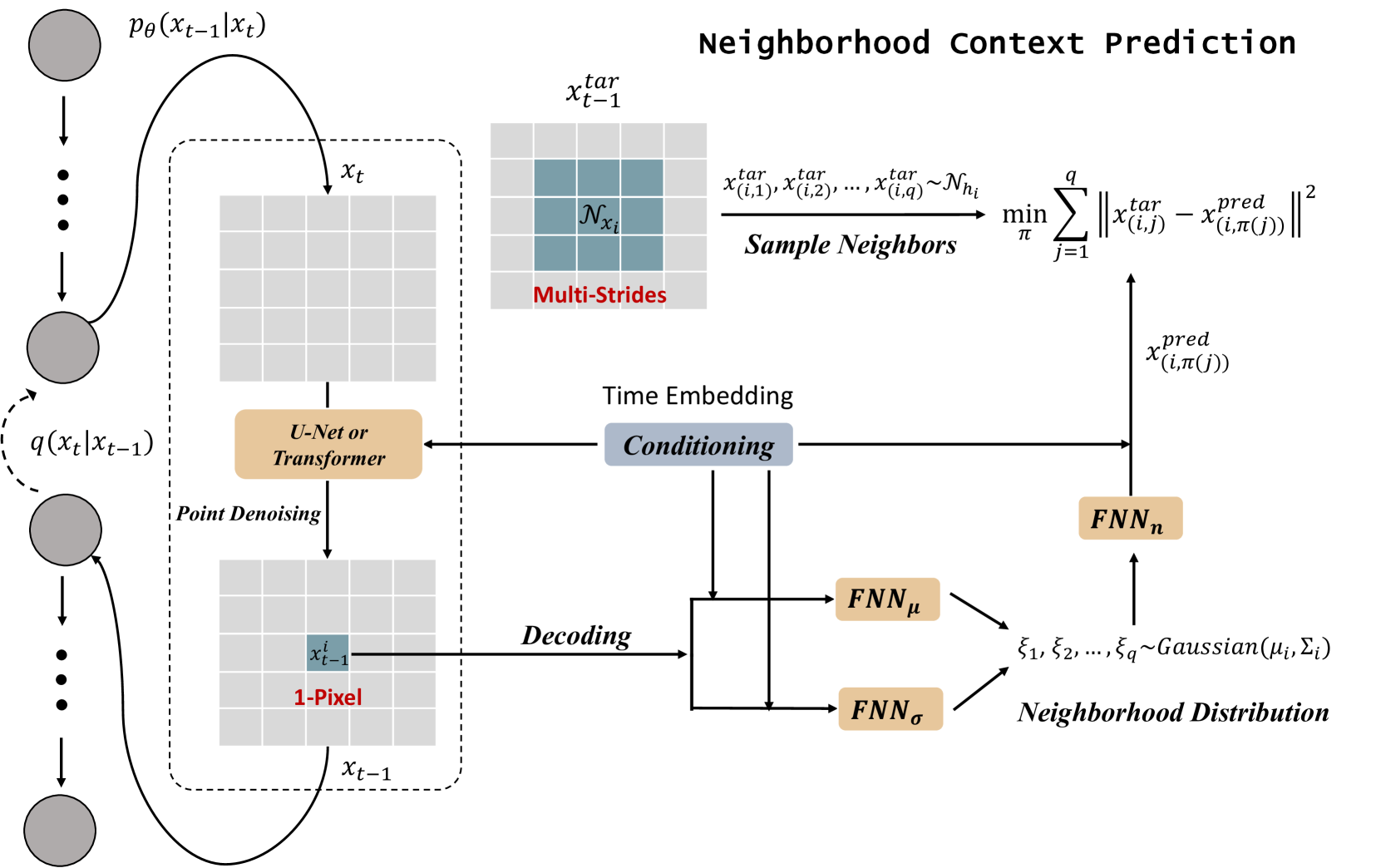
Diffusion models are a new class of generative models, and have dramatically promoted image generation with unprecedented quality and diversity. Existing diffusion models mainly try to reconstruct input image from a corrupted one with a pixel-wise or feature-wise constraint along spatial axes. However, such point-based reconstruction may fail to make each predicted pixel/feature fully preserve its neighborhood context, impairing diffusion-based image synthesis. As a powerful source of automatic supervisory signal, context has been well studied for learning representations. Inspired by this, we for the first time propose ConPreDiff to improve diffusion-based image synthesis with context prediction. We explicitly reinforce each point to predict its neighborhood context (i.e., multi-stride features/tokens/pixels) with a context decoder at the end of diffusion denoising blocks in training stage, and remove the decoder for inference. In this way, each point can better reconstruct itself by preserving its semantic connections with neighborhood context. This new paradigm of ConPreDiff can generalize to arbitrary discrete and continuous diffusion backbones without introducing extra parameters in sampling procedure. Extensive experiments are conducted on unconditional image generation, text-to-image generation and image inpainting tasks. Our ConPreDiff consistently outperforms previous methods and achieves a new SOTA text-to-image generation results on MS-COCO, with a zero-shot FID score of 6.21.
Create account to get full access
Overview
- This paper proposes a novel approach to improving the performance of diffusion-based image synthesis models by incorporating context prediction.
- Diffusion models are a powerful class of generative models that have shown impressive results in image generation, but they can struggle with capturing important contextual information.
- The authors introduce a context prediction module that allows the model to better understand the relationships between different elements in the image, leading to more coherent and realistic outputs.
Plain English Explanation
Diffusion models are a type of AI system that can generate new images from scratch. They work by gradually adding "noise" to an image and then learning how to reverse that process to create new images. However, these models can sometimes struggle to capture the overall context and relationships between different parts of an image.
The researchers in this paper came up with a way to help diffusion models better understand the context of an image. They added a special "context prediction" module that allows the model to learn about how different elements in the image are connected and related to each other. This helps the model generate images that look more cohesive and realistic, as it can better understand the bigger picture.
For example, if the model is generating an image of a living room, the context prediction module would help it understand that a couch should be near a coffee table, and a TV should be on the wall. This contextual understanding leads to more natural and coherent images.
The authors tested their approach on several different image generation tasks and found that it consistently outperformed standard diffusion models, particularly for complex scenes with multiple interacting elements. This suggests that incorporating context prediction is a promising direction for improving the performance of diffusion-based image synthesis.
Technical Explanation
The key innovation in this paper is the introduction of a context prediction module that is integrated into the diffusion model architecture. This module is designed to capture the relationships between different elements in the image, allowing the model to generate more coherent and realistic outputs.
The context prediction module works by predicting the "context" or surrounding information for each pixel in the image during the diffusion process. This is done by training a separate neural network to take in the partially noised image and predict the expected values for the surrounding pixels. This contextual information is then fed back into the main diffusion model, guiding the generation process towards more realistic and coherent results.
The authors evaluate their approach on several image generation benchmarks, including high-fidelity person-centric subject-to-image synthesis and enhancing image layout control. They find that the context prediction module consistently improves performance compared to standard diffusion models, particularly for complex scenes with multiple interacting elements.
Critical Analysis
One potential limitation of this approach is that the context prediction module adds additional complexity to the model, which could make it more challenging to train and deploy in real-world applications. The authors acknowledge this tradeoff and suggest that future work could explore ways to make the context prediction module more efficient or integrated more seamlessly into the diffusion model architecture.
Additionally, the paper does not extensively explore the limitations of the context prediction approach or provide a detailed analysis of failure cases. It would be valuable to understand the types of images or scenarios where the context prediction module struggles, as this could inform future improvements or alternative approaches.
Another area for further research could be exploring how the context prediction module might interact with other techniques for improving diffusion-based image synthesis, such as diffusion features to bridge domain gap or mixed diffusion for 3D indoor scene synthesis. Combining these complementary approaches could lead to even more powerful and versatile image generation models.
Conclusion
This paper presents a novel approach to improving diffusion-based image synthesis by incorporating a context prediction module. The authors demonstrate that this technique can lead to more coherent and realistic image generation, particularly for complex scenes with multiple interacting elements.
While the additional complexity of the context prediction module may be a limitation, the promising results suggest that this is a valuable direction for further research and development in the field of generative modeling. As diffusion models continue to advance, integrating contextual understanding will likely be a key component of building more powerful and versatile image synthesis systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Yuxiang Ji, Boyong He, Chenyuan Qu, Zhuoyue Tan, Chuan Qin, Liaoni Wu
0
0
Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84%$ mIoU across various datasets. The implementation code will be released soon.
6/4/2024

Contextualized Diffusion Models for Text-Guided Image and Video Generation
Ling Yang, Zhilong Zhang, Zhaochen Yu, Jingwei Liu, Minkai Xu, Stefano Ermon, Bin Cui
0
0
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
6/5/2024
🖼️
New!Exploiting Diffusion Prior for Real-World Image Super-Resolution
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C. K. Chan, Chen Change Loy
0
0
We present a novel approach to leverage prior knowledge encapsulated in pre-trained text-to-image diffusion models for blind super-resolution (SR). Specifically, by employing our time-aware encoder, we can achieve promising restoration results without altering the pre-trained synthesis model, thereby preserving the generative prior and minimizing training cost. To remedy the loss of fidelity caused by the inherent stochasticity of diffusion models, we employ a controllable feature wrapping module that allows users to balance quality and fidelity by simply adjusting a scalar value during the inference process. Moreover, we develop a progressive aggregation sampling strategy to overcome the fixed-size constraints of pre-trained diffusion models, enabling adaptation to resolutions of any size. A comprehensive evaluation of our method using both synthetic and real-world benchmarks demonstrates its superiority over current state-of-the-art approaches. Code and models are available at https://github.com/IceClear/StableSR.
7/1/2024

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024