Continual Policy Distillation of Reinforcement Learning-based Controllers for Soft Robotic In-Hand Manipulation
2404.04219
0
0

Abstract
Dexterous manipulation, often facilitated by multi-fingered robotic hands, holds solid impact for real-world applications. Soft robotic hands, due to their compliant nature, offer flexibility and adaptability during object grasping and manipulation. Yet, benefits come with challenges, particularly in the control development for finger coordination. Reinforcement Learning (RL) can be employed to train object-specific in-hand manipulation policies, but limiting adaptability and generalizability. We introduce a Continual Policy Distillation (CPD) framework to acquire a versatile controller for in-hand manipulation, to rotate different objects in shape and size within a four-fingered soft gripper. The framework leverages Policy Distillation (PD) to transfer knowledge from expert policies to a continually evolving student policy network. Exemplar-based rehearsal methods are then integrated to mitigate catastrophic forgetting and enhance generalization. The performance of the CPD framework over various replay strategies demonstrates its effectiveness in consolidating knowledge from multiple experts and achieving versatile and adaptive behaviours for in-hand manipulation tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a method called "Continual Policy Distillation" for training reinforcement learning-based controllers for soft robotic in-hand manipulation tasks.
- The key idea is to distill the knowledge from a series of reinforcement learning policies into a single, more efficient policy that can be deployed on a physical soft robotic system.
- The approach aims to enable soft robots to perform dexterous in-hand manipulation tasks, which are challenging due to the robot's complex dynamics and the need for precise control.
Plain English Explanation
The paper presents a new technique for training robots to perform delicate, intricate motions with their hands or "fingers". These kinds of tasks, called "in-hand manipulation", are very difficult for robots to learn, especially for soft robots that have flexible, squishy parts instead of rigid metal or plastic.
The researchers developed a method called "Continual Policy Distillation" to address this challenge. The basic idea is to first train a series of reinforcement learning-based control policies, which are essentially sets of rules that tell the robot how to move its "fingers" to manipulate objects. [These policies are trained using a technique called reinforcement learning, where the robot explores different actions and is rewarded for ones that accomplish the task.]
Then, the researchers take all these individual policies and "distill" them down into a single, more efficient policy that captures the key knowledge from the whole series. This final policy can then be deployed on the physical soft robotic system to perform dexterous in-hand manipulation tasks.
The key benefit of this approach is that it allows the robot to learn complex manipulation skills in a step-by-step, incremental way, rather than having to learn everything at once. This makes the training process more efficient and practical, especially for soft robots which are challenging to control.
Technical Explanation
The paper presents a "Continual Policy Distillation" method for training reinforcement learning-based controllers for soft robotic in-hand manipulation tasks. The core idea is to distill a sequence of reinforcement learning policies into a single, consolidated policy that can be deployed on a physical soft robotic system.
The researchers first train a series of reinforcement learning policies, each targeting a different sub-task or phase of the overall in-hand manipulation objective. These individual policies are trained using standard reinforcement learning algorithms, like proximal policy optimization (PPO) or soft actor-critic (SAC).
Next, the key innovation is the "distillation" step, where the researchers combine these multiple policies into a single, more efficient policy. They do this by training a new "distilled" policy to mimic the behavior of the original policy sequence, using a distributionally robust optimization approach to ensure stability and robustness.
The benefits of this approach are two-fold. First, it allows the robot to learn complex manipulation skills in a step-by-step, incremental way, rather than having to learn everything at once. This makes the training process more efficient and practical, especially for soft robots which are challenging to control. Second, the final distilled policy is more compact and computationally efficient than the original sequence, enabling deployment on physical robotic platforms.
The researchers validate their approach through extensive simulation experiments, demonstrating the distilled policy's ability to perform dexterous in-hand manipulation tasks on a variety of soft robotic hand designs. They also discuss task-priority and hierarchical control as potential extensions to further improve the robustness and flexibility of the controllers.
Critical Analysis
The paper presents a novel and promising approach for training soft robotic in-hand manipulation controllers. The key strength of the Continual Policy Distillation method is its ability to learn complex skills in an incremental, step-by-step fashion, which is particularly valuable for the challenging control dynamics of soft robotic systems.
However, the paper also acknowledges some important limitations and areas for further research. For example, the distillation process assumes that the original reinforcement learning policies are all successful and non-conflicting, which may not always be the case in practice. [Addressing issues of distributionally robust reinforcement learning and policy alignment could help improve the robustness of the distillation process.
Additionally, the paper focuses primarily on simulation experiments, and more work would be needed to validate the approach on physical soft robotic hardware. Practical challenges around sensor noise, model mismatch, and hardware constraints would need to be carefully considered.
Overall, the Continual Policy Distillation method represents an important step forward in enabling dexterous in-hand manipulation for soft robotic systems. However, further research and real-world validation will be needed to fully realize the potential of this approach.
Conclusion
This paper introduces a novel "Continual Policy Distillation" method for training reinforcement learning-based controllers for soft robotic in-hand manipulation tasks. The key idea is to distill a sequence of individual reinforcement learning policies into a single, more efficient policy that can be deployed on physical soft robotic systems.
The main benefit of this approach is that it allows the robot to learn complex manipulation skills in an incremental, step-by-step fashion, rather than having to learn everything at once. This makes the training process more efficient and practical, especially for challenging soft robotic systems.
While the paper demonstrates promising results in simulation, further research and real-world validation will be needed to fully realize the potential of this approach. Addressing issues around policy alignment, robustness, and hardware constraints will be important next steps. Overall, the Continual Policy Distillation method represents an important advance in enabling dexterous in-hand manipulation for soft robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
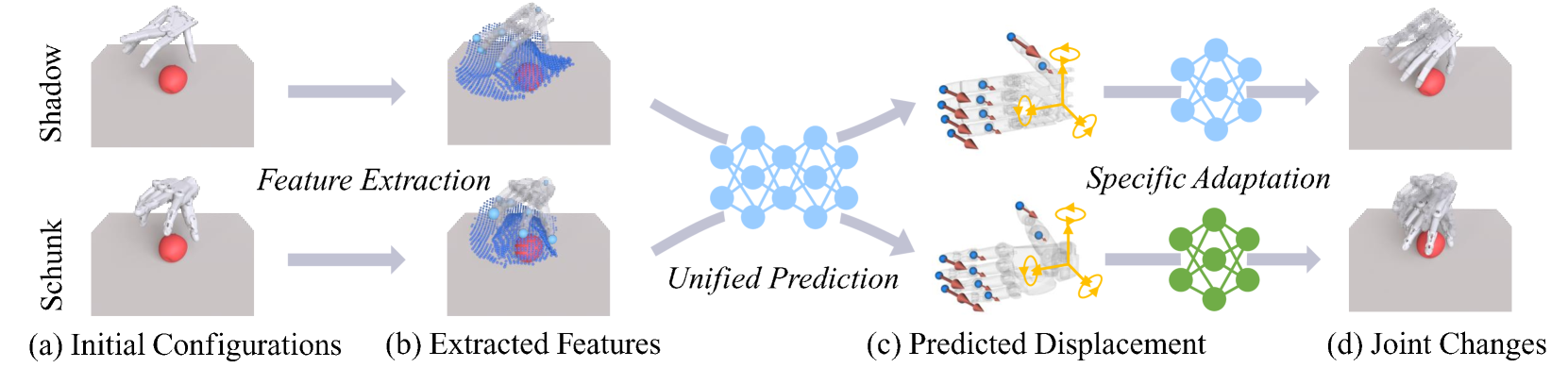
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Qijin She, Shishun Zhang, Yunfan Ye, Min Liu, Ruizhen Hu, Kai Xu
0
0
Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper without retraining. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of predefined key points on the gripper, and a gripper specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experimental part, we evaluate our method on several dexterous grippers and objects of diverse shapes, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across different dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands
4/16/2024
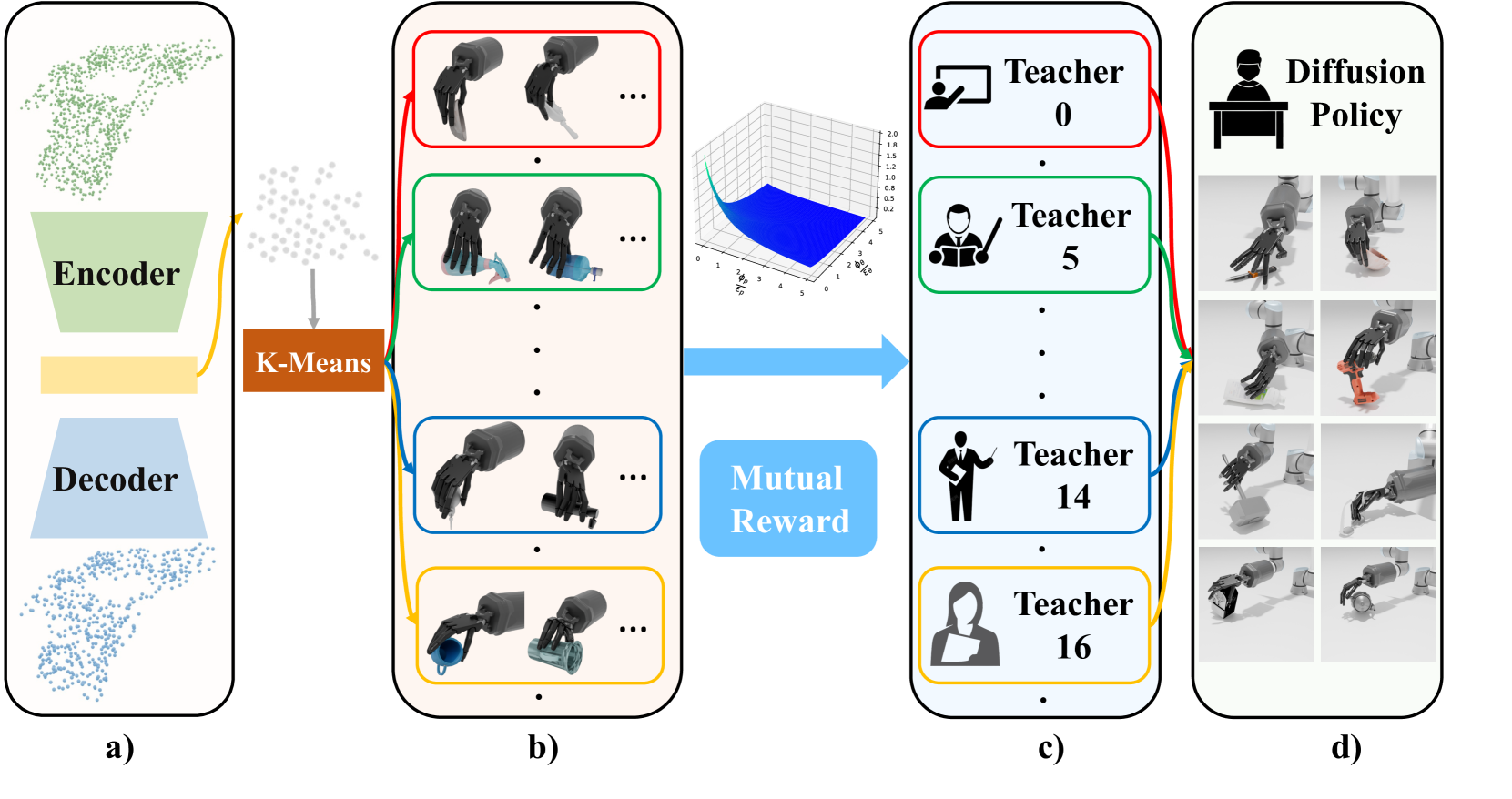
Dexterous Functional Pre-Grasp Manipulation with Diffusion Policy
Tianhao Wu, Yunchong Gan, Mingdong Wu, Jingbo Cheng, Yaodong Yang, Yixin Zhu, Hao Dong
0
0
In real-world scenarios, objects often require repositioning and reorientation before they can be grasped, a process known as pre-grasp manipulation. Learning universal dexterous functional pre-grasp manipulation requires precise control over the relative position, orientation, and contact between the hand and object while generalizing to diverse dynamic scenarios with varying objects and goal poses. To address this challenge, we propose a teacher-student learning approach that utilizes a novel mutual reward, incentivizing agents to optimize three key criteria jointly. Additionally, we introduce a pipeline that employs a mixture-of-experts strategy to learn diverse manipulation policies, followed by a diffusion policy to capture complex action distributions from these experts. Our method achieves a success rate of 72.6% across more than 30 object categories by leveraging extrinsic dexterity and adjusting from feedback.
5/7/2024
↗️
Integrating DeepRL with Robust Low-Level Control in Robotic Manipulators for Non-Repetitive Reaching Tasks
Mehdi Heydari Shahna, Seyed Adel Alizadeh Kolagar, Jouni Mattila
0
0
In robotics, contemporary strategies are learning-based, characterized by a complex black-box nature and a lack of interpretability, which may pose challenges in ensuring stability and safety. To address these issues, we propose integrating a collision-free trajectory planner based on deep reinforcement learning (DRL) with a novel auto-tuning low-level control strategy, all while actively engaging in the learning phase through interactions with the environment. This approach circumvents the control performance and complexities associated with computations while addressing nonrepetitive reaching tasks in the presence of obstacles. First, a model-free DRL agent is employed to plan velocity-bounded motion for a manipulator with 'n' degrees of freedom (DoF), ensuring collision avoidance for the end-effector through joint-level reasoning. The generated reference motion is then input into a robust subsystem-based adaptive controller, which produces the necessary torques, while the cuckoo search optimization (CSO) algorithm enhances control gains to minimize the stabilization and tracking error in the steady state. This approach guarantees robustness and uniform exponential convergence in an unfamiliar environment, despite the presence of uncertainties and disturbances. Theoretical assertions are validated through the presentation of simulation outcomes.
5/16/2024
🐍
Learning Extrinsic Dexterity with Parameterized Manipulation Primitives
Shih-Min Yang, Martin Magnusson, Johannes A. Stork, Todor Stoyanov
0
0
Many practically relevant robot grasping problems feature a target object for which all grasps are occluded, e.g., by the environment. Single-shot grasp planning invariably fails in such scenarios. Instead, it is necessary to first manipulate the object into a configuration that affords a grasp. We solve this problem by learning a sequence of actions that utilize the environment to change the object's pose. Concretely, we employ hierarchical reinforcement learning to combine a sequence of learned parameterized manipulation primitives. By learning the low-level manipulation policies, our approach can control the object's state through exploiting interactions between the object, the gripper, and the environment. Designing such a complex behavior analytically would be infeasible under uncontrolled conditions, as an analytic approach requires accurate physical modeling of the interaction and contact dynamics. In contrast, we learn a hierarchical policy model that operates directly on depth perception data, without the need for object detection, pose estimation, or manual design of controllers. We evaluate our approach on picking box-shaped objects of various weight, shape, and friction properties from a constrained table-top workspace. Our method transfers to a real robot and is able to successfully complete the object picking task in 98% of experimental trials. Supplementary information and videos can be found at https://shihminyang.github.io/ED-PMP/.
5/10/2024