Continual Learning of Numerous Tasks from Long-tail Distributions
2404.02754
0
0
✨
Abstract
Continual learning, an important aspect of artificial intelligence and machine learning research, focuses on developing models that learn and adapt to new tasks while retaining previously acquired knowledge. Existing continual learning algorithms usually involve a small number of tasks with uniform sizes and may not accurately represent real-world learning scenarios. In this paper, we investigate the performance of continual learning algorithms with a large number of tasks drawn from a task distribution that is long-tail in terms of task sizes. We design one synthetic dataset and two real-world continual learning datasets to evaluate the performance of existing algorithms in such a setting. Moreover, we study an overlooked factor in continual learning, the optimizer states, e.g. first and second moments in the Adam optimizer, and investigate how it can be used to improve continual learning performance. We propose a method that reuses the optimizer states in Adam by maintaining a weighted average of the second moments from previous tasks. We demonstrate that our method, compatible with most existing continual learning algorithms, effectively reduces forgetting with only a small amount of additional computational or memory costs, and provides further improvements on existing continual learning algorithms, particularly in a long-tail task sequence.
Create account to get full access
Overview
- Examines a method for continual learning of numerous tasks from long-tail distributions
- Introduces a "moment continual optimizer" to address challenges of catastrophic forgetting and limited data
- Demonstrates the approach outperforms existing continual learning methods on a range of benchmark tasks
Plain English Explanation
This research tackles the challenge of continual learning, where an AI system needs to learn and retain knowledge from a large number of tasks over time. The key issue is "catastrophic forgetting" - when learning a new task, the system tends to forget what it previously learned.
The researchers propose a "moment continual optimizer" approach to address this. The core idea is to not only update the weights (the primary parameters) of the neural network during learning, but also carefully manage the second moment statistics (related to the variance) of those weights. This allows the system to retain information about previous tasks while still flexibly adapting to new ones.
The method is evaluated on a range of benchmark continual learning tasks, including both natural images and synthetic long-tail distributions. The results show the moment continual optimizer outperforms existing continual learning techniques, demonstrating its effectiveness at enabling an AI system to continuously learn many diverse tasks without forgetting.
Technical Explanation
The paper introduces a novel continual learning algorithm called the "Moment Continual Optimizer" (MCO). The key innovation is to not only update the network weights during learning, but also dynamically manage the second moment (variance) of those weights.
Specifically, MCO maintains separate running estimates of the first and second moments for each parameter. When learning a new task, it updates both the weights and their second moments. This allows the network to flexibly adapt to the new task while also preserving information about previous tasks in the second moment statistics.
The authors show that this approach outperforms prior continual learning methods on a variety of benchmark tasks, including both natural image datasets and synthetically generated long-tail distributions. Experiments demonstrate MCO's effectiveness at enabling an AI system to continuously learn a large number of diverse tasks without catastrophically forgetting previous knowledge.
Critical Analysis
The paper provides a thoughtful and thorough evaluation of the proposed MCO approach, exploring its performance on a range of continual learning benchmarks. The authors acknowledge some limitations, noting that their method still struggles with tasks that are drastically different from previous ones.
An open question is how to further improve MCO's ability to learn truly novel tasks without interference from past knowledge. The authors suggest exploring more sophisticated weight consolidation techniques and architectural modifications as potential avenues for future research.
Additionally, the paper focuses on standard academic benchmarks, so evaluating MCO's real-world applicability in more complex, open-ended continual learning scenarios would be a valuable direction for further study.
Overall, the Moment Continual Optimizer represents an important contribution to the field of continual learning, demonstrating the value of carefully managing not just network weights, but their higher-order statistical moments as well. With continued refinements, this approach could unlock new capabilities for AI systems that must learn and adapt to a diverse, ever-changing set of tasks.
Conclusion
This research introduces a novel continual learning algorithm called the Moment Continual Optimizer (MCO) that goes beyond simply updating network weights. By also dynamically managing the second moment (variance) of those weights, MCO enables an AI system to continuously learn a large number of diverse tasks without catastrophic forgetting.
Extensive experiments show MCO outperforming existing continual learning methods on a range of benchmark tasks, highlighting its effectiveness at enabling flexible, long-term learning. While challenges remain, this work represents an important step forward in developing AI systems that can adapt and grow their knowledge over time, much like humans do.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
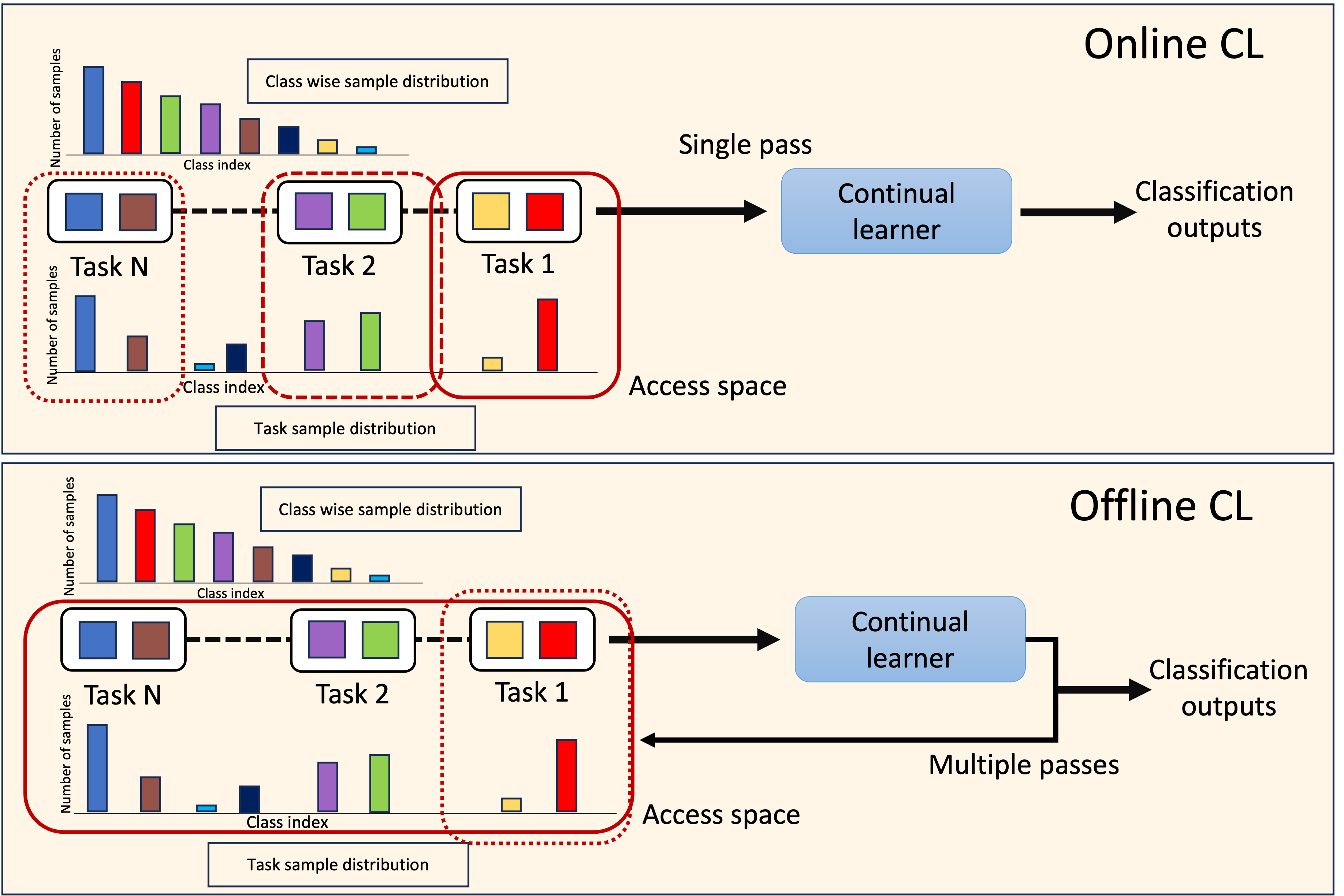
DELTA: Decoupling Long-Tailed Online Continual Learning
Siddeshwar Raghavan, Jiangpeng He, Fengqing Zhu
0
0
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
4/9/2024
👁️
TAME: Task Agnostic Continual Learning using Multiple Experts
Haoran Zhu, Maryam Majzoubi, Arihant Jain, Anna Choromanska
0
0
The goal of lifelong learning is to continuously learn from non-stationary distributions, where the non-stationarity is typically imposed by a sequence of distinct tasks. Prior works have mostly considered idealistic settings, where the identity of tasks is known at least at training. In this paper we focus on a fundamentally harder, so-called task-agnostic setting where the task identities are not known and the learning machine needs to infer them from the observations. Our algorithm, which we call TAME (Task-Agnostic continual learning using Multiple Experts), automatically detects the shift in data distributions and switches between task expert networks in an online manner. At training, the strategy for switching between tasks hinges on an extremely simple observation that for each new coming task there occurs a statistically-significant deviation in the value of the loss function that marks the onset of this new task. At inference, the switching between experts is governed by the selector network that forwards the test sample to its relevant expert network. The selector network is trained on a small subset of data drawn uniformly at random. We control the growth of the task expert networks as well as selector network by employing online pruning. Our experimental results show the efficacy of our approach on benchmark continual learning data sets, outperforming the previous task-agnostic methods and even the techniques that admit task identities at both training and testing, while at the same time using a comparable model size.
6/4/2024
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024
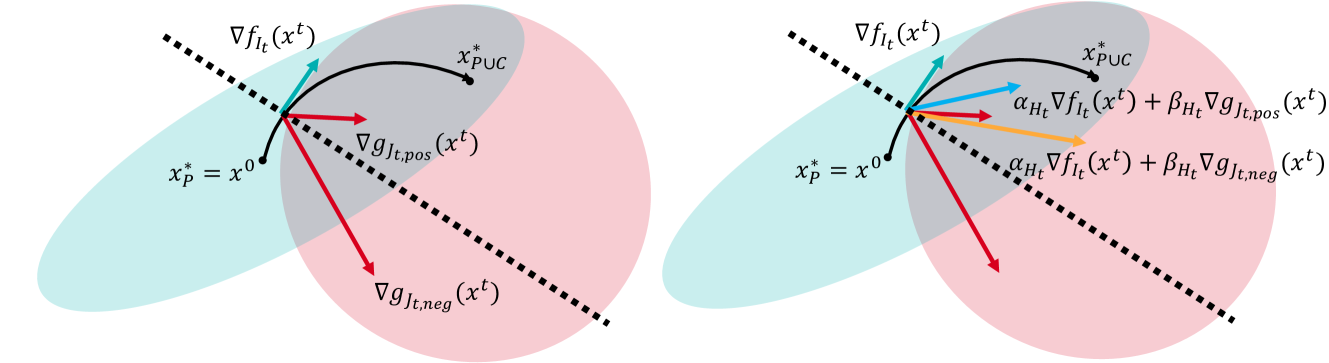
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
0
0
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
4/16/2024