Calibration of Continual Learning Models
2404.07817
0
0
Abstract
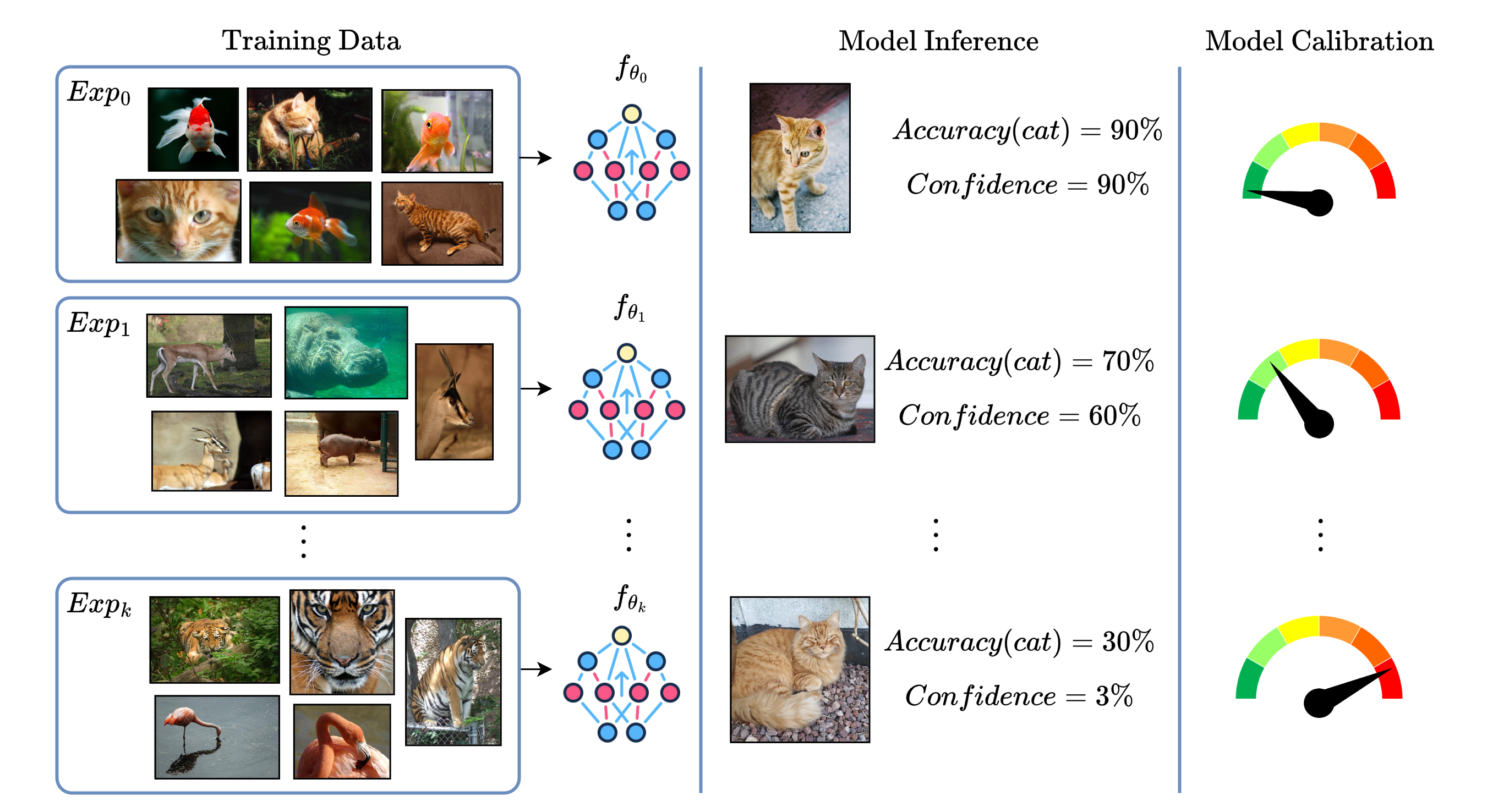
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
Create account to get full access
Overview
- This paper explores the problem of calibration in continual learning models, which are AI systems that learn and adapt over time.
- Calibration refers to how well a model's output probabilities reflect the true likelihood of its predictions being correct.
- The authors investigate techniques for improving the calibration of continual learning models, which can be challenging as the models encounter new tasks and data over time.
Plain English Explanation
Continual learning models are a type of AI system that can keep learning and updating their knowledge over time, rather than just learning a fixed set of information. This is an important capability, as the real world is always changing and evolving. However, as these models encounter new tasks and data, it can become difficult to ensure their output probabilities accurately reflect how likely their predictions are to be correct.
This is known as the problem of calibration. If a model is well-calibrated, its confidence scores will match the true likelihood of its predictions being right. For example, if the model is 80% confident in an answer, that answer should be correct 80% of the time.
The researchers in this paper investigate different techniques to improve the calibration of continual learning models. This is an important challenge to solve, as well-calibrated models can provide more trustworthy and reliable outputs, which is crucial for real-world applications of this technology.
Technical Explanation
The paper first provides background on the concept of calibration in neural networks. It explains how standard training procedures can lead to overconfident or miscalibrated models, and discusses prior work on improving calibration, such as temperature scaling and test-time augmentation.
The authors then examine the unique challenges of calibration in the context of continual learning. As models learn new tasks over time, their outputs can become increasingly miscalibrated. The paper proposes several methods to address this, including:
- Replay-based calibration: Using a small memory buffer of past data to periodically recalibrate the model.
- Adaptive temperature scaling: Dynamically adjusting the temperature scaling factor as the model learns new tasks.
- Task-aware calibration: Maintaining separate calibration parameters for each task the model has learned.
The authors evaluate these techniques on several continual learning benchmarks, and find that they can significantly improve model calibration compared to standard approaches.
Critical Analysis
The paper provides a thorough investigation of the calibration problem in continual learning, and the proposed solutions seem reasonably effective based on the experimental results. However, the authors acknowledge that their methods may not scale well to very long sequences of tasks, as the memory buffer and separate calibration parameters could become unwieldy.
Additionally, the paper does not address the broader challenge of catastrophic forgetting in continual learning, where models tend to forget previously learned information as they adapt to new tasks. Improving calibration is important, but it does not solve the fundamental issue of preserving knowledge over time.
Further research could explore integrating calibration techniques with other continual learning approaches that aim to mitigate catastrophic forgetting, such as generalized continual learning or long-tailed online continual learning. This could lead to more robust and reliable continual learning systems.
Conclusion
This paper tackles the critical problem of improving the calibration of continual learning models, which is essential for ensuring their outputs are trustworthy and well-aligned with the true likelihood of their predictions. The proposed techniques, such as replay-based calibration and adaptive temperature scaling, show promise in enhancing model calibration, but further research is needed to address the broader challenges of continual learning, such as catastrophic forgetting.
As continual learning systems become more prevalent in real-world applications, ensuring their reliability and transparency through improved calibration will be crucial for building public trust and confidence in this transformative AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
0
0
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
4/24/2024
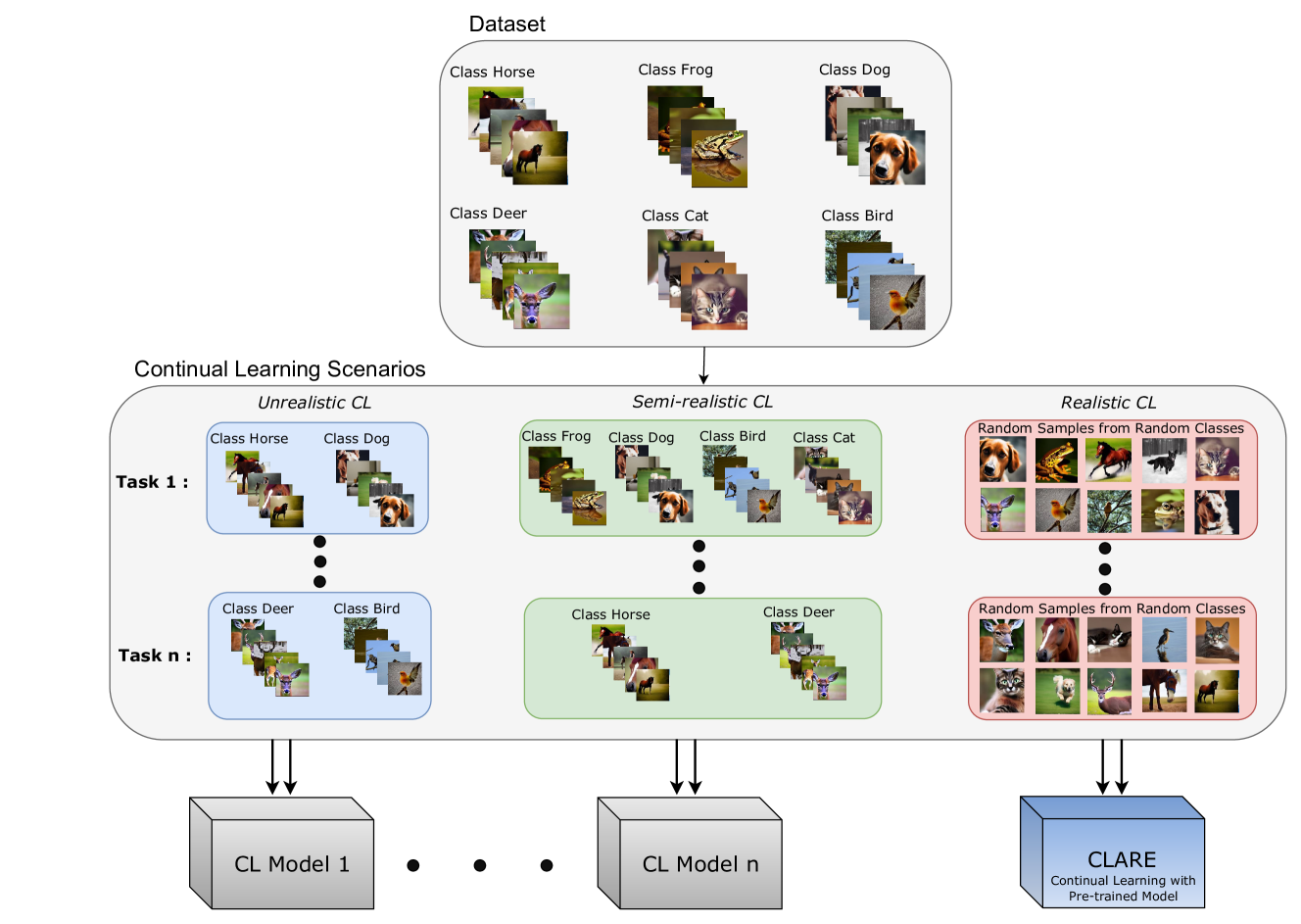
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024
🤿
Calibration in Deep Learning: A Survey of the State-of-the-Art
Cheng Wang
0
0
Calibrating deep neural models plays an important role in building reliable, robust AI systems in safety-critical applications. Recent work has shown that modern neural networks that possess high predictive capability are poorly calibrated and produce unreliable model predictions. Though deep learning models achieve remarkable performance on various benchmarks, the study of model calibration and reliability is relatively underexplored. Ideal deep models should have not only high predictive performance but also be well calibrated. There have been some recent advances in calibrating deep models. In this survey, we review the state-of-the-art calibration methods and their principles for performing model calibration. First, we start with the definition of model calibration and explain the root causes of model miscalibration. Then we introduce the key metrics that can measure this aspect. It is followed by a summary of calibration methods that we roughly classify into four categories: post-hoc calibration, regularization methods, uncertainty estimation, and composition methods. We also cover recent advancements in calibrating large models, particularly large language models (LLMs). Finally, we discuss some open issues, challenges, and potential directions.
5/13/2024
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024