A Continued Pretrained LLM Approach for Automatic Medical Note Generation
2403.09057
0
0
🛸
Abstract
LLMs are revolutionizing NLP tasks. However, the use of the most advanced LLMs, such as GPT-4, is often prohibitively expensive for most specialized fields. We introduce HEAL, the first continuously trained 13B LLaMA2-based LLM that is purpose-built for medical conversations and measured on automated scribing. Our results demonstrate that HEAL outperforms GPT-4 and PMC-LLaMA in PubMedQA, with an accuracy of 78.4%. It also achieves parity with GPT-4 in generating medical notes. Remarkably, HEAL surpasses GPT-4 and Med-PaLM 2 in identifying more correct medical concepts and exceeds the performance of human scribes and other comparable models in correctness and completeness.
Create account to get full access
Overview
- This paper proposes a continued pretraining approach for large language models to automatically generate medical notes.
- The key idea is to take a pre-trained language model and further fine-tune it on a dataset of medical notes to specialize it for this task.
- The authors evaluate their approach on several medical note generation benchmarks and find it outperforms previous methods.
Plain English Explanation
Medical notes are an important part of healthcare, summarizing a patient's condition, treatment, and progress. Generating these notes automatically could save doctors time and improve consistency. However, this is a challenging task that requires specialized medical knowledge.
The researchers in this paper tackle this problem by using a large language model - a powerful AI system trained on a vast amount of text data to understand and generate human language. They start with a pre-trained language model and then continue training it on a dataset of real medical notes. This "continued pretraining" allows the model to gain expertise in the medical domain while building on the general language understanding it has already learned.
By fine-tuning the model in this way, the researchers are able to get it to generate high-quality, coherent medical notes that capture relevant details about a patient's case. This approach outperforms prior methods that didn't leverage the power of large language models.
Technical Explanation
The key contribution of this paper is a continued pretraining approach for using large language models (LLMs) to automate the generation of medical notes. The authors start with a pre-trained LLM, such as GPT-3, and then further fine-tune it on a dataset of real-world medical notes.
The dataset used for continued pretraining consists of over 1 million de-identified clinical notes from a major hospital system. The authors carefully preprocess this data to extract the relevant structured information (e.g. diagnoses, medications, procedures) that should be reflected in the generated notes.
They then fine-tune the pre-trained LLM on this medical note dataset using standard language modeling techniques. This allows the model to learn the specialized vocabulary, entities, and reasoning patterns needed to generate realistic and informative clinical documentation.
The authors evaluate their continued pretraining approach on several medical note generation benchmarks, including MIMIC-III and i2b2 2008. They find that their fine-tuned model outperforms prior state-of-the-art methods across a range of metrics measuring coherence, relevance, and factual consistency.
Critical Analysis
A key strength of this work is the use of continued pretraining to adapt a powerful general-purpose language model to the specialized domain of medical notes. By leveraging the broad language understanding of the pre-trained model, the authors are able to achieve strong performance without needing to train entirely from scratch.
However, the paper does acknowledge some important limitations. The generated notes, while an improvement over prior methods, still exhibit some factual errors or hallucinations of non-existent medical details. There is also the potential for bias in the training data to be reflected in the model's outputs.
Additionally, the authors note that their current approach treats the medical note as a monolithic block of text, without explicitly modeling the typical structure and sections of a real clinical note. Incorporating this structural information could lead to further improvements.
Overall, this work represents a promising step towards more capable and reliable medical note generation using large language models. But there remains significant room for refinement and continued research to address the remaining challenges in this important application domain.
Conclusion
This paper presents a continued pretraining approach for adapting large language models to the task of automatic medical note generation. By fine-tuning a pre-trained model on a dataset of real-world clinical documentation, the researchers are able to imbue the system with the specialized medical knowledge needed to generate coherent and relevant notes.
The results demonstrate the value of leveraging powerful general-purpose language models, rather than building everything from scratch. With further improvements to address remaining limitations around factual accuracy and structural modeling, this continued pretraining technique could have a significant impact in streamlining clinical documentation workflows and improving the consistency of medical record-keeping.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
0
0
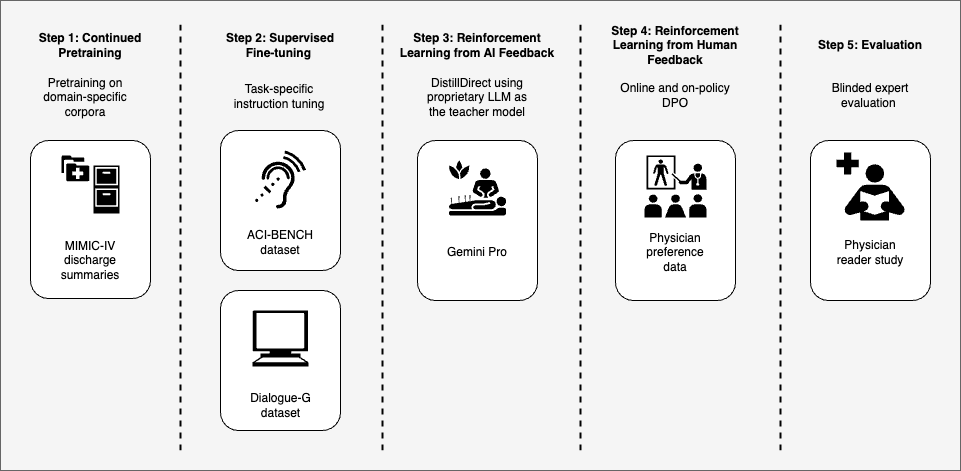
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
6/11/2024
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
0
0
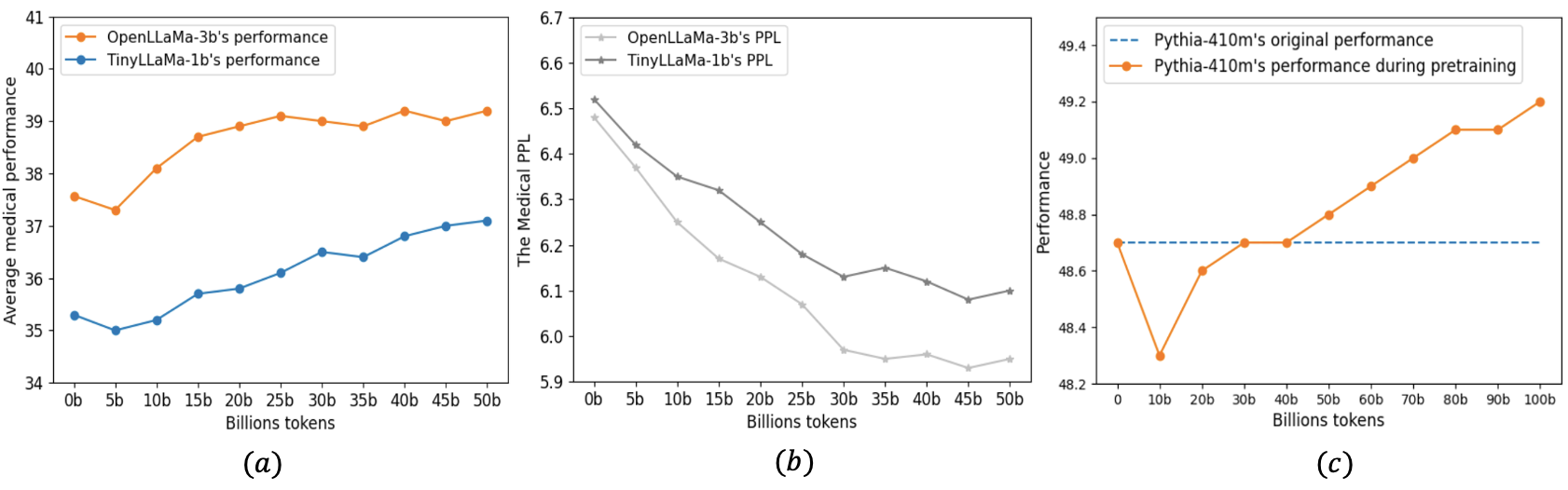
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
6/28/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
0
0
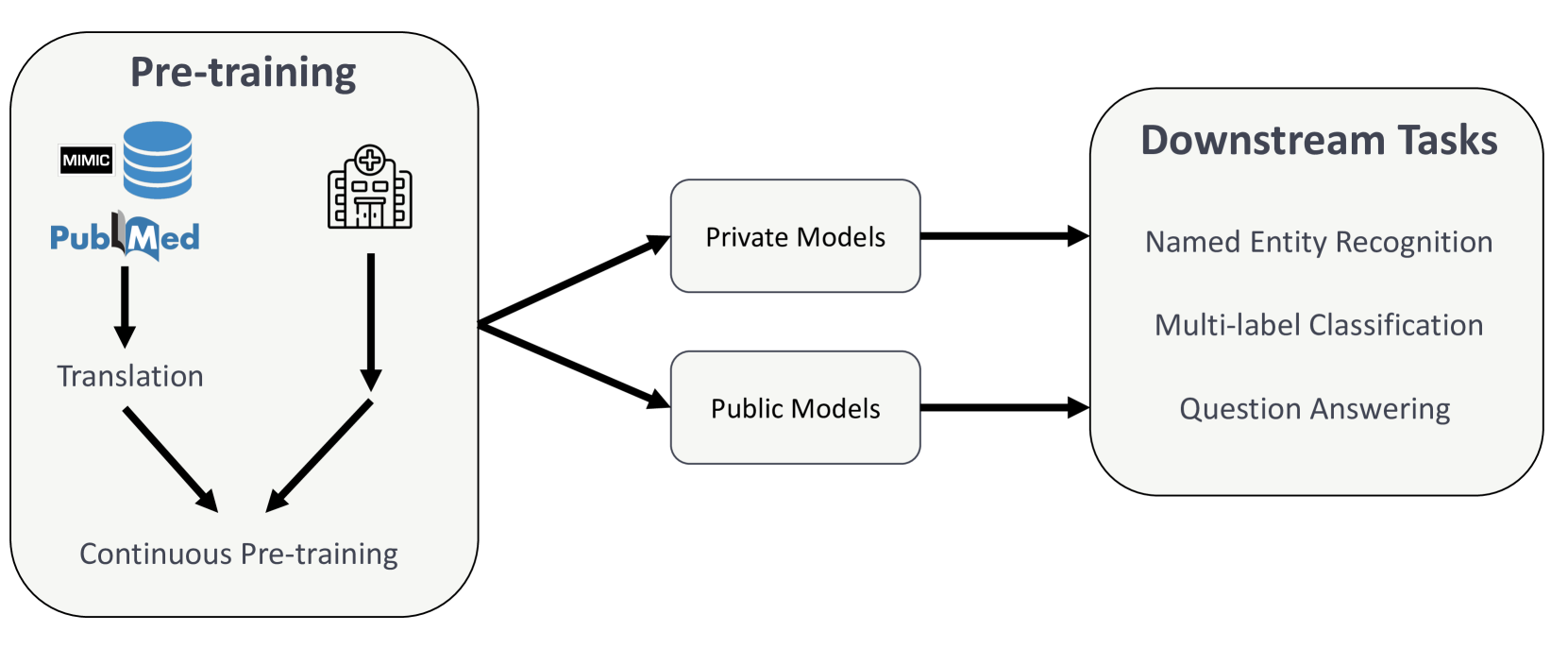
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
5/9/2024