Continual Learning From a Stream of APIs

0
🌐
Sign in to get full access
Overview
- Continual learning (CL) aims to learn new tasks without forgetting previous tasks.
- Existing CL methods require large amounts of raw data, which is often unavailable due to copyright and privacy concerns.
- Instead, stakeholders usually release pre-trained machine learning models as a service (MLaaS), which users can access via APIs.
- This paper considers two practical-yet-novel CL settings: data-efficient CL (DECL-APIs) and data-free CL (DFCL-APIs), which achieve CL from a stream of APIs with partial or no raw data.
Plain English Explanation
In the field of machine learning, continual learning (CL) is the ability for a model to learn new tasks without forgetting what it has learned before. This is an important capability, as it allows models to continuously expand their knowledge and skills over time.
However, most existing CL methods require large amounts of raw data, which can be difficult to obtain due to issues like copyright restrictions and privacy concerns. Instead, machine learning providers often make pre-trained models available as a service (MLaaS), allowing users to access them through application programming interfaces (APIs).
This paper explores two new, practical settings for CL: data-efficient CL (DECL-APIs) and data-free CL (DFCL-APIs). In these settings, the model must learn new tasks by interacting with a stream of APIs, without having access to the full raw data.
This poses several challenges, such as the lack of full raw data, unknown model parameters, and the risk of catastrophic forgetting (where the model forgets previous tasks when learning new ones).
Technical Explanation
To address these challenges, the paper proposes a "data-free cooperative continual distillation learning framework" that distills knowledge from a stream of APIs into a CL model by generating synthetic data through querying the APIs.
The framework includes two cooperative generators and one CL model, forming an adversarial game. The generators adversarially generate hard and diverse synthetic data to maximize the response gap between the CL model and the API. The CL model is then trained to minimize the gap between its responses and the black-box API's responses on the synthetic data, in order to transfer the API's knowledge.
Additionally, the researchers propose a new regularization term based on network similarity to prevent catastrophic forgetting of previous APIs.
Their method performs comparably to classic CL with full raw data in the DFCL-APIs setting. In the DECL-APIs setting, it achieves 0.97x, 0.75x, and 0.69x the performance of classic CL on CIFAR10, CIFAR100, and MiniImageNet, respectively.
Critical Analysis
The paper addresses important practical challenges in continual learning by considering settings where full raw data is unavailable. The proposed framework is a novel approach to tackling these challenges, using generative adversarial techniques to distill knowledge from a stream of APIs.
However, the paper does not discuss the potential limitations or drawbacks of this approach, such as the computational overhead of the adversarial training process or the sensitivity of the method to the quality and diversity of the APIs being used.
Additionally, the paper could have explored the impact of factors like the number of tasks, the complexity of the tasks, and the degree of similarity between tasks on the performance of the proposed method. Further research in these areas would help establish the broader applicability and limitations of the framework.
Conclusion
This paper presents a novel framework for continual learning from a stream of APIs, which is an important and practical problem in the field of machine learning. The proposed method demonstrates promising results and could have significant implications for real-world applications where raw data is scarce or unavailable.
However, further research is needed to fully understand the strengths, weaknesses, and broader applicability of this approach. As machine learning continues to be deployed in more diverse and data-constrained environments, innovative solutions like the one presented in this paper will be crucial for advancing the state of the art in continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Continual Learning From a Stream of APIs
Enneng Yang, Zhenyi Wang, Li Shen, Nan Yin, Tongliang Liu, Guibing Guo, Xingwei Wang, Dacheng Tao
Continual learning (CL) aims to learn new tasks without forgetting previous tasks. However, existing CL methods require a large amount of raw data, which is often unavailable due to copyright considerations and privacy risks. Instead, stakeholders usually release pre-trained machine learning models as a service (MLaaS), which users can access via APIs. This paper considers two practical-yet-novel CL settings: data-efficient CL (DECL-APIs) and data-free CL (DFCL-APIs), which achieve CL from a stream of APIs with partial or no raw data. Performing CL under these two new settings faces several challenges: unavailable full raw data, unknown model parameters, heterogeneous models of arbitrary architecture and scale, and catastrophic forgetting of previous APIs. To overcome these issues, we propose a novel data-free cooperative continual distillation learning framework that distills knowledge from a stream of APIs into a CL model by generating pseudo data, just by querying APIs. Specifically, our framework includes two cooperative generators and one CL model, forming their training as an adversarial game. We first use the CL model and the current API as fixed discriminators to train generators via a derivative-free method. Generators adversarially generate hard and diverse synthetic data to maximize the response gap between the CL model and the API. Next, we train the CL model by minimizing the gap between the responses of the CL model and the black-box API on synthetic data, to transfer the API's knowledge to the CL model. Furthermore, we propose a new regularization term based on network similarity to prevent catastrophic forgetting of previous APIs.Our method performs comparably to classic CL with full raw data on the MNIST and SVHN in the DFCL-APIs setting. In the DECL-APIs setting, our method achieves 0.97x, 0.75x and 0.69x performance of classic CL on CIFAR10, CIFAR100, and MiniImageNet.
Read more9/14/2024
🧠
0
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Read more4/24/2024
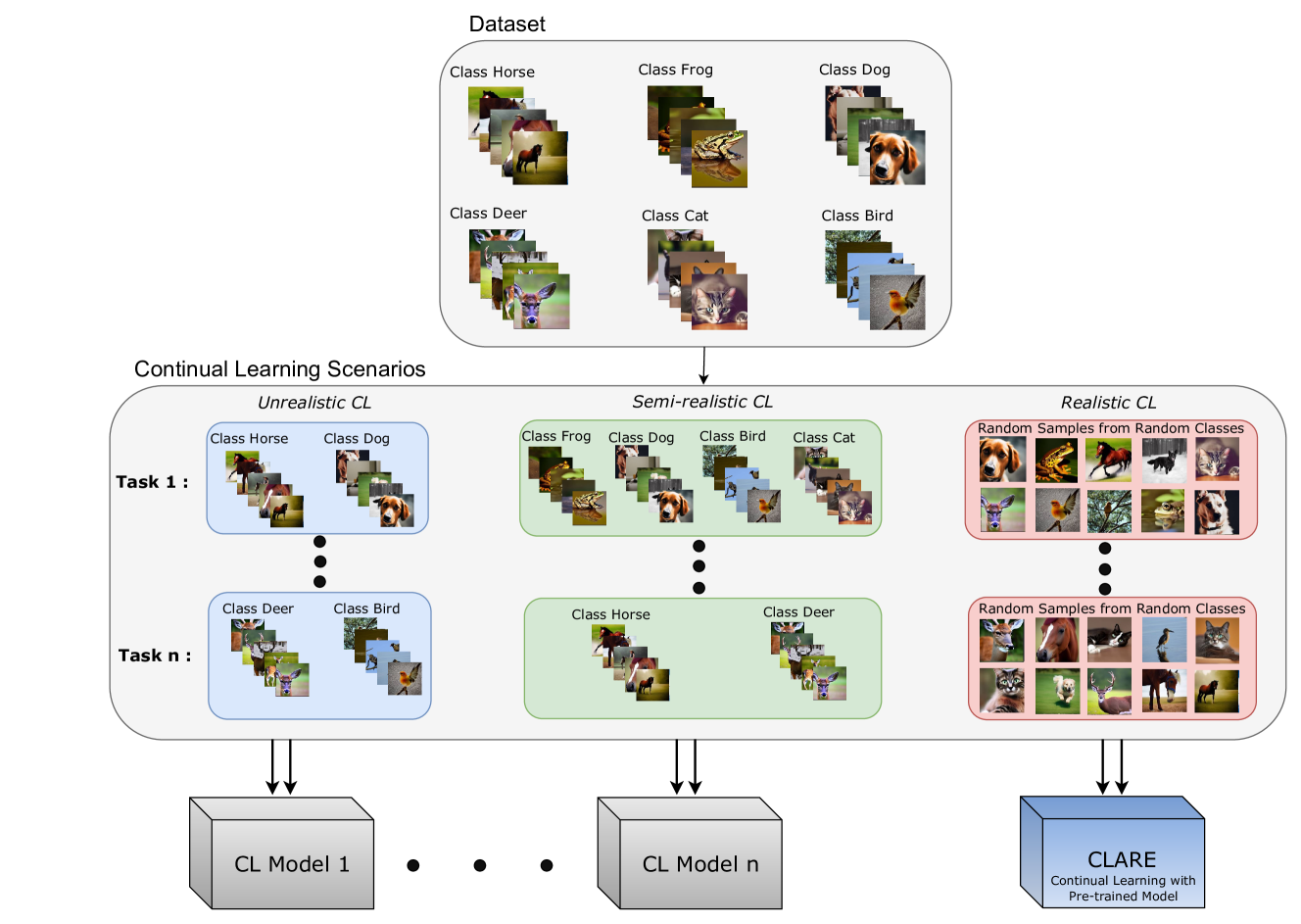
0
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024

0
Continual learning with task specialist
Indu Solomon, Aye Phyu Phyu Aung, Uttam Kumar, Senthilnath Jayavelu
Continual learning (CL) adapt the deep learning scenarios with timely updated datasets. However, existing CL models suffer from the catastrophic forgetting issue, where new knowledge replaces past learning. In this paper, we propose Continual Learning with Task Specialists (CLTS) to address the issues of catastrophic forgetting and limited labelled data in real-world datasets by performing class incremental learning of the incoming stream of data. The model consists of Task Specialists (T S) and Task Predictor (T P ) with pre-trained Stable Diffusion (SD) module. Here, we introduce a new specialist to handle a new task sequence and each T S has three blocks; i) a variational autoencoder (V AE) to learn the task distribution in a low dimensional latent space, ii) a K-Means block to perform data clustering and iii) Bootstrapping Language-Image Pre-training (BLIP ) model to generate a small batch of captions from the input data. These captions are fed as input to the pre-trained stable diffusion model (SD) for the generation of task samples. The proposed model does not store any task samples for replay, instead uses generated samples from SD to train the T P module. A comparison study with four SOTA models conducted on three real-world datasets shows that the proposed model outperforms all the selected baselines
Read more9/27/2024