Large Language Model Can Continue Evolving From Mistakes
2404.08707
0
0
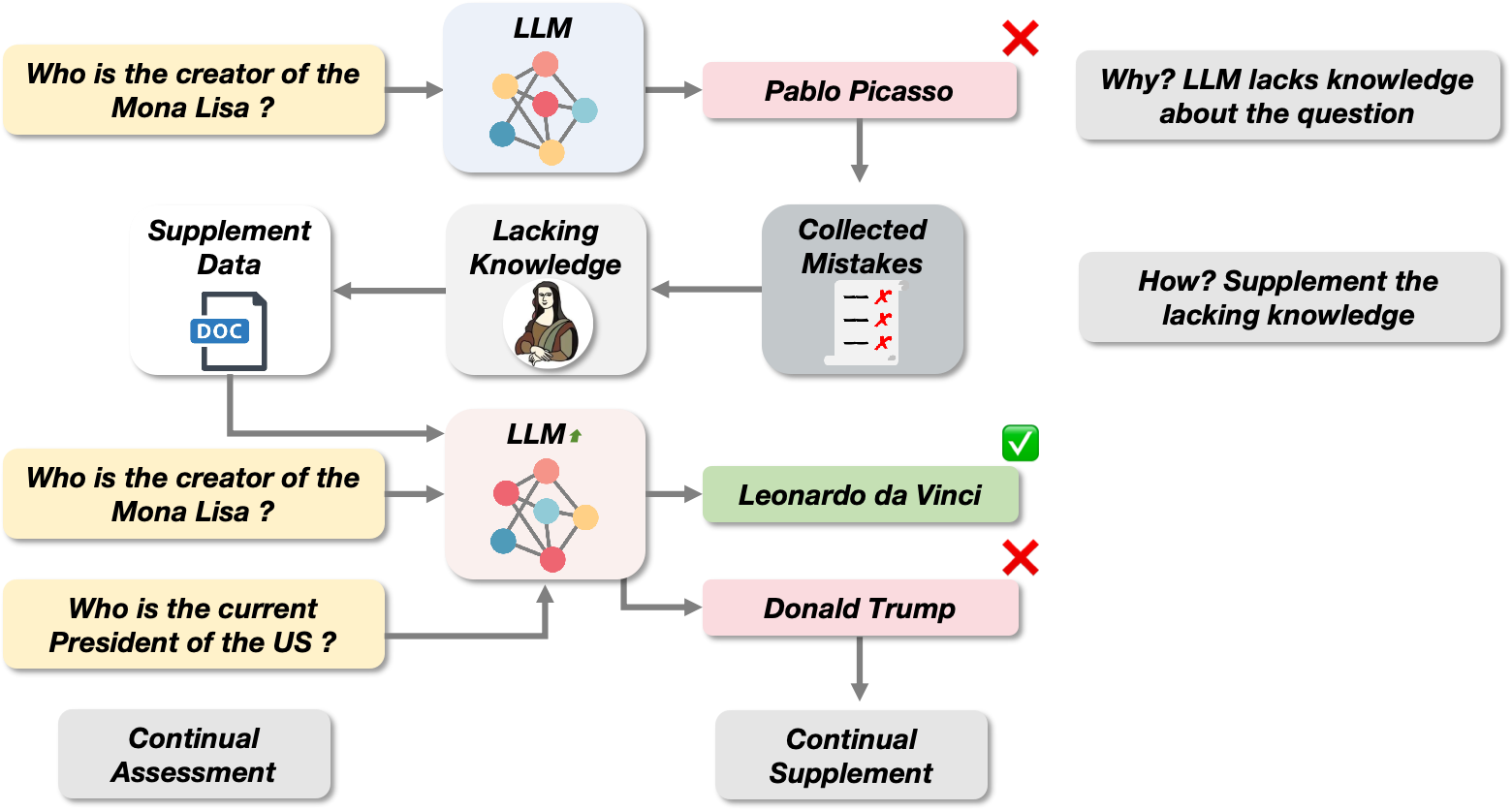
Abstract
As world knowledge evolves and new task paradigms emerge, Continual Learning (CL) is crucial for keeping Large Language Models (LLMs) up-to-date and addressing their shortcomings. In practical applications, LLMs often require both continual instruction tuning (CIT) and continual pre-training (CPT) to adapt to new task paradigms and acquire necessary knowledge for task-solving. However, it remains challenging to collect CPT data that addresses the knowledge deficiencies in models while maintaining adequate volume, and improving the efficiency of utilizing this data also presents significant difficulties. Inspired by the 'summarizing mistakes' learning skill, we propose the Continue Evolving from Mistakes (CEM) method, aiming to provide a data-efficient approach for collecting CPT data and continually improving LLMs' performance through iterative evaluation and supplementation with mistake-relevant knowledge. To efficiently utilize these CPT data and mitigate forgetting, we design a novel CL training set construction paradigm that integrates parallel CIT and CPT data. Extensive experiments demonstrate the efficacy of the CEM method, achieving up to a 17% improvement in accuracy in the best case. Furthermore, additional experiments confirm the potential of combining CEM with catastrophic forgetting mitigation methods, enabling iterative and continual model evolution.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can continue evolving and improving by learning from their mistakes.
- The researchers propose a novel method for "continual learning" that allows LLMs to adapt and refine their capabilities over time.
- The key idea is to leverage the model's own errors and uncertainty to guide its further training and optimization.
- This approach builds on recent work in continual learning and learning from mistakes.
Plain English Explanation
The paper describes a way for large language models (LLMs) to keep getting better over time, even after their initial training. The key insight is that the model's own mistakes and uncertainties can be used to guide its further learning and improvement.
Imagine an LLM like a young student - at first, it makes a lot of mistakes, but as it keeps practicing and learning from those errors, it gradually becomes more knowledgeable and capable. The researchers found a way to automate this process, allowing the LLM to continually refine and expand its abilities, much like a human learner.
Rather than just retraining the model on more data, this approach focuses on the model's own internal signals about what it's unsure about or getting wrong. By targeting those areas specifically, the LLM can efficiently shore up its weaknesses and develop new strengths. This calibration and continual learning approach allows the model to essentially "learn how to learn" and evolve over time.
The potential benefits are significant - LLMs could become more reliable, versatile, and aligned with human values by continually improving themselves. This iterated learning perspective on language model evolution could lead to practical tools for using LLMs that are more robust and adaptable.
Technical Explanation
The researchers propose a novel "continual learning" framework for large language models (LLMs) that allows them to iteratively refine their capabilities by learning from their own mistakes and uncertainties.
The core idea is to use the model's own internal signals about its performance - such as confidence scores, error rates, and uncertainty estimates - to guide further training and optimization. Rather than just retraining the model on more data, this approach selectively focuses on the areas where the model is struggling or least confident.
Specifically, the authors introduce a multi-stage training process:
-
Pre-training: The LLM is first trained on a large corpus of text data using standard techniques.
-
Continual Fine-tuning: The model is then subjected to a series of fine-tuning steps, where it is exposed to new tasks or datasets. After each fine-tuning round, the model's own performance metrics are analyzed to identify weaknesses.
-
Targeted Re-training: The model is then selectively retrained on the specific areas it struggled with, using a combination of the original training data and targeted examples designed to address those shortcomings.
This iterative cycle of fine-tuning, self-evaluation, and targeted re-training allows the LLM to continually evolve and expand its capabilities over time. The authors demonstrate the effectiveness of this approach through experiments on various language understanding benchmarks, showing that it leads to substantial performance improvements compared to standard fine-tuning methods.
Critical Analysis
The researchers present a compelling approach for enabling large language models to engage in ongoing self-improvement. By leveraging the model's own internal signals about its performance, this continual learning framework could help address some key limitations of current LLM systems.
One potential limitation is that the authors do not provide a detailed analysis of the computational cost and training time required for this iterative process. Retraining large models multiple times could be computationally intensive, which may limit the practical feasibility of this approach, especially for resource-constrained real-world applications.
Additionally, the paper does not delve into potential safety and ethical considerations around this type of self-improving AI system. As LLMs become more capable and autonomous, there may be concerns around unpredictable behavior, value alignment, and potential negative societal impacts that warrant further investigation.
Overall, this research represents an important step towards more practical and robust language models that can continually evolve and refine their abilities. However, further work is needed to fully understand the implications and limitations of this continual learning approach, especially as it pertains to the long-term development of advanced AI systems.
Conclusion
This paper introduces a novel continual learning framework that enables large language models to iteratively improve their capabilities by learning from their own mistakes and uncertainties. By selectively retraining the model on its weaker areas, this approach allows the LLM to continually evolve and expand its skills over time.
The potential benefits are significant - LLMs could become more reliable, versatile, and aligned with human values by engaging in this ongoing self-improvement process. This "learning how to learn" perspective on language model evolution could lead to practical tools for using LLMs that are more robust and adaptable to a wide range of tasks and environments.
While further research is needed to fully understand the implications and limitations of this continual learning approach, this paper represents an important step towards more realistic and effective continual learning for advanced AI systems. By empowering LLMs to continuously refine and expand their abilities, we may be able to unlock new frontiers in natural language processing and intelligent systems that can better serve humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
7/2/2024

Recent Advances of Foundation Language Models-based Continual Learning: A Survey
Yutao Yang, Jie Zhou, Xuanwen Ding, Tianyu Huai, Shunyu Liu, Qin Chen, Liang He, Yuan Xie
0
0
Recently, foundation language models (LMs) have marked significant achievements in the domains of natural language processing (NLP) and computer vision (CV). Unlike traditional neural network models, foundation LMs obtain a great ability for transfer learning by acquiring rich commonsense knowledge through pre-training on extensive unsupervised datasets with a vast number of parameters. However, they still can not emulate human-like continuous learning due to catastrophic forgetting. Consequently, various continual learning (CL)-based methodologies have been developed to refine LMs, enabling them to adapt to new tasks without forgetting previous knowledge. However, a systematic taxonomy of existing approaches and a comparison of their performance are still lacking, which is the gap that our survey aims to fill. We delve into a comprehensive review, summarization, and classification of the existing literature on CL-based approaches applied to foundation language models, such as pre-trained language models (PLMs), large language models (LLMs) and vision-language models (VLMs). We divide these studies into offline CL and online CL, which consist of traditional methods, parameter-efficient-based methods, instruction tuning-based methods and continual pre-training methods. Offline CL encompasses domain-incremental learning, task-incremental learning, and class-incremental learning, while online CL is subdivided into hard task boundary and blurry task boundary settings. Additionally, we outline the typical datasets and metrics employed in CL research and provide a detailed analysis of the challenges and future work for LMs-based continual learning.
5/30/2024
🧠
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
0
0
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
4/24/2024
💬
Towards Lifelong Learning of Large Language Models: A Survey
Junhao Zheng, Shengjie Qiu, Chengming Shi, Qianli Ma
0
0
As the applications of large language models (LLMs) expand across diverse fields, the ability of these models to adapt to ongoing changes in data, tasks, and user preferences becomes crucial. Traditional training methods, relying on static datasets, are increasingly inadequate for coping with the dynamic nature of real-world information. Lifelong learning, also known as continual or incremental learning, addresses this challenge by enabling LLMs to learn continuously and adaptively over their operational lifetime, integrating new knowledge while retaining previously learned information and preventing catastrophic forgetting. This survey delves into the sophisticated landscape of lifelong learning, categorizing strategies into two primary groups: Internal Knowledge and External Knowledge. Internal Knowledge includes continual pretraining and continual finetuning, each enhancing the adaptability of LLMs in various scenarios. External Knowledge encompasses retrieval-based and tool-based lifelong learning, leveraging external data sources and computational tools to extend the model's capabilities without modifying core parameters. The key contributions of our survey are: (1) Introducing a novel taxonomy categorizing the extensive literature of lifelong learning into 12 scenarios; (2) Identifying common techniques across all lifelong learning scenarios and classifying existing literature into various technique groups within each scenario; (3) Highlighting emerging techniques such as model expansion and data selection, which were less explored in the pre-LLM era. Through a detailed examination of these groups and their respective categories, this survey aims to enhance the adaptability, reliability, and overall performance of LLMs in real-world applications.
6/11/2024