Continual Distillation Learning

0

Sign in to get full access
Overview
- The paper discusses Continual Distillation Learning (CDL), a novel technique for enabling neural networks to continuously learn from new tasks while retaining knowledge from previous ones.
- CDL combines knowledge distillation and continual learning to allow a student model to learn from a sequence of teacher models, each trained on a different task.
- This approach aims to overcome the catastrophic forgetting problem common in neural networks, where learning new tasks causes the model to forget previous knowledge.
Plain English Explanation
The research paper presents Continual Distillation Learning (CDL),a method that helps neural networks continuously learn new skills without forgetting what they've learned before. Typical neural networks often struggle with "catastrophic forgetting" - when they learn a new task, they tend to forget how to do the old tasks.
CDL combines two key ideas to address this problem:
- Knowledge Distillation: The neural network learns by distilling knowledge from a sequence of "teacher" models, each trained on a different task.
- Continual Learning: The network is able to continuously learn new tasks while retaining old knowledge, avoiding catastrophic forgetting.
By using this approach, the neural network can continuously expand its capabilities by learning from a series of specialized teacher models, while still preserving its previous knowledge. This allows the network to gradually become more versatile and capable over time, without forgetting important skills.
Technical Explanation
The paper introduces Continual Distillation Learning (CDL), a technique that enables neural networks to continuously learn from a sequence of tasks while retaining knowledge from previous ones. CDL combines the concepts of knowledge distillation and continual learning.
In CDL, the student model learns by distilling knowledge from a sequence of teacher models, each trained on a different task. This allows the student to gradually expand its capabilities by learning from the specialized expertise of the teachers, while the continual learning aspect ensures the student retains previously acquired knowledge.
The key innovation is the use of a
The authors demonstrate the effectiveness of CDL through experiments on benchmark continual learning datasets, showing that it outperforms other state-of-the-art continual learning methods in terms of overall performance and stability.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of catastrophic forgetting in neural networks. By combining knowledge distillation and continual learning, CDL offers a promising solution for enabling neural networks to continuously expand their capabilities while preserving previously acquired knowledge.
One potential limitation of the approach is the reliance on a sequence of specialized teacher models. In real-world scenarios, it may not always be feasible to have access to a series of well-trained teachers for each new task. The authors acknowledge this and suggest exploring techniques to generate or reuse teacher models more efficiently.
Additionally, the paper does not address the potential computational and memory overhead of maintaining the outputs of all previous teacher models during training. As the number of tasks grows, this could become a significant challenge, and the authors may need to explore more memory-efficient strategies.
Finally, while the experimental results are promising, it would be valuable to see the technique evaluated on a broader range of tasks and datasets to better understand its generalization capabilities and limitations.
Conclusion
The Continual Distillation Learning (CDL) approach presented in this paper offers a novel solution to the persistent problem of catastrophic forgetting in neural networks. By leveraging knowledge distillation and continual learning, CDL enables neural models to continuously expand their capabilities while preserving previously acquired knowledge.
The authors' experimental results suggest that CDL outperforms other state-of-the-art continual learning methods, making it a promising technique for developing more versatile and adaptable neural systems. As the field of AI continues to advance, approaches like CDL that can enable continuous learning will become increasingly important for creating intelligent agents that can robustly and flexibly handle a wide range of tasks and environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Distillation Learning
Qifan Zhang, Yunhui Guo, Yu Xiang
We study the problem of Continual Distillation Learning (CDL) that considers Knowledge Distillation (KD) in the Continual Learning (CL) setup. A teacher model and a student model need to learn a sequence of tasks, and the knowledge of the teacher model will be distilled to the student to improve the student model. We introduce a novel method named CDL-Prompt that utilizes prompt-based continual learning models to build the teacher-student model. We investigate how to utilize the prompts of the teacher model in the student model for knowledge distillation, and propose an attention-based prompt mapping scheme to use the teacher prompts for the student. We demonstrate that our method can be applied to different prompt-based continual learning models such as L2P, DualPrompt and CODA-Prompt to improve their performance using powerful teacher models. Although recent CL methods focus on prompt learning, we show that our method can be utilized to build efficient CL models using prompt-based knowledge distillation.
Read more7/22/2024
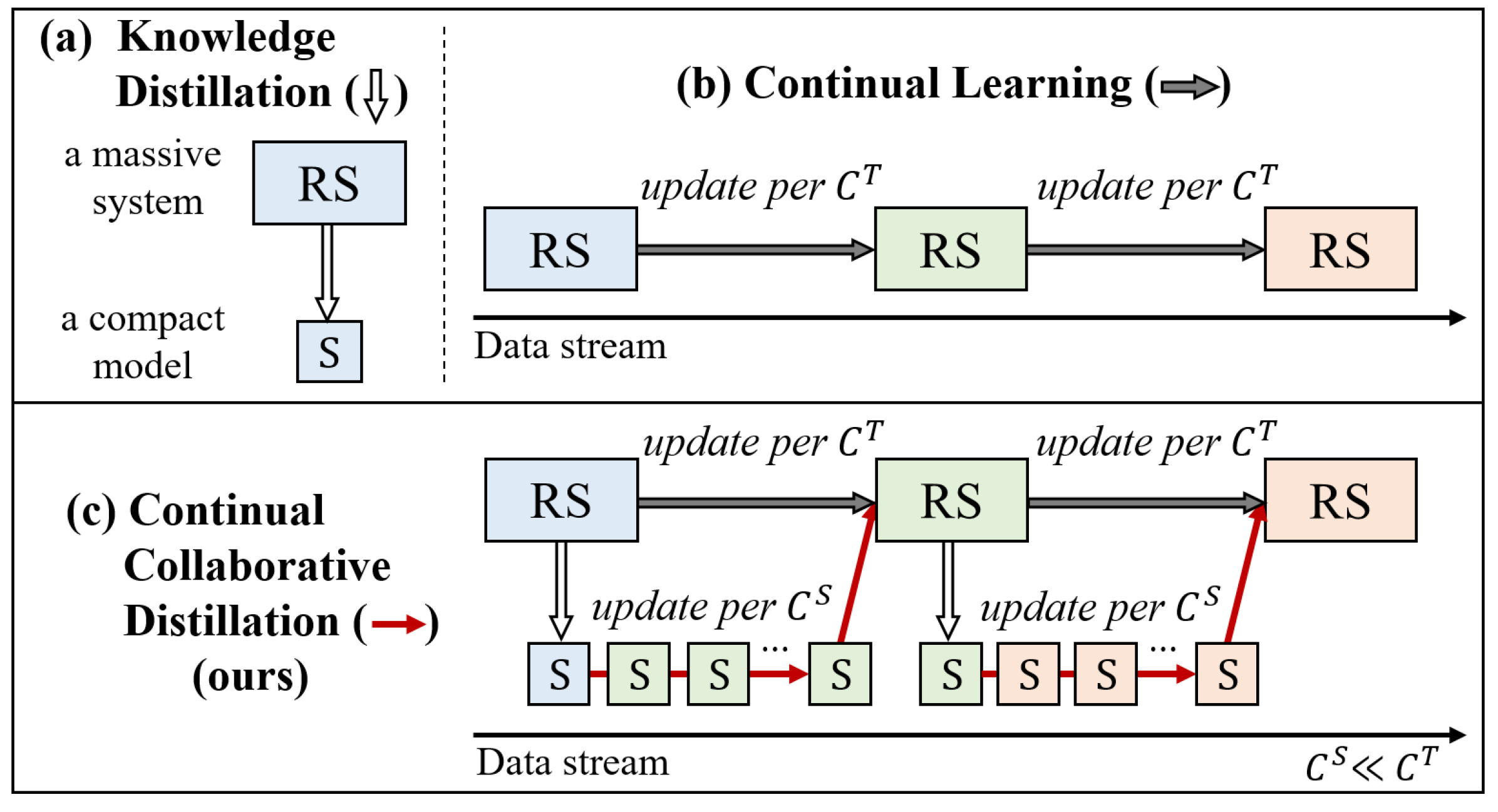
0
Continual Collaborative Distillation for Recommender System
Gyuseok Lee, SeongKu Kang, Wonbin Kweon, Hwanjo Yu
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.
Read more6/27/2024

0
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
Zheng Li, Xiang Li, Xinyi Fu, Xin Zhang, Weiqiang Wang, Shuo Chen, Jian Yang
Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-driven imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain (few-shot) labels. After pre-training, we leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. Further, we align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain. Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to (1) perform unsupervised domain-specific prompt-driven knowledge distillation for CLIP, and (2) establish a practical pre-storing mechanism of text features as shared class vectors between teacher and student. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
Read more8/14/2024

0
PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning
Gyeongman Kim, Doohyuk Jang, Eunho Yang
Recent advancements in large language models (LLMs) have raised concerns about inference costs, increasing the need for research into model compression. While knowledge distillation (KD) is a prominent method for this, research on KD for generative language models like LLMs is relatively sparse, and the approach of distilling student-friendly knowledge, which has shown promising performance in KD for classification models, remains unexplored in generative language models. To explore this approach, we propose PromptKD, a simple yet effective method that utilizes prompt tuning - for the first time in KD - to enable generative language models to transfer student-friendly knowledge. Unlike previous works in classification that require fine-tuning the entire teacher model for extracting student-friendly knowledge, PromptKD achieves similar effects by adding a small number of prompt tokens and tuning only the prompt with student guidance. Extensive experiments on instruction-following datasets show that PromptKD achieves state-of-the-art performance while adding only 0.0007% of the teacher's parameters as prompts. Further analysis suggests that distilling student-friendly knowledge alleviates exposure bias effectively throughout the entire training process, leading to performance enhancements.
Read more6/26/2024